

汽车的平均价格与汽缸数的关系。数据来源。加州大学欧文分校(使用条款)(图片由作者提供)
以及如何解释虚拟变量的回归系数
虚拟变量是一个二进制变量,取值为0或1。人们在回归模型中加入这样的变量,以代表那些具有二元性质的因素,即它们要么被观察到,要么没有被观察到。
在这个广泛的定义中,有几个有趣的用例。下面是其中的一些。
- 代表一个是/否的属性。表 示一个数据点是否具有某种属性。例如,一个虚拟变量可以用来表示一个汽车发动机是 "标准 "还是 "涡轮 "类型。或者一个药物试验的参与者是属于安慰剂组还是治疗组。
- 用于表示一个分类的值。假 人的一个相关用途是表示一个数据点属于一组分类值中的哪一个。例如,一辆车的车身样式可以是敞篷车、掀背车、双门车、轿车或货车中的一种。在这种情况下,我们会给数据集添加5个虚拟变量,5种车身风格各一个,我们会对这5个元素的虚拟变量向量进行 "热编码"。因此,向量[0, 1, 0, 0, 0]将代表数据集中的所有掀背车。
- 用于表示一个有序的分类值。使 用哑铃来表示分类数据的一个延伸是,类别是有序的。假设我们的汽车数据集包含有2、3、4、5、6、8或12缸发动机的汽车。在这里,我们还需要捕捉排序中包含的信息。我们将很快看到如何做到这一点。
- 对于代表一个季节性时期。 可以添加一个虚拟变量来代表数据中可能包含的许多季节性时期中的每一个。例如,通过十字路口的交通流量经常表现出每小时的季节性(它们在早晚高峰期最高),也表现出每周的季节性(周日最低)。在这两个季节性时期的数据中加入虚拟变量,就可以解释掉交通流量中因每日和每周变化而产生的大部分变化。
- 对于代表固定效应。在为面板数据集建立回归模型时,可以用虚拟变量来表示 "单位特定 "和 "时间特定 "的效应,特别是在固定效应回归模型中。
- 用于表示治疗效果。在治疗效果模型中,可以用一个虚拟变量来表示时间(即应用治疗之前和之后的效果)、小组成员的效果(参与者是接受治疗还是接受安慰剂)以及时间和小组成员之间的互动效果。
- 在回归不连续设计中。这最好用一个例子来解释。想象一下,有一个月度就业率数字的数据集,其中包含由短暂而严重的经济衰退引起的失业率的突然急剧上升。对于这个数据,用于建立失业率模型的回归模型可以部署一个虚拟变量来估计衰退对失业率的预期影响。
在这篇文章中,我们将解释如何在前三种情况下使用虚拟变量,即。
- 用于代表一个是/否的属性
- 代表一个分类值
- 用于表示一个有序的分类值
后面四种情况,即使用虚拟变量来对数据进行去季节性处理,表示固定效应和处理效应,以及对回归不连续进行建模,都值得单独写文章。
顺便提一下,这里涵盖了使用假数来表示固定效应的情况。
我们将在接下来的文章中介绍在建立治疗效果模型和为不连续的影响建模时使用假数的情况。
让我们深入了解第一个用例。
如何使用虚拟变量来表示是/否属性
我们将通过使用以下汽车数据集来说明这一过程,这些数据集包含了来自1985年版《沃德汽车年鉴》的200多辆汽车的规格。每一行都包含了一组关于一辆汽车的26个规格。
汽车数据集(来源:UC Irvine)
我们将考虑这个数据的一个子集,由以下七个变量组成。
*制造
灵感
车身风格
车架重量
汽缸数
发动机尺寸
价格
汽车数据集的一个7个变量子集。(来源:UC Irvine)
上述7个变量的版本可以下载 来自这里.
在上述数据集中,愿望变量的类型是标准或涡轮。我们的回归目标是估计吸气量对车辆价格的影响。为此,我们将引入一个虚拟变量来编码吸气,具体如下。
aspiration_std=1,当吸气量为标准时,否则为0。
我们将使用基于Python的Pandas库,将数据集作为一个Dataframe加载到内存中。然后我们将使用statsmodels库建立一个简单的线性回归模型,其中响应变量是价格,回归变量是aspiration_std(加上回归的截距)。
让我们从导入所有需要的包开始。
import
让我们把汽车数据集的7个变量子集导入一个DataFrame。
df = pd.
