

这篇文章的目的是要阐明关于SQL Server统计的一些鲜为人知的要点。
简介
SQL Server统计数据是重要的数据库对象之一,因为它们是查询优化器的一个极其重要的输入。SQL Server统计数据存储了列值的分布,这些统计数据被优化器用来估计一个查询将返回多少行。基于这种估计,优化器决定查询计划的操作者,并执行其他必要的计算。简而言之,统计数据的准确性在生成一个有效的查询计划中起着关键作用。
SQL Server提供了三个主要的数据库级选项来自动维护统计数据。
自动创建统计数据
这个选项允许优化器为尚未有列值分布(直方图)数据的单列生成新的统计。这个操作的原因是,优化器希望提高查询计划的估计行数的准确性。
自动更新统计数据
这个选项允许优化器在数据修改达到一个阈值时触发更新统计操作,优化器决定更新统计操作。当阈值满足以下条件时,查询优化器就会触发更新统计操作。
- 表的行数从0行变成了0行以上的行数
- 表在上次抽样统计时有500行或更少,此后有超过500次的修改
- 当统计数字最后一次被更新时,表有超过500行,并且在统计数字最后一次被采样后,行的修改数超过了MIN(500 + (0.20 * n), SQRT(1,000 * n) )公式的结果。
自动异步更新统计数据
当我们启用这个功能时,优化器不会在查询执行过程中触发更新统计数据,它使用陈旧的统计数据。然而,统计数据将随后由SQL Server更新。
唯一索引和SQL Server统计
我们可以使用唯一索引来确保列数据的单一性。当通过等价("=")操作符在唯一索引列上搜索数据时,优化器不会利用SQL Server的统计数据。现在让我们通过一个非常简单的例子来发现这种情况。首先,我们将创建一个样本表并为col1列定义一个唯一索引。
CREATE TABLE TblTestUIndex
(Id INT PRIMARY KEY IDENTITY(1,1),Col1 VARCHAR(100),Col2 VARCHAR(100))
CREATE UNIQUE INDEX IX_TestIdex ON dbo.TblTestUIndex (Col1);
在这一步中,我们将只在表中插入一条记录,并执行一个选择查询,以便创建统计数据。
INSERT INTO TblTestUIndex VALUES('Col1','Col2')
GO
SELECT * FROM TblTestUIndex where Id > 1 and Col1 LIKE 'A%'
在执行select语句后,统计数据将被更新。这种情况可以用 dm_db_stats_properties视图。这个视图返回关于SQL Server统计的三个重要细节。
- last_updated指定统计数字最后更新的时间。
- modification_counter显示自上次统计更新以来的修改总数。这个数字不受回滚修改的影响。
- rows_samples显示的是为统计计算而采样的行的总数。
SELECT obj.name, obj.object_id, stat.name, stat.stats_id,
last_updated, modification_counter ,rows_sampled
FROM sys.objects AS obj
INNER JOIN sys.stats AS stat ON stat.object_id = obj.object_id
