3. RNN的复杂变种
3.1. GRU(Gated Recurrent Unit)
GRU的提出是为了解决RNN难以学习到输入序列中的长距离信息的问题。
GRU引入一个新的变量——记忆单元,简称C。C⟨t⟩其实就是a⟨t⟩
C的表达式不是一步到位的,首先定义C的候选值C~:
C~⟨t⟩=tanh(Wc[C⟨t−1⟩,x⟨t⟩]+bc)
更新门:
Γu=σ(Wu[C⟨t−1⟩,x⟨t⟩]+bu)
在实际训练好的网络中Γ要么很接近1要么很接近0,对应着输入序列里面有些元素起作用有些元素不起作用。
C⟨t⟩=Γu∗C~⟨t⟩+(1−Γu)∗C⟨t−1⟩
也即输入序列的有些元素,记忆单元不需要更新,有些元素需要更新。
The cat, which already ate ..., was full
cat后面的词直到was之前,都不需要更新C,直接等于cat对应的C
可以解决梯度消失的问题.输出层的梯度可以传播到cat处
注:C和Γ都可以是想聊,它们在相乘时采用的是element-wise的乘法。当为向量时,与cat的单复数无关的词对应的Γ可能有些维度为零,有些维度不为零。为零的维度,是用来保留cat的单复数信息的;不为零的维度可能是保留其他语义信息的,比如是不是food呀之类的
目前讨论的是简化版的GRU,结构图如下
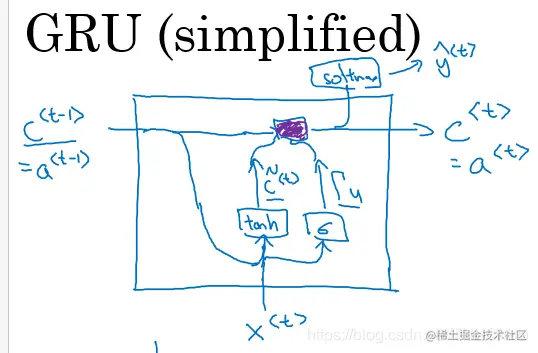
图3.1GRU的一个基本单元
完整的GRU:
C~⟨t⟩ΓuΓrC⟨t⟩a⟨t⟩=tanh(Wc[Γr∗C⟨t−1⟩,x⟨t⟩]+bc)=σ(Wu[C⟨t−1⟩,x⟨t⟩]+bu)=σ(Wr[C⟨t−1⟩,x⟨t⟩]+br)=Γu∗C~⟨t⟩+(1−Γu)∗C⟨t−1⟩=C⟨t⟩(3-1)
Γr表示了C~⟨t⟩和C⟨t−1⟩之间的相关程度
3.2. LSTM(Long Short-Term Memory)
没有了Γr,将1−Γu用Γf代替
