

带你认识存储 & 数据库 | 青训营笔记
这是我参与「第三届青训营 -后端场」笔记创作活动的的第16篇笔记
01 经典案例
数据流动
用户 → 后端服务器 → 数据库 → 存储系统或非存储系统
数据持久化
- 校验数据的合法性
- 修改内存
- 写入存储介质
02 存储&数据库简介
2.1 存储系统
-
什么是存储系统 :一个提供了读写、控制类接口,能够安全有效地把数据持久化的软件,就可以称为存储系统
-
系统特点
- 作为后端软件的底座,性能敏感
- 存储系统软件架构,容易受硬件影响
- 存储系统代码,既“简单”又“复杂”
-
数据怎么从应用到存储介质
- 「缓存」很重要,贯穿整个存储体系
- 「拷贝」很昂贵,应该尽量减少
- 硬件设备五花八门,需要有抽象统一的接入层
-
RAID技术
-
RAID出现的背景:
- 单块大容量磁盘的价格 > 多块小容量磁盘
- 单块磁盘的写入性能 < 多块磁盘的并发写入性能
- 单块磁盘的容错能力有限,不够安全
-
RAID 0
- 多块磁盘简单组合
- 数据条带化存储,提高磁盘带宽
- 没有额外的容错设计
-
RAID 1
- 一块磁盘对应一块额外镜像盘
- 真实空间利用率仅50%
- 容错能力强
-
RAID 0+1
- 结合了RAID0和RAID1
- 真实空间利用率仅50%
- 容错能力强,写入带宽好
-
2.2 数据库
关系是什么?
- 关系=集合=任意元素组成的若干有序偶对反应了事物间的关系
- 关系代数=对关系作运算的抽象查询语言交、并、笛卡尔积….
- SQL = -种DSL =方便人类阅读的关系代数表达形式
关系型数据库特点
关系型数据库是存储系统,但是在存储之外,又发展出其他能力
- 结构化数据友好
- 支持事务
- 支持复杂查询语言 (SQL)
非关系型数据库特点
- 半结构化数据友好
- 可能支持事务(ACID)
- 可能支持复杂查询语言
2.3 数据库 vs 经典存储
-
结构化数据库管理
-
事务能力 : 凸显出数据库支持「事务」的优越性
- A(tomicity),事务内的操作要么全做,要么不做
- C(onsistency),事务执行前后,数据状态是一致的
- I(solation),可以隔离多个并发事务,避免影响
- D(urability),事务一旦提交成功,数据保证持久性
-
复杂的查询能力
03 主流产品剖析
3.1单机存储
单机存储 = 单个计算机节点上的存储软件系统,一般不涉及网络交互
-
本地文件系统
-
Linux经典哲学:一切皆文件
-
文件系统的管理单元:文件
-
文件系统接口:文件系统繁多,如
Ext2/3/4,sysfs,rootfs等, 但都遵循VFS的统一抽象接口 -
Linux文件系统的两大数据结构:
Index Node&Directory Entry -
Index Node
- 记录文件元数据,如id、 大小、权限、磁盘位置等
inode是一个文件的唯一标识, 会被存储到磁盘上inode的总数在格式化文件系统时就固定了
-
Directory Entry