我们将添加虚拟变量列来表示愿望变量。
df_with_dummies = pd.
打印出虚拟增强的数据集。
print
我们看到下面的输出。我已经强调了Pandas添加的两个虚拟变量列。
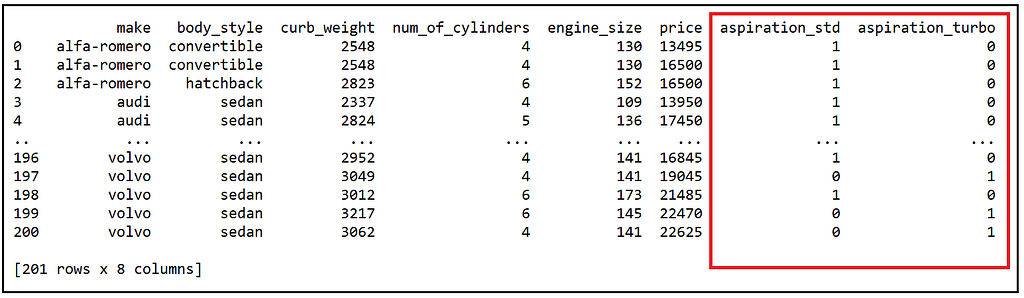
虚数增强的数据集(图片来自作者)
让我们来构建回归表达式。回归的截距会在以后由模型自动添加。
reg_exp =
请注意,我们只添加了一个虚拟变量aspiration_std,而不是同时添加aspiration_std和aspiration_turbo。 我们这样做是为了避免完美的共线性,因为数据集中的每台汽车发动机要么是涡轮增压类型,要么是标准类型。没有第三种类型。在这种情况下,回归的截距可以捕捉到吸气量*_涡轮增*压的影响。具体来说,训练后的模型中回归截距的估计值是所有涡轮增压型汽车的估计平均价格。
另外,我们可以同时加入aspiration_std和aspiration_turbo,而不考虑回归的截距。在后面这种情况下,由于模型没有回归截距,我们将不能用 R-squared值来判断其拟合度。
让我们在这个假数增强的数据集上建立普通最小二乘法回归模型。
olsr_model = smf.
尽管我们已经将整个7个变量的数据集传入这个模型,但在内部,statsmodels将使用回归表达式参数(reg_exp),只划分出感兴趣的列。
让我们来训练这个模型。
olsr_model_results = olsr_model.
让我们打印出训练总结。
print
我们看到下面的输出。我已经强调了我们将仔细检查的部分。
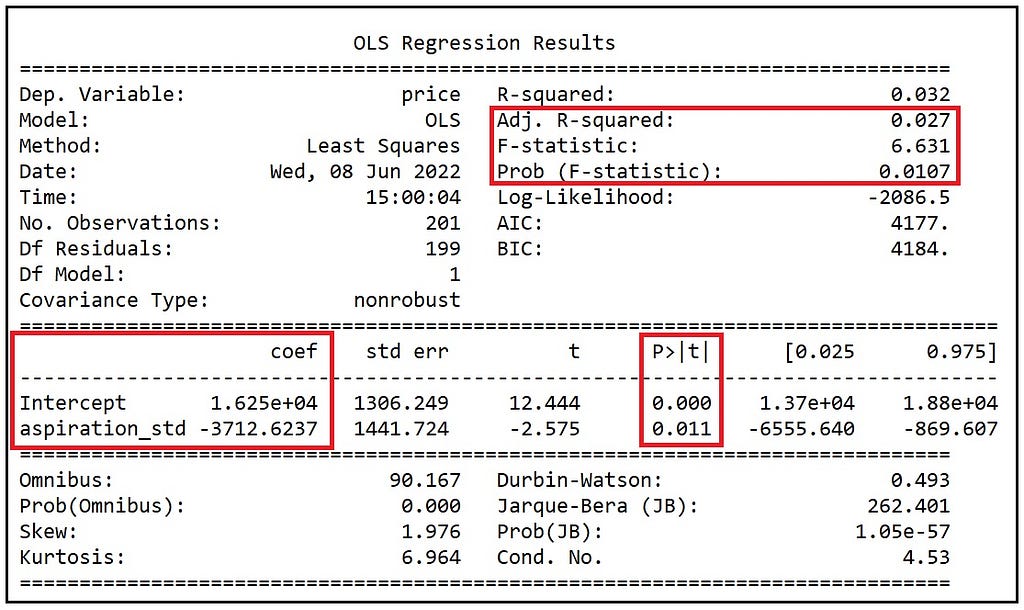
OLSR模型的训练总结(图片由作者提供)
如何解释模型的训练总结
我们注意到的第一件事是 调整后的R-squared是0.027。愿望 变量能够解释汽车价格变异的3%以下。这看起来非常小,但我们不需要对调整后的R-squared的低值作过多解读。请记住,我们的目标是要估计愿望对价格的影响。我们从不指望愿望本身能解释价格的大部分变异。此外,请注意 F-statistic的P值为0.0107,表明即使这个非常简单的线性模型也能比平均模型(基本上是通过价格平均值的平坦水平线)更好地适应数据。
接下来,我们注意到,模型的回归截距和aspiration_std的系数都具有统计学意义,即非零,P值分别小于0.001和在0.011。这是个好消息。让我们看看如何解释这些系数的数值。
如何解释回归模型中的虚拟变量的系数