C~⟨t⟩ΓuΓfΓoC⟨t⟩a⟨t⟩y~⟨t⟩=tanh(Wc[a⟨t−1⟩,x⟨t⟩]+bc)=σ(Wu[a⟨t−1⟩,x⟨t⟩]+bu)=σ(Wf[a⟨t−1⟩,x⟨t⟩]+bf)=σ(Wo[a⟨t−1⟩,x⟨t⟩]+bo)=Γu∗C~⟨t⟩+Γf∗C⟨t−1⟩=Γo∗tanh(C⟨t⟩)=softmax(a⟨t⟩)(3-2)
(注意公式里面的Γu等价于图片中的Γi)
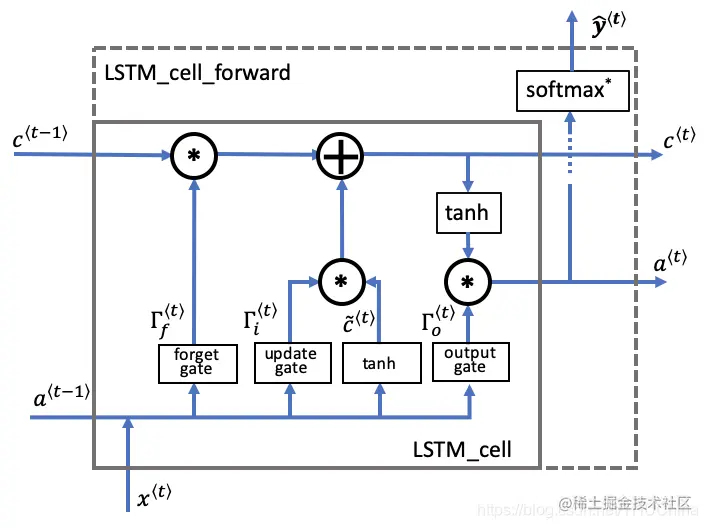
图3.2 LSTM的一个基本单元
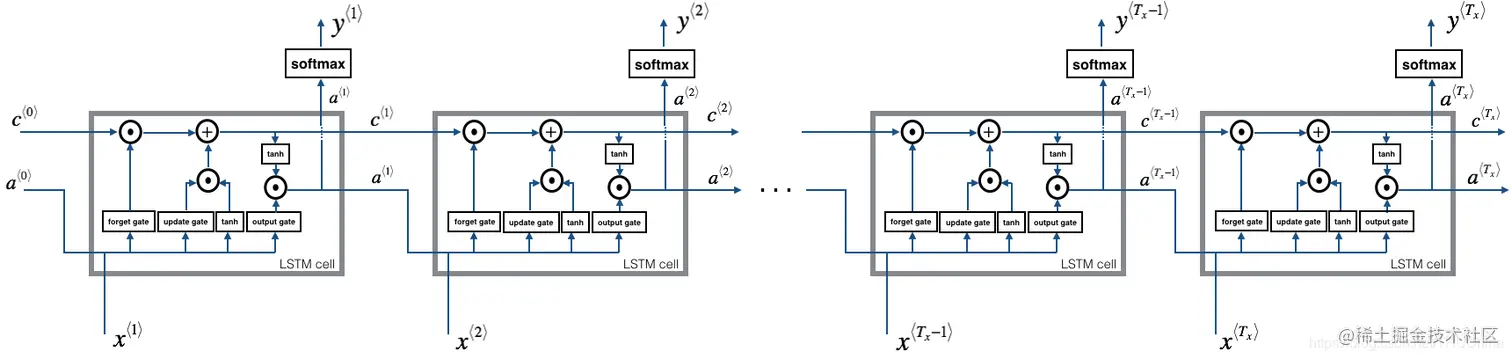
图3.3 标准LSTM模型-输入维数等于输出维数
3.2.1. peephole连接
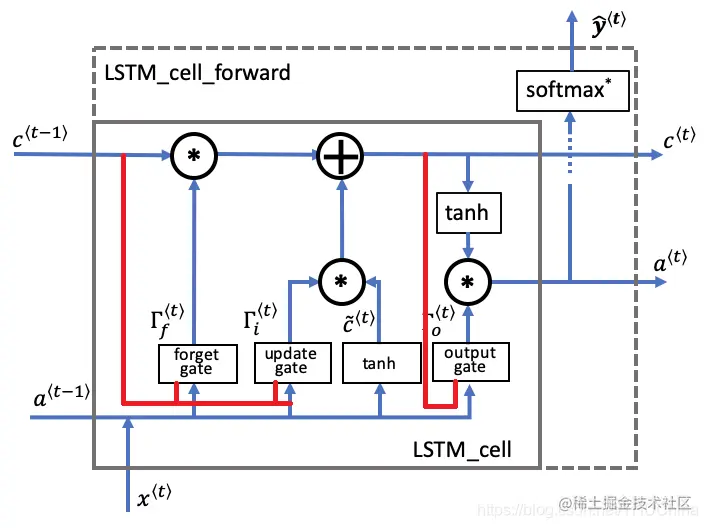
图3.4 LSTM带有peephole
C~⟨t⟩ΓuΓfΓoC⟨t⟩a⟨t⟩y~⟨t⟩=tanh(Wc[a⟨t−1⟩,a⟨t−1⟩,x⟨t⟩]+bc)=σ(Wu[c⟨t−1⟩,a⟨t−1⟩,x⟨t⟩]+bu)=σ(Wf[c⟨t−1⟩,a⟨t−1⟩,x⟨t⟩]+bf)=σ(Wo[c⟨t⟩,a⟨t−1⟩,x⟨t⟩]+bo)=Γu∗C~⟨t⟩+Γf∗C⟨t−1⟩=Γo∗tanh(C⟨t⟩)=softmax(a⟨t⟩)(3-3)
3.2.2 projection
对隐藏层状态a进行一次线性变换,降低其维数
C~⟨t⟩ΓuΓfΓoC⟨t⟩a0⟨t⟩a⟨t⟩y~⟨t⟩=tanh(Wc[a⟨t−1⟩,a⟨t−1⟩,x⟨t⟩]+bc)=σ(Wu[c⟨t−1⟩,a⟨t−1⟩,x⟨t⟩]+bu)=σ(Wf[c⟨t−1⟩,a⟨t−1⟩,x⟨t⟩]+bf)=σ(Wo[c⟨t⟩,a⟨t−1⟩,x⟨t⟩]+bo)=Γu∗C~⟨t⟩+Γf∗C⟨t−1⟩=Γo∗tanh(C⟨t⟩)=Wproja0⟨t⟩+bproj=softmax(a⟨t⟩)(3-4) 

