

这是我参与「第三届青训营 -后端场」笔记创作活动的的第2篇笔记。
继续通过Go by Example对基础语法进行巩固,本篇总结了与并发编程相关的基础语法,如通道、协程和WaitGroup等。同时对Golang依赖管理Go Module的使用进行总结,对Go程序如何进行单元测试以及相关注意事项进行总结。最后是以“青训营话题页”为需求,进行项目实战,主要实现了话题和回帖的查询功能和发帖功能。完整代码见Github。
并发编程语法
通道
- goroutine是轻量级的执行线程,通过关键字
go就能同步或异步启动一个协程。Go runtime是以并发的方式运行协程。
func f(from string) {
for i := 0; i < 3; i++ {
fmt.Println(from, ":", i)
}
}
f("direct") // 直接调用函数
go f("goroutine") // 启动协程调用函数
- channel是连接多个goroutine的管道,可以从一个goroutine发送数据给channel,另一个goroutine从channel接收数据。默认发送和接收都是阻塞的,也就是说默认的channel是同步操作。
messages := make(chan string)
go func() { messages <- "ping" }()
msg := <- messages
fmt.Println(msg)
- 默认channel是无缓冲的,所以能够实现同步。有缓冲的channel能够实现异步。
messages := make(chan string, 2)
messages <- "buffered"
messages <- "channel"
fmt.Println(<-messages)
fmt.Println(<-messages)
- 通过无缓冲channel,以阻塞接收的方式实现同步。
func worker(done chan bool) {
fmt.Print("working...")
time.Sleep(time.Second)
fmt.Println("done")
done <- true
}
done := make(chan bool)
go worker(done)
// 阻塞接收
<- done
- channel作为函数参数,可以指定方向,是否只读或只写,可以提升程序的安全性。
pings := make(chan<- string) // 只写
pongs := make(<-chan string) // 只读
- select可以同时等待多个channel,选择channel执行。
- 使用带default的select实现非阻塞通道的发送、接收,也可以实现非阻塞的多路select。
messages := make(chan string)
// 非阻塞接收
select {
case msg := <- messages:
fmt.Println("received message", msg)
default:
fmt.Println("no message received")
}
// 非阻塞发送
msg := "hi"
select {
case messages <- msg:
fmt.Println("sent message", msg)
default:
fmt.Println("no message sent")
}
- 通过channel和select可以进行超时处理。
- 当关闭一个channel以后,就不能再发送数据给channel,因此可以向channel的接收方传达工作已经完成的信息。
- 线程和协程的区别:
- 一个线程可以有多个协程,协程是轻量级线程;
- 线程栈MB级别,协程栈KB级别。
定时
- Go可以通过Timer设置在未来某个时间点运行Go代码。
// 定时器等待2s
timer1 := time.NewTimer(2*time.Second)
// 一直阻塞,直到C明确发送定时器失效的值
<-timer1.C
fmt.Println("Timer 1 fired")
- 当你想要以固定的时间间隔重复执行,可以使用Ticker。
// 数据每隔500ms到达
ticker := time.NewTicker(500*time.Millisecond)
done := make(chan bool)
go func() {
for {
select {
case <- done:
return
case t := <-ticker.C:
fmt.Println("Tick at", t)
}
}
}()