回想一下,我们在模型中撇开了虚拟变量aspiration_turbo,以避免完全的勾稽关系。通过撇开aspiration_turbo,我们把储存涡轮机平均价格的工作交给了回归模型的截距。回归截距是16250,表明涡轮机的平均价格是16250美元。
我们需要参照截距的数值来解释模型中所有虚拟变量的系数。
在我们的案例中,只有一个虚拟变量,aspiration_std, 它的值是3712.62,而且是一个负号。这表明具有 "标准 "型吸气的汽车比具有 "涡轮 "型吸气的汽车平均价格低3712.62美元。涡轮机的估计平均价格是16250美元。因此,非涡轮车的估计平均价格是16250美元-3712.62美元=12537.38美元。
使用统计符号,我们可以把这两个平均值表示如下。
E(价格|激励='标准') = $12,537.38
这个估计值在平均值周围有以下95%的置信区间。
[6555.64 =16250 - 15,380.393**].
我们从模型训练输出的CI部分取值*-6555.64美元和-869.607美元*,如下所示。
对于涡轮机,期望值和CI值的计算方法如下。
E(价格|激励='涡轮增压') = 13700*,* $18800*].*
拟合模型的回归方程如下。
价格 = - 3.712.62* 灵感_std + 16250 + e
其中'e'包含回归的残余误差。
接下来,让我们看看如何使用虚拟变量来表示分类数据。
如何使用虚拟变量来表示分类回归变量
假设我们希望估计body_style对价格的影响*。Body_style是一个分类变量,有以下一组值。[敞篷车、硬顶车、掀背车、轿车、货车]。我们表示车身风格的总体策略将类似于表示愿望*的策略。因此,让我们直接进入实施阶段。我们将继续使用包含7个变量的汽车数据集的Pandas Dataframe。
让我们用虚拟变量列来增加DataFrame的内容,以表示body_style。
df_with_dummies = pd.
打印出虚拟增强后的数据集。
print(df_with_dummies)
我们看到下面的输出。
增强后的数据集(图片来自作者)。
注意新增加的虚拟变量列,每个body_style都有一个。
接下来,我们将用Patsy语法构建回归方程。和以前一样,我们将省去一个虚拟变量*(body_style_convertible*),以避免完美的勾稽关系。回归模型的截距将保持body_style_convertible的系数。
reg_exp =
让我们建立OLS回归模型。
olsr_model = smf.
让我们来训练这个模型。
olsr_model_results = olsr_model.