- 记录文件名、
inode指针,层级关系(parent)等 dentry是内存结构,与inode的关 系是N:1(hardlink的实现)
- 记录文件名、
-
-
key - value 存储
- 常见使用方式:
put(k, v)&get(k) - 常见数据结构:
LSM-Tree,某种程度上牺牲读性能,追求写入性能 - 拳头产品:
RocksDB
- 常见使用方式:
3.2分布式存储
分布式存储 = 在单机存储基础上实现了分布式协议,涉及大量网络交互
-
分布式文件存储系统 HDFS
-
HDFS :堪称大数据时代的基石
-
时代背景:专用的高级硬件很贵,同时数据存量很大,要求超高吞吐
-
HDFS核心特点
- 支持海量数据存储
- 高容错性
- 弱POSIX语义
- 使用普通x86服务器,性价比高
-
-
Ceph
-
Ceph :开源分布式存储系统里的「 万金油」
-
Ceph的核心特点:
- 一套系统支持对象接口、块接口、文件接口,但是一切皆对象
- 数据写入采用主备复制模型
- 数据分布模型采用CRUSH算法(HASH + 权重 + 随机抽签)
-
3.3单机关系型数据库
单机数据库 = 单个计算机节点上的数据库系统 事务在单机内执行,也可能通过网络交互实现分布式事务
-
关系型数据库
-
商业产品
Oracle称王,开源产品MySQL&PostgreSQL称霸 -
关系型数据库的通用组件:
Query Engine一一负责 解析query,生成查询计划Txn Manager一一负责事务并发管理Lock Manager一一负责锁相关的策略Storage Engine一一负责组织内存/磁盘数据结构Replication一一负责主备同步
-
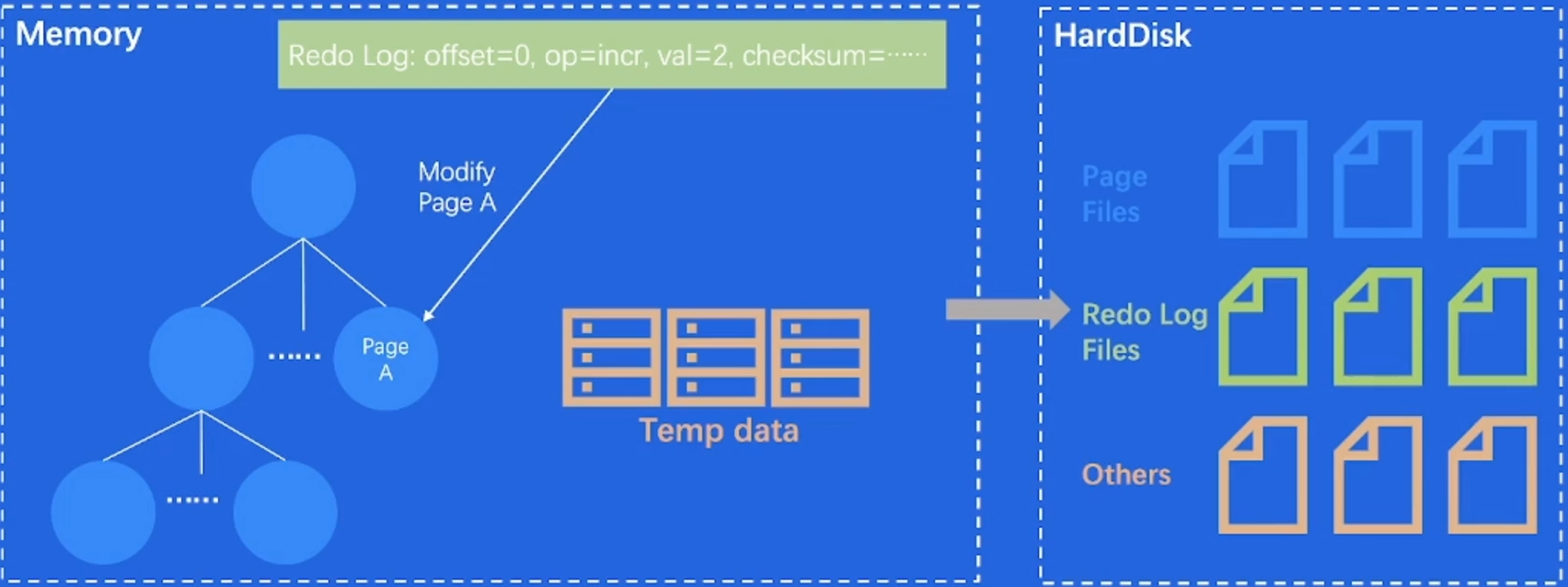
关键内存数据结构:
B-Tree、B+-Tree、LRU List等 -
关键磁盘数据结构:
WriteAheadLog (RedoLog)、Page -
-
3.4单机非关系型数据库
非关系型数据库
-
MongoDB、Redis、Elasticsearch三足鼎立- 关系型数据库一般直接使用SQL交互,而非关系型数据库交互方式各不相同
- 非关系型数据库的数据结构千奇百怪,没有关系约束后,schema相对灵活
- 不管是否关系型数据库,大家都在尝试支持SQL(子集)和“事务”
-
Elasticsearch- 面向「文档」存储
- 文档可序列化成JSON,支持嵌套
- 存在「index」 ,index= 文档的集合
- 存储和构建索引能力依赖
Lucene引擎 - 实现了大量搜索数据结构&算法
- 支持RESTFUL API,也支持弱SQL交互
-
MongoDB- 面向「文档」存储
- 文档可序列化成JSON/BSON,支持嵌套
- 存在「collection」, collection = 文档的集合 存储和构建索引能力依赖
wiredTiger引擎 - 4.0后开始支持事务(多文档、跨分片多文档等)
