

用Sklearn的ColumnTransformer创建极其个性化和有组织的预处理管道

照片:Simon KadulaonUnsplash
简介
数据预处理可能是机器学习/数据科学管道中最耗时的步骤之一。
在大多数现实场景中,可用的原始数据是没有格式化的、肮脏的,对机器学习模型/数据分析来说是不恰当的,需要几个步骤的清洗 和特征工程。
在结构化数据(表)的背景下,开发者需要处理各种问题,如缺失值、反规范化数据、未格式化的字符串、重复的行等。
他们还需要通过规范化数字特征、嵌入分类特征、创建更有意义的列,以及其他许多步骤来提高ML模型的性能或改善仪表盘的质量来改善数据的表示。
这种对数据框架实施特定规则的需求很容易导致意大利面条 代码的产生,这很难维护和更新,而且容易出错。

数据预处理。图片由作者提供。图标由Freepik提供。
Sklearn的管道与ColumnTransformer是以标准方式应用转换规则的一个简单方法,创造了一个更有组织和干净的代码。
了解ColumnTransformer
如果你已经熟悉了sklearn的ColumnTransformer模块,你可以跳过本节。
在处理表格数据时,在不同的数据列上执行几个清洗步骤是很常见的。
例如,一个数字特征 "价格 "可能需要一个操作,用数据平均值替换NULL值。你可能已经知道,Sklearn提供了一个转化器来做这个,即SimpleImputer。
ColumnTransformer所允许的是只在一组列中应用Sklearn的变换器 。