// 等待1600ms后,停止ticker
time.Sleep(1600*time.Millisecond)
ticker.Stop()
done <- true
fmt.Println("Ticker stopped")
- Golang可以基于goroutine、channel和timer实现速率限制。速率限制是控制服务资源利用和质量的重要机制。
WaitGroup
- 使用WaitGroup等待多个goroutine完成。
func worker(id int) {
fmt.Printf("Worker %d strarting\n", id)
time.Sleep(time.Second)
fmt.Printf("Worker %d done\n", id)
}
func main() {
var wg sync.WaitGroup
// 启动goroutine,并递增WaitGroup的计数器
for i := 1; i <= 5; i++ {
wg.Add(1)
i := i
// 将worker调用封装到一个闭包中,可以确保通知WaitGroup,此工作线程已完成
// worker线程本身也就不需要知道执行涉及的并发原语
go func() {
defer wg.Done()
worker(i)
}()
}
// 阻塞,直到WaitGroup计数器恢复为0
wg.Wait()
}
- Go的状态管理机制主要是依靠channel的通信来完成的,通过
sync/atomic可以实现多个goroutine间的原子计数。
func main() {
// 无符号整型变量表示计数器
var ops uint64
// 等待所有goroutine完成工作
var wg sync.WaitGroup
// 启动50个goroutine,每个goroutine会将计数器递增1000次
for i := 0; i < 50; i++ {
wg.Add(1)
go func() {
for c := 0; c < 1000; c++ {
// 使用AddUint64让计数器自增
atomic.AddUint64(&ops, 1)
}
wg.Done()
}()
}
// 等待所有goroutine结束
wg.Wait()
// 安全访问ops, 50000
fmt.Println("ops:", ops)
}
- 使用互斥量在Go协程间安全访问数据。
type Container struct {
mu sync.Mutex
counters map[string]int
}
func (c *Container) inc(name string) {
// 互斥访问counters,实现数据同步
c.mu.Lock()
defer c.mu.Unlock()
c.counters[name]++
}
- Go共享内存的思想是,通过通信使每个数据仅被单个协程拥有,也就是通过通信实现共享内存。
- WaitGroup的
Add对计数器加1,Done对计数器减一,Wait主线程阻塞直到计数器为0。
依赖管理
Go语言包的依赖管理主要有两个问题:
- 如何控制不同环境(项目)依赖的版本;
- 如何控制依赖库的版本。
演进过程
- GOPATH:是Go的环境变量,它无法满足不同项目依赖同一个库的不同版本;
项目A和项目B依赖于同一package的不同版本,依赖冲突。 - Go Vendor:将依赖包副本存放在Vendor目录下,可以满足多个项目需要同一个package的不同版本的需求;但无法控制依赖库的版本,更新项目可能出现依赖冲突,导致编译出错;
项目A的依赖库package D的不同版本无法兼容,依赖冲突。 - Go Module: Go官方推出的依赖管理系统,解决了上诉两个依赖管理问题。通过
go.mod文件管理依赖包版本,通过go get/go mod命令工具管理依赖包。
Go Module
依赖管理三要素:
- 配置文件,描述依赖——
go.mod; - 中心仓库管理依赖库——
Proxy; - 本地工具——
go get/go mod。
依赖配置
项目多库依赖中,依赖配置选择最低的兼容版本。
依赖分发
直接使用版本管理仓库下载依赖,主要存在3个问题:
- 无法保证构建稳定性:如果软件作者增加/修改/删除软件版本,会导致构建使用其他版本的依赖,或者找不到依赖版本;
- 无法保证依赖可用性:如果软件作者直接从代码平台删除软件,会保证依赖不可用;
- 增加第三方压力:给代码托管平台增加负载压力。
go proxy能够解决这些问题,它会缓存源站的软件内容,缓存的软件版本不会改变,在源站删除软件之后也能使用,实现了immutability和available的依赖分发。