CROSS APPLY sys.dm_db_stats_properties(stat.object_id, stat.stats_id) AS sp
WHERE
obj.name = 'TblTestUIndex'

现在,我们将向样本表插入一些数据。
INSERT INTO TblTestUIndex
SELECT name,type_desc FROM sys.objects
GO

在这个操作之后,我们可以预期在任何读取请求之后,统计数据都会被更新,因为修改计数器超过了阈值。然而,下面的选择查询并没有触发统计量的更新过程。
SELECT * FROM TblTestUIndex WHERE Col1='sysclones' AND 1=(SELECT 1)
**提示:**1=(SELECT 1)表达式有助于摆脱琐碎的查询计划,因为它们会阻止更新统计数据。
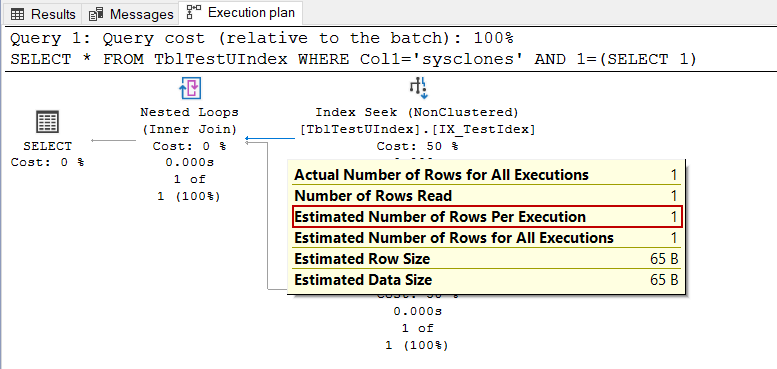
 正如我们前面提到的,在一个唯一索引列中的平等条件搜索最多可以返回一条记录。对于这种类型的谓词,优化器不需要使用统计数据,因为估计结果是恒定的。
正如我们前面提到的,在一个唯一索引列中的平等条件搜索最多可以返回一条记录。对于这种类型的谓词,优化器不需要使用统计数据,因为估计结果是恒定的。
估计的执行计划和SQL Server统计
执行计划是用来分析和诊断查询性能的,因为执行计划描述了查询的编译和执行步骤的所有细节。SQL Server提供两种类型的执行计划。
- 估计的执行计划是在不执行查询的情况下产生的。
- 实际执行计划是在执行查询后产生的。
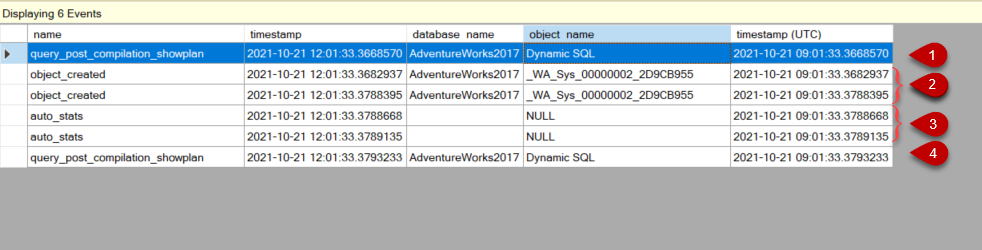
在特定情况下,我们可能需要分析一个估计的查询计划,但在估计计划的生成过程中,它可能会在幕后触发统计的创建。现在,我们将通过一个例子来说明这种情况。首先,我们将创建一个扩展的事件,以监测在创建估计的执行计划时发生哪些活动。这个事件会话将涉及以下事件。
- object_created发生在使用CREATE语句创建一个新对象时
- query_post_compilation_showplan发生在一个SQL语句被编译的时候
- auto_stats发生在优化器加载统计数据的时候。
在以下查询的帮助下,我们将创建这个扩展事件会话。我们需要强调关于这个事件会话的一点,我们对session-id字段应用一个过滤器,这样我们就可以排除捕捉其他不相关的活动。
CREATE EVENT SESSION EstimatedExecutionPlan ON SERVER
ADD EVENT sqlserver.object_created(SET collect_database_name=(1)
ACTION(sqlserver.sql_text)
WHERE ([sqlserver].[session_id]=(127))),
ADD EVENT sqlserver.query_post_compilation_showplan(SET collect_database_name=(1)
ACTION(sqlserver.sql_text)
WHERE ([sqlserver].[session_id]=(172))),