- 常用client/SDK交互,可通过插件转译支持弱SQL
-
Redis- 数据结构丰富(
hash表、set、zset、list) - C语言实现,超高性能
- 主要基于内存,但支持
AOF/RDB持久化 - 常用
redis-cli/多语言SDK交互
- 数据结构丰富(
3.5分布式数据库
单机数据库遇到了哪些问题&挑战,需要我们引入分布式架构来解决?
-
容量 弹性 性价比
- 单点容量有限,受硬件限制 ×
- 存储节点池化,动态扩缩容 √
-
MORE TO DO
- 单写 vs 多写
- 从磁盘弹性到内存弹性
- 分布式事务优化
04 新技术演进
-
概览
-
软件架构变更
- Bypass OS kernel
-
AI增强
- 智能存储格式转换
-
新硬件革命
- 存储介质变更
- 计算单元变更
- 网络硬件变更
-
-
SPDK
- Bypass OS kernel 已经成为一种趋势

-
AI & Storage
- AI领域相关技术, 如Machine Learning在很多领域:如推荐、风控、视觉领域证明了有效性
-
高性能硬件
-
01.RDMA网络
- 传统的网络协议栈,需要基于多层网络协议处理数据包,存在用户态&内核态的切换,足够通用但性能不是最佳
- RDMA是kernel bypass的流派,不经过传统的网络协议栈,可以把用户态虚拟内存映射给网卡,减少拷贝开销,减少cpu开销
-
-
Persistent Memory
-
在NVMe SSD和Main Memory间有一种全新的存储产品: Persistent Memory
- IO时延介于SSD和Memory之间,约百纳秒量级
- 可以用作易失性内存(memory mode)也可以用作持久化介质(app- direct)
-
-
03.可编程交换机
- P4 Switch, 配有编译器、计算单元、DRAM,可以在交换机层对网络包做计算逻辑。在数据库场景下,可以实现缓存-致性协议等
-
04.CPU/GPU/DPU
- CPU :从multi-core走向many-core
- GPU:强大的算力&越来越大的显存空间
- DPU:异构计算,减轻CPU的workload
-
总结
存储系统
- 块存储:存储软件栈里的底层系统,接口过于朴素
- 文件存储:日常使用最广泛的存储系统,接口十分友好,实现五花八门
- 对象存储:公有云上的王牌产品,immutable语 义加持
- key-value存储: 形式最灵活,存在大量的开源/黑盒产品
数据库系统
- 关系型数据库:基于关系和关系代数构建的,-般支持事务和SQL访问,使用体验友好的存储产品
- 非关系型数据库:结构灵活,访问方式灵活,针对不同场景有不同的针对性产品
分布式架构
- 数据分布策略:决定了数据怎么分布到集群里的多个物理节点,是否均匀, 是否能做到高性能
- 数据复制协议:影响|0路径的性能、机器故障场景的处理方式
- 分布式事务算法:多个数据库节点协同保障一个事务的ACID特性的算法,通常基于2pc的思想设计