了解ColumnTransformer。图片由作者提供。图标由Freepik提供。
让我们看看这在代码上是如何工作的。
ColumnTransformer对象接收一个图元的列表,由转化器名称(这是你的选择)、转化器本身和要应用转化的列组成。余下的参数指定了需要对所有其他列做什么。
下面的图片显示了代码的输出。
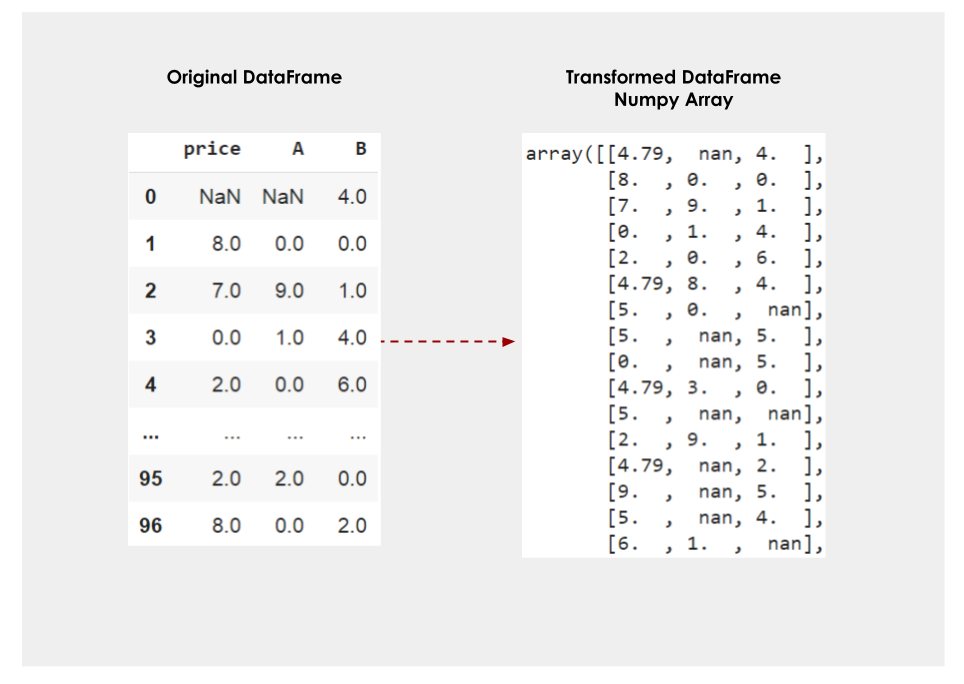
DataFrame的列转换(1)。图片由作者提供。
替换操作只发生在指定的列中,而其余的则保持不动(由remainder="passthrough "指定)。pandas DataFrame也被替换为Numpy数组,因为这是Sklearn转化器的默认行为。
让我们来看看一个更复杂的例子。
在上面的例子中,"Price "列的空值被替换为平均值,"A "列的空值被替换为中位数,所有其他列的空值被替换为数值-1。 下面的图片显示了这个结果。
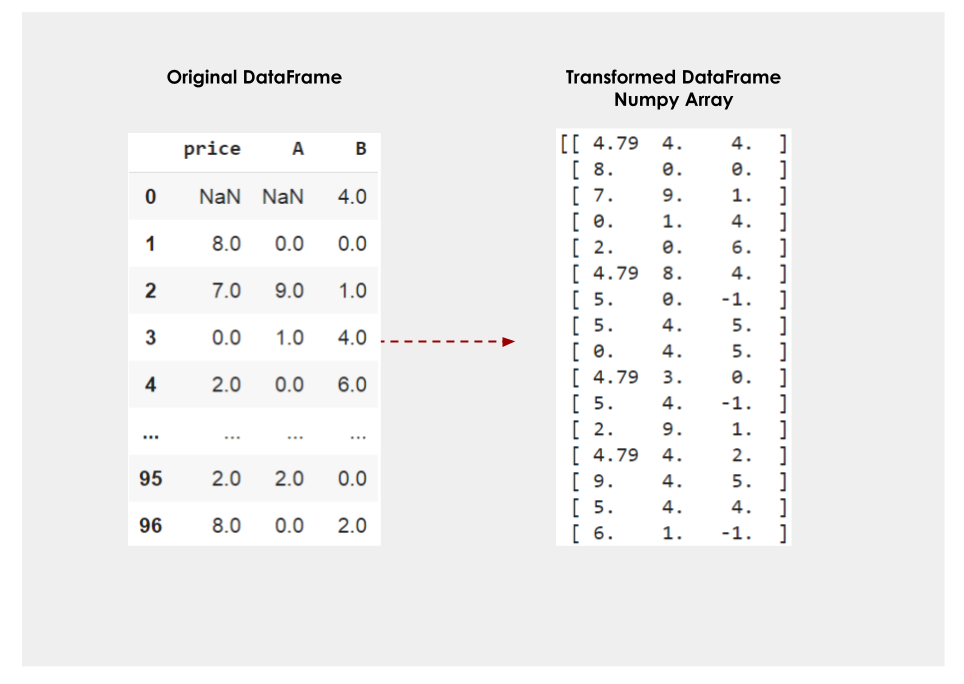
数据框架列转换(2)。图片由作者提供。
提示:如果你在Jupyter笔记本上工作,通过在Sklearn的配置中设置display="diagram",就可以很容易地在交互式图表中显示估算器。
下面的代码做了这个配置,图片显示了前面例子的可视化。
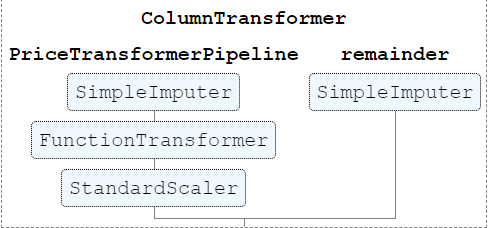
希望你已经了解了ColumnTransformer类的力量。它是一种对许多列进行转换的简单方法,所有的逻辑都被封装在一个单一的对象中。
在管道中使用ColumnTransformers
ColumnTransformer是非常有用的,但它还不够。在许多情况下,一个列需要在多个步骤中进行处理。
例如,数字特征 "价格 "可能需要一个操作,用数据平均值替换NULL值,进行对数转换以使数据分布更对称,并进行标准化处理以使其值更接近于区间[-1, 1]。
不幸的是,在sklearn中没有转化器来完成所有这些工作,这就是管道 的作用。
通过管道,我们可以将多个转化器连接起来,创建一个复杂的过程。因为管道对象相当于一个简单的变换器(例如,它有相同的*.fit()和.transform(*)方法),它可以被插入到ColumnTransformer对象中。
你也可以把ColumnTransformer放在Pipeline里面,因为它也是一个简单的变换器对象,而且这个循环可以根据你的需要进行下去。
这是Sklearn架构的优点之一。所有的转化器模块共享相同的接口,所以它们可以很容易地一起工作。
让我们看看这在代码上是如何工作的。
管道对象有一个相当直观的界面。它接受一个图元的列表,每个图元代表一个转化器,有一个你选择的名称和转化器对象本身。它按照指定的顺序应用这些转换。
下面的图片显示了之前创建的变换器。

