本文已参与「新人创作礼」活动,一起开启掘金创作之路。
4. Encoder-Decoder模型
由前面的章节我们知道,Encoder-Decoder模型就是输入输出长度为一般情况的RNN模型,示意图如下:
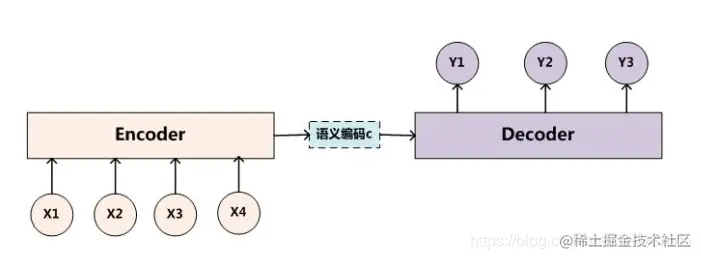
图4.1 Encoder-Decoder
其中Encoder负责将输入进行编码,得到语义编码向量C;Decoder负责将语义编码向量C进行解码,得到输出。以机器翻译为例,英文作为输入,输出为中文。可以用如下的数学模型来表示:
inputCyioutput=(x1,x2,⋯,xn)=f(input)=g(C,y1,y2,⋯,yi−1),i=1,2,⋯,m=(y1,y2,⋯,ym)(4-1)
从Encoder得到C的方式有多种,可以将Encoder最后一个时刻的隐藏状态作为C,也可以将所有的隐藏状态进行某种变换得到C。
语义编码C在Decoder中的作用当时有多种,常见的有如下两种
(1) C作为Decoder的初始状态h0。
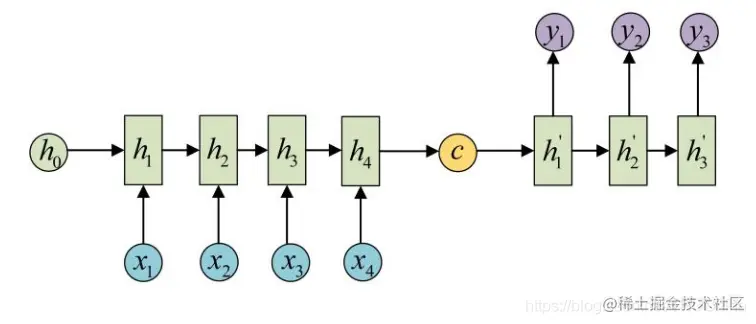
图4.2 C作为Decoder的初始状态h0
(2) C作为Decoder的每一步输入。
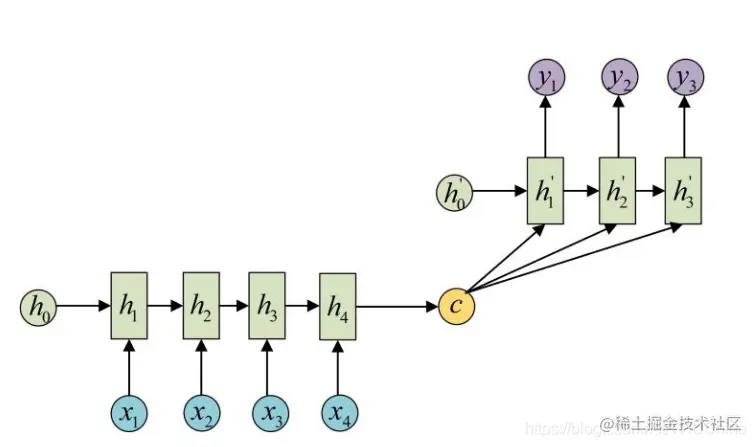
图4.2 C作为Decoder的每一步输入
4.1. 几种典型的encoder-decoder
4.1.1. 第一种:语义编码C作为Decoder的初始输入
本小节的encode-decoder模型可以看成是seq2seq的开山之作,来源于google的论文arxiv.org/abs/1409.32… Sequence to Sequence Learning with Neural Networks。该论文的模型是为了翻译问题而提出的,其中的encoder和decoder都采用LSTM,decoder中采用了beam search来提升效果。此外,该论文还采用了一个tric——将输入源句子倒序输入。这是因为,无论RNN还是LSTM,其实都是有偏的,即顺序越靠后的单词最终占据的信息量越大。如果源句子是正序的话,则采用的是最后一个词对应的state来作为decoder的输入来预测第一个词。这样是是不符合直觉的,因为没有对齐。将源句子倒序后,某种意义上实现了一定的对齐。
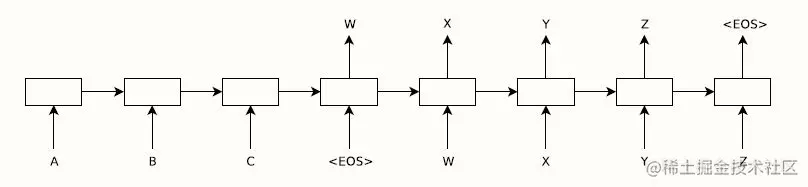
图4.3 Encoder-Decoder框架1-C作为Decoder的初始输入
Encoder:
htc=tanh(W[ht−1,xt]+b)=hT(4-2)
Decoder:
htot=tanh(W[ht−1,yt−1]+b),h0=c=softmax(Vht+d)(4-3)
4.1.2. 第一种:语义编码C作为Decoder的每一步输入
arxiv.org/pdf/1406.10… Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
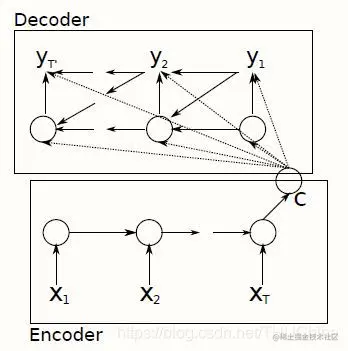
图4.4 Encoder-Decoder框架2-C作为Decoder的每一步输入
Encoder:
htc=tanh(W[ht−1,xt]+b)=(VhT)(4-4)
Decoder:
htot=tanh(W[ht−1,yt−1,c]+b)=softmax(Vht+c)(4-5)
4.2. Encoder-Decoder的缺点
- 对于输入序列的每个分量的重要程度没有区分,这和人的思考过程是不相符的,例如人在翻译的时候,对于某个一词多义的词,可能会结合上下文中某些关键词进行辅助判断。
- 如果在Decoder阶段,仅仅将C作为初始状态,随着时间往后推进,C的作用会越来越微弱。
事实上,Attention机制的提出,主要就是为了解决上述问题。


