

在这篇文章中,我们将讨论支配模糊系统运作的一些基本概念。我们还将讨论它们在现实世界中的一些应用,同时将它们与Crisp(硬计算)系统进行比较和对比。
目录。
- 危机系统简介
- 模糊 "是什么意思?
- 模糊推理系统如何工作
- 结论
Crisp系统简介
在我们谈论模糊系统之前,我们有必要了解一下脆皮系统。脆皮系统(或传统的计算系统)遵循一套严格定义的规则,以得出答案。这些答案,假设所有的数学条件保持不变,将永远是相同的,无论计算是在何时何地进行的。换句话说,如果输入和处理条件保持不变,Crisp系统将始终产生相同的结果。他们不做近似的事情。它们只产生精确的结果,绝对不存在不准确或不精确的范围。然而,这也有其自身的局限性。
通常情况下,如果一个特定的问题非常复杂,创建一个数学模型来准确解决这个问题可能是一个巨大的挑战。即使我们设法创建这样一个模型,其复杂性也可能导致极长的计算时间(时间复杂性),并将导致内存管理方面的困难(空间复杂性),从而使我们使用Crisp系统来解决这种计算成本高的问题非常不现实。这就是为什么,即使危机系统在纸面上比模糊系统更好(因为危机系统每次都会产生准确的结果),但有些时候,我们允许这些小的不准确、不精确和近似,并使用模糊系统而不是危机系统,会更有意义。
人类的大脑非常善于执行任务,例如能够识别并将图像分类为 "X "或 "Y",但并不善于快速执行复杂的数学计算,例如寻找16,807的第五根。另一方面,计算机在快速执行这种复杂的数学计算方面历来非常出色,但在执行图像识别和分类等任务时却一直很吃力,而模糊系统正是要解决这一计算领域的问题。
模糊 "是什么意思?
在硬计算中,我们处理的是 "脆性集合",其中的元素要么属于某个特定集合,要么不属于。例如,假设我们有一个通用集A={1,2,3,4,5},和一个子集B={1,2,3}。现在,我们可以说元素1,2,3都属于子集B,其归属度相等(数值为1),而元素4和5不属于子集B(也就是说,它们的归属度等于0)。因此,如果我们用每个元素及其对集合的归属度来表示这个集合(作为有序对),我们可以把B写成:
B={(1,1), (2,1), (3,1), (4,0), (5,0)}
或者,换句话说,1、2和3属于B,而4和5不属于B。
术语 "模糊 "本质上意味着这些元素不一定完全属于或根本不属于,这与脆性集合不同。元素有可能部分地属于某个特定的集合,有不同程度的归属,而不仅仅是1或0。这一点很重要,因为在现实世界中,我们经常处理复杂的问题,不能简单地用二进制来解决。例如,如果我们问某人是否喜欢他们刚看的一部电影,他们很可能会给我们一个答案:"我有点喜欢"(接近0,比如0.3)或 "我很喜欢"(接近1,比如0.7),而不是只有 "是"(1)或 "不是"(0)。因此,我们可以说,在模糊集合中,集合中的每个成员都有一定程度的归属感。这个程度被称为成员度,而决定这个成员度的函数被称为成员函数。如果我们有一个普遍的集合A={1,2,3,4,5},那么子集B看起来就像:
B={(1,0.5), (2,0.3), (3,0.8), (4,0.7), (5,0.1)}
这意味着所有元素1、2、3、4和5部分都属于集合B,成员度不一。这种成员程度通常用字母 "μ "来表示。
模糊推理系统如何工作
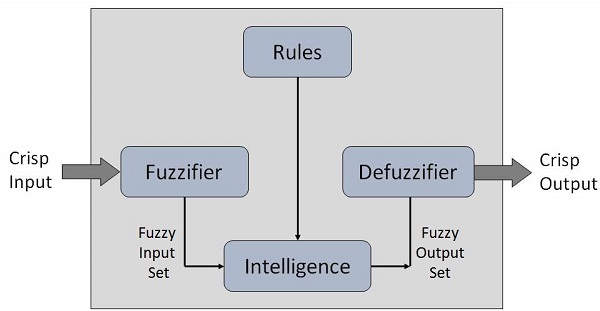
模糊系统是由一组被称为模糊规则的规则实现的,这些规则是在模糊集上定义的。非模糊系统有非常离散的处理规则的方式--一个规则要么完全启动,要么根本不启动,这取决于指定条件中的表达式是否为真。另一方面,在模糊系统中,条件在一定程度上是真,在一定程度上是假。真和假的程度决定了规则启动的程度。因此,每条规则都在一定程度上被启动。所有规则的输出被汇总以得到系统的最终输出。
简而言之,清晰的输入被应用于我们的模型。然后,这些清晰的输入被成员函数模糊化。然后在模糊化的数据上应用模糊规则。一旦模糊数据被处理,它就会被汇总,然后被去模糊化。最后,我们得到清晰的输出。我们将在未来的文章中仔细研究所有这些过程。
总结
在OpenGenus的这篇文章中,我们讨论了硬计算系统的一些特点和缺点,为什么我们需要允许一定程度的不确定性和不精确性,以及模糊系统背后的一些基本概念。在未来的文章中,我们将更深入地研究模糊系统,并讨论一些可以在模糊集和关系上进行的操作。我们还将学习模糊命题、模糊含义和模糊推论,这将使我们对如何应用本文所学的概念有一个完整的概念。
谢谢你的阅读!