ADD EVENT sqlserver.uncached_sql_batch_statistics(
ACTION(sqlserver.sql_text)
WHERE ([sqlserver].[session_id]=(127)))
WITH (STARTUP_STATE=OFF)
GO
ALTER EVENT SESSION EstimatedExecutionPlan ON SERVER STATE = START
在创建了事件会话后,我们创建了一个新的样本表,并为其填充一些数据。
CREATE TABLE TestTableStat (Id INT IDENTITY(1,1) ,Col1 VARCHAR(100),Col2 VARCHAR(100))
GO
INSERT INTO TestTableStat
SELECT name,type_desc FROM sys.objects
GO
现在我们将启动事件会话,然后我们启动观察实时数据屏幕,以实时查看捕获的事件数据。作为最后一步,我们点击以下查询的显示已执行的执行计划。
扩展事件已经捕获了一些与此操作相关的事件。现在让我们来解释一下这些事件表示什么。
第一个事件表示初始编译的查询计划,这个查询计划没有使用任何统计数据。当我们点击查询计划时,我们可以看到这个查询计划。
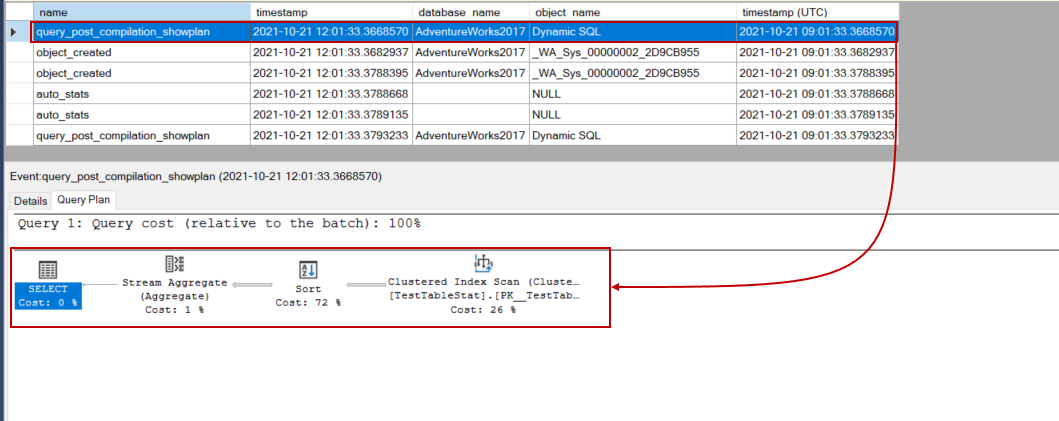
object_created事件显示了创建的统计细节。
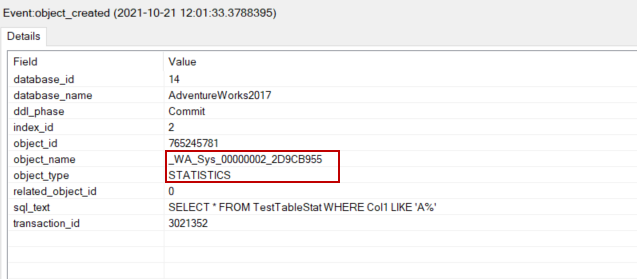
auto_stats事件表明统计资料被优化器加载以生成一个高效的查询计划。
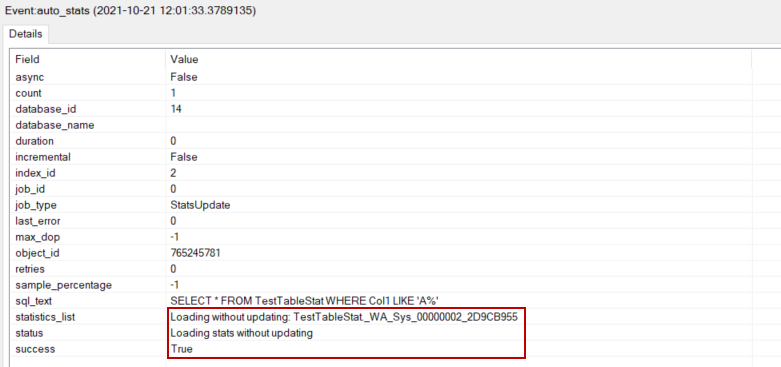
在最后的过程中,优化器使用新创建的SQL Server统计数据生成一个新的查询计划。在这个计划中,由于新创建的统计数据,估计的行数比最初的查询计划更准确。
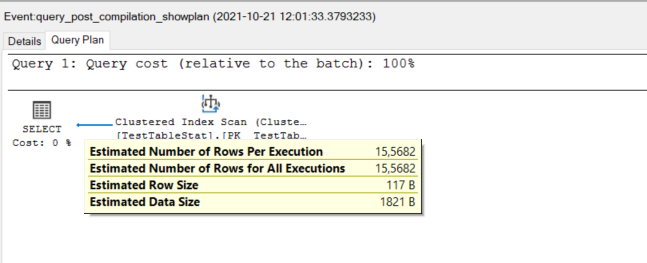
SQL服务器统计数据和ROLLBACK
ROLLBACK语句用于恢复在事务中所作的改变,这样所有改变的数据就会恢复到事务状态之前的样子。然而,change_counter不受这些回滚的影响,这种回滚可能会造成多余的查询重新编译。让我们用一个非常简单的例子来证明这种情况。
CREATE TABLE TestTableRollBack (Id INT IDENTITY(1,1) PRIMARY KEY ,Col1 VARCHAR(100),Col2 VARCHAR(100))
GO
INSERT INTO TestTableRollBack VALUES ('Col1','Col2')
第2步: 我们创建一个存储过程并执行它。在执行存储过程后,SQL服务器的统计数据将被更新。
CREATE PROC UProc_RollBack
@Param1 AS VARCHAR(100)
AS
SELECT * FROM TestTableRollBack WHERE Col1 LIKE @Param1 + '%'
AND 1=(SELECT 1)
AND Id>1
GO
EXECUTE UProc_RollBack @Param1 ='K'