让我们打印出训练总结。
print
我们看到下面的输出。
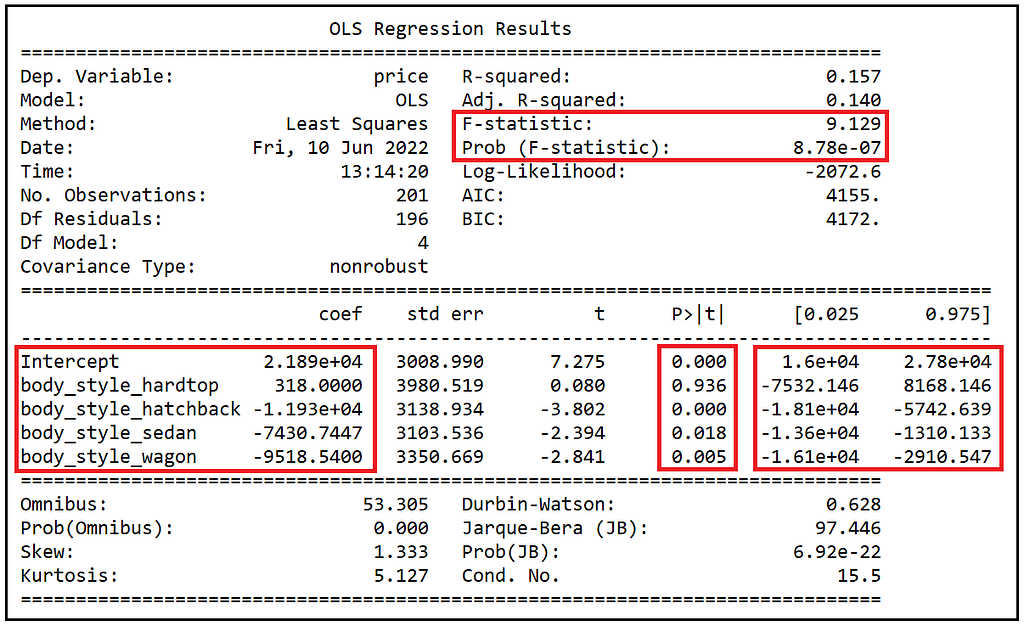
OLSR模型的训练总结 (图片来自作者)
和以前一样,我们不会关注调整后的R-squared。相反,让我们看一下F统计量,并注意到它在P值<.001时是显著的。它表明,无论R平方值如何,我们在模型中包含的变量已经能够比简单的平均模型更好地解释价格的差异。在完成了这一重要的尽职调查后,让我们来探讨一下所有变量的系数。
如何解释虚拟变量的系数
让我们把视线转向拟合模型的系数。估计的截距是21890。截距是估计的可转换债券的平均价格,因为那是我们从回归方程中放弃的虚拟变量。这个估计值在P<0.001时是显著的。这个估计值的95%CI是[16000美元,27800美元]。
硬顶车、掀背车、轿车和旅行车这四个特定风格的虚拟变量的系数代表了相应风格的平均值偏离估计的敞篷车平均价格的程度。
拟合模型估计硬顶车的平均偏差为318美元,但这个估计在统计上并不显著。事实上,在P=0.936时,它是非常不显著的。那么,我们应该如何解释这个系数呢?解释它的明显方法是假设它实际上是零。这意味着硬顶车的估计平均价格与敞篷车的估计平均价格相同,即21890美元。但这并没有完全描绘出完整的画面。318美元的估计值有一个巨大的标准误差,即3980.519美元。相应的95%CI大约是4倍大,从7532.146美元延伸到8168.146美元。你能从一个周围有这么大变化的平均值中得出任何实际用途吗?答案是否定的。差异非常大的分布的均值只能非常差地代表分布中的任何特定值。因此,与其说硬顶车的平均价格与敞篷车相同(这在技术上仍然是正确的),不如说在这个数据集中,硬顶车的属性没有能力解释汽车价格的任何差异。
另一方面,掀背车、轿车和旅行车风格的估计系数都具有统计学意义(事实上,它们是高度显著的),分别为p<0.001、0.018和0.005。掀背车的系数为-11930,表明掀背车的估计平均价格比敞篷车的估计平均价格低11930美元。因此,我们估计掀背车的平均价格为21890美元-11930美元=9960美元。这个估计值的95%CI是[21890-18100=3790美元,21890-5742.639=16147.361美元]。
同样,轿车的估计平均价格比敞篷车低7430.7447美元,而旅行车的估计平均价格比敞篷车低9518.54美元。
总之,我们的模型显示,平均而言,敞篷车是最昂贵的车辆,其次是轿车、旅行车和掀背车,在解释价格差异的能力方面,对硬顶风格没有任何有用的说法。
拟合模型的方程如下。
拟合的回归模型的方程(图片由作者提供)
如何使用虚拟变量来表示有序的分类值
我们要考虑的最后一个用例是,分类变量对其组成成分施加了某种秩序。再一次,我们将使用汽车数据来说明。具体来说,我们将把注意力转向变量num_of_cylinders。
汽车数据集的一个7个变量子集。(来源:加州大学欧文分校)
乍一看,num_of_cylinders可能是一个整数估值的变量。一个可能的回归模型,将价格回归到汽缸数上,如下所示。
一个将价格回归到汽缸数的天真回归模型(图片由作者提供)
这个模型有一个致命的缺陷,当我们把价格的预期值与汽缸数区分开来的时候,这个缺陷就会显现出来。
汽缸数每单位变化的汽车价格预期值的变化(图片由作者提供)。