带有管道的列变换器。图片由作者提供。
在一个例子上工作
让我们通过为Sklearn网站上的葡萄酒分类数据集制作分类器管道,来快速探索这项技术在 "真实案例 "中的作用。
这个数据集包含13个关于葡萄酒化学特性的数字特征,它们被分为3个类别。下面的代码导入了该数据。
通过绘制特征分布图,我们可以选择每个特征需要的处理方式。

特征的分布。图片由作者提供。
让我们假设选择以下处理方法。
- 苹果酸:最小-最大 缩放比例
- 镁:对数 转换,将数值离散为4档
- 灰分:下降特征
- Nonflavanoid_phenols:无
- 任何其他:标准缩放器
之后,数据需要通过PCA来降低维度,然后到达RandomForestClassifier。
下面的代码显示了如何建立这个管道。
而这个管道看起来是这样的。

然后我们可以把这个对象作为一个普通的分类器。
这个练习的主要目的是表明,可以将所有这些复杂的逻辑封装到一个单一的对象(估算器)中。最终的对象与所有其他sklearn模块兼容,这可以使生活更容易。
例如,它可以执行网格搜索,改变从预处理步骤到分类器本身的超参数。由于sklearn的架构,创建新的模块(转化器、分类器、回归器等)非常容易,所以,如果你需要一个非常具体的任务,很容易创建一个新的类,并使其与管道兼容。估算器的架构也很容易序列化,所以它可以以各种格式存储,如JSON和XML。
最后,代码是干净和标准化的,这使得它更容易更新和维护。
结论
预处理数据是任何数据科学过程中的一个关键步骤。然而,当每个数据集的特殊性出现时,预处理步骤会变得非常复杂,并充满了特定的领域规则。
在这种情况下,在一个单一的对象中维护所有的转换可能是非常有用的,因为一个单一的实例可以很容易地被移动、存储和更新。
这篇文章探讨了Sklearn列变换器类如何通过将所有的预处理逻辑封装在一个地方,同时在对象之间保持高标准化程度,来提高代码质量和组织。
尽管这篇文章特别探讨了ColumnTransformer类,但其逻辑也延伸到了其他sklearn模块,因为这篇文章的主要目标是展示如何做出一个更健壮的代码。Sklearn的架构是非常有条理的,了解更多的高级功能可以使你的生活更轻松。所以,我希望这篇短文对你有帮助。
谢谢你的阅读!:)
参考文献
[1] Scikit-Learn,ColumnTransformer的官方文档
[2] Scikit-Learn,Pipelines的官方文档
[3] Géron, A. (2019).Hands-on machine learning with Scikit-Learn, Keras, and TensorFlow: Concepts, tools, and techniques to build intelligent systems." O'Reilly Media, Inc."。
用ColumnTransformer和管道改善你的数据预处理》最初发表在《Towards Data Science》杂志上,人们通过强调和回应这个故事继续对话。