第3步:在这一步中,我们将在表中插入一些行,然后通过ROLLBACK命令撤销这些修改。然而,这种情况会增加统计数据的modification_counter值。
BEGIN TRAN
INSERT INTO TestTableRollBack
SELECT s1.name,s2.type_desc FROM sys.objects s1,sys.objects s2
ROLLBACK TRAN

第4步:我们将创建一个扩展的事件会话,当我们再次执行示例存储过程时,它有助于监控活动。
CREATE EVENT SESSION CaptureStoredProcedure ON SERVER
ADD EVENT sqlserver.auto_stats(SET collect_database_name=(1)
WHERE ([package0].[equal_uint64]([database_id],(14)))),
ADD EVENT sqlserver.sp_cache_hit(
WHERE ([object_id]=(1581248688))),
ADD EVENT sqlserver.sp_cache_insert(SET collect_cached_text=(1),collect_database_name=(1)
WHERE ([database_id]=(14))),
ADD EVENT sqlserver.sp_statement_completed(SET collect_object_name=(1)
WHERE ([package0].[equal_uint64]([source_database_id],(14)))),
ADD EVENT sqlserver.sp_statement_starting(SET collect_object_name=(1)
WHERE ([package0].[equal_uint64]([source_database_id],(14)))),
ADD EVENT sqlserver.sql_statement_recompile(SET collect_object_name=(1),collect_statement=(1)
WHERE ([package0].[equal_uint64]([source_database_id],(14))))
WITH (STARTUP_STATE=OFF)
GO
第5步:启动扩展事件会话
ALTER EVENT SESSION CaptureStoredProcedure ON SERVER STATE = START
第6步:打开事件会话的 "观察实时数据 "界面。
第7步:在这最后一步中,我们用相同的参数执行我们的样本存储过程,我们发现在执行过程中背后发生了什么。
EXECUTE UProc_RollBack @Param1 ='K'

我们可以将捕获的事件分成3个部分,然后对它们进行解释。在第一部分中,优化器找到了一个缓存的程序计划,并决定使用它,但随后发现统计数据已经过期。在这一点上,优化器开始重新编译存储过程,因为统计数据在变化。第二部分规定了哪些统计数据被更新。在最后一步,存储过程开始执行并成功完成。
总结
SQL Server的统计数据是优化器生成更有效的查询计划的关键对象。在这篇文章中,我们深入研究了统计的一些鲜为人知的要点,并探讨了在幕后发生的哪些活动。