我们看到,这个模型将为汽缸数的每一单位变化估计一个恒定的预期价格变化。该模型将估计2缸汽车和3缸汽车的平均价格差异与3缸和4缸汽车的差异完全相同,以此类推。在现实世界中,我们不会期望看到车辆价格有如此均匀的变化。
一个更现实的模型是将汽缸数作为一个分类变量,汽缸数的每个值由一个虚拟变量表示。
我们的数据集有2、3、4、5、6、8和12个气缸的车辆。因此,我们构建的模型如下。
一个线性模型,其中汽缸数被表示为一个分类虚拟变量(图片由作者提供)
我们省去了第2个气缸数的虚拟变量。截距β_0将捕获num_of_cylinders_2的系数。所有虚拟变量的系数将包含相应类别车辆的平均价格与2缸车辆的估计平均价格之间的估计偏差。95%的CI可以按照上面的说明计算。
让我们在汽车数据集上建立并拟合这个模型,并打印出训练总结。
#Add dummy variable columns to represent num_of_cylinders
olsr_model = smf.
olsr_model_results = olsr_model.
print
我们看到以下输出。

线性模型的训练总结 (图片由作者提供)
如何解释训练总结和虚拟变量的系数?
在总结中,首先映入眼帘的是0.618的大调整R方。汽缸数本身似乎有能力解释汽车价格的高达61.8%的变异。
像往常一样,我们将尽职尽责地检查F-statistic的p值(2.87E - 39显然小于0.001),表明模型中的所有回归变量都是共同高度显著的。
和以前一样,我们的重点仍然是估计的系数、它们的P值和95%的CI。
让我们从回归的截距开始。它的估计值是13020美元,这是估计的双缸汽车的平均价格。这个平均价格在统计上是显著的,P值为0.001,95%的CI为[8176.803美元,17900美元]。
3缸汽车的估计平均价格为13020美元-7869.0美元=5151美元,但这一估计在统计上只有0.153的意义。它没有通过95%、90%和85%的信心测试,但通过了80%的信心水平。
4缸汽车紧随3缸汽车之后,估计平均价格为13020-2716.8025=10303.1975美元。同样,在P为0.273的情况下,这个估计的意义只有在(1-0.273)100%=72.7%的信心水平下才有效。
5缸、6缸、8缸和12缸汽车的估计平均值都是非常显著的。8缸汽车似乎是最昂贵的汽车,其估计平均价格比2缸汽车高出25,880美元。
下图显示了平均价格与汽缸数的关系,以及平均值周围95%的下限和上限。
汽车的平均价格与汽缸数的关系(图片由作者提供)
我们看到,价格并不 因汽缸数的每一单位变化而发生恒定的变化 。这证明了我们先前的见解,即我们不应该把汽缸数作为一个简单的整数变量。
下面是拟合模型的方程。
拟合回归模型的方程(图片由作者提供)
以下是本文使用的完整源代码。
参考文献、引文和版权
数据集
汽车数据集 引用。D ua, D. and Graff, C. (2019).UCI机器学习资源库[archive.ics.uci.edu/ml\]。加州欧文市。… BY 4.0) 下载链接
如果你喜欢这篇文章,请关注我的网站 Sachin Date 来接收关于回归、时间序列分析和预测主题的提示、方法和编程建议。
什么是虚拟变量以及如何在回归模型中使用它们》最初发表在《走向数据科学》杂志上,人们通过强调和回应这个故事来继续对话。