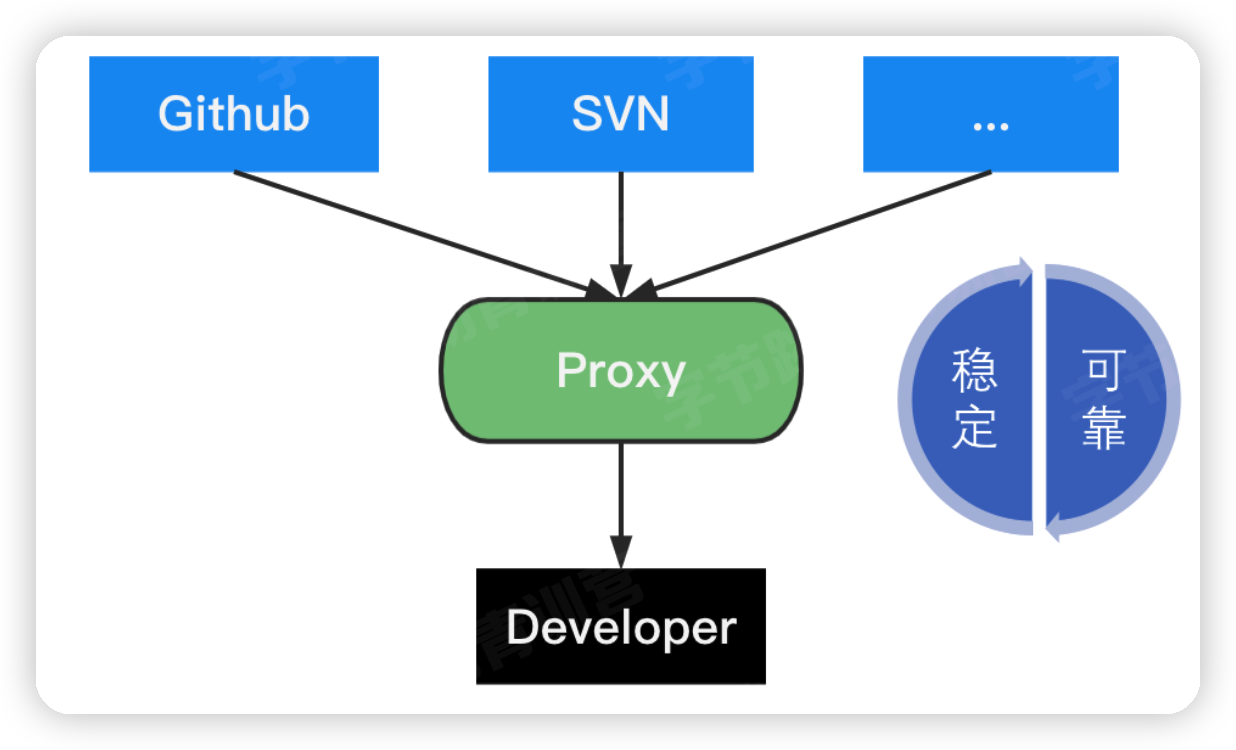
Go Module通过GOPROXY环境变量控制go proxy的使用。示例配置:
GOPROXY="https://proxy1.cn, https://proxy2.cn, direct"
整体的依赖寻址路径,会优先从proxy1下载;如果proxy1不存在,就从proxy2下载;如果proxy2不存在,就从direct(源站)下载,并缓存到proxy1,proxy2站点中。
工具
- go get
go get example.org/pkg@XXX
// XXX:update 默认
// XXX:none 删除依赖
// XXX:v1.1.2 tag版本,语义版本
// XXX:23dfdd5 特定的commit
// XXX:master 分支的最新commit
- go mod
go mod init projName // 初始化,创建go.mod文件
go mod tidy // 增加需要的依赖,删除不需要的依赖
go mod download // 下载模块到本地缓存
go mod graph // 打印依赖图
go mod verify // 校验依赖
测试
分类
软件测试能够反映系统的质量问题,质量问题决定着系统的稳定性,如果线上系统出现bug,就会造成事故,而事故直接和收益挂钩。如何避免事故的发生,就要通过完备的测试。
测试分为:
- 回归测试:QA手动通过终端回归一些固定的主流程场景;
- 集成测试:对系统功能维度进行测试验证;
- 单元测试:测试开发阶段,开发者对单独的函数,模块做功能验证。
三者的层级从上至下,测试成本逐渐减少,而测试覆盖率逐渐上升,所以单元测试的覆盖率一定程度决定代码质量。
单元测试
单元测试主要包括:输入、测试单元、输出以及校对。测试单元有接口、函数和模块等,校对可以保证代码的功能与我们的预期是否相符。
单元测试一方面保证质量,在整体覆盖率足够的情况下,一定程度上既保证了新功能本身的正确性,又未破坏原有代码的正确性。另一方面可以提升效率,在代码有bug的情况下,通过编写单元测试,可以在一个较短周期内定位和修复问题。
规则:
- 所有测试文件以
_test.go结尾; func TestXXX(*testing.T),被测函数首字母需要大写;- 初始化逻辑放到
TestMain中。
代码覆盖率:
- 衡量代码是否经过足够的测试;
- 评价项目的测试水准;
- 评估项目是否达到高水准测试等级。
例子:
// judgement.go
func JudgePassLine(score int16) bool {
if score >= 60 {
return true
}
return false
}
// judgement_test.go
func TestJudgePassLineTre(t *testing.T) {
output := JudgePassLine(70)
expectOutput := true
assert.Equal(t, expectOutput, output)
}
func TestJudgePassLineFalse(t *testing.T) {
output := JudgePassLine(50)
expectOutput := false
assert.Equal(t, expectOutput, output)
}
// 命令:go test judgement_test.go judgement.go --cover
// 结果:ok command-line-arguments 0.711s coverage: 100.0% of statements
测试tips:
- 实际项目中,一般要求的是50%~60%的覆盖率,对于资金型服务,覆盖率要求达到80%+;
- 测试分支要相互独立,全面覆盖;
- 测试单元粒度要足够小,要符合函数设计的单一职责。
依赖:
工程中复杂的项目,单元测试会依赖File、DB和Cache等外部依赖;单元测试需要保证稳定性和幂等性。
- 稳定性是指相互隔离,能在任何时间、任何环境运行测试;
- 幂等性是指每一次的测试运行都应该产生和之前一样的结果。
Mock机制可以实现稳定性和幂等性。
Mock测试
使用Monkey mock测试库:https://github.com/bouk/monkey。它可以对method或者实例的方法进行mock、反射和指针赋值。
Monkey Patch的作用域在Runtime,在运行时通过Go的unsafe包,能够将内存中函数的地址替换为运行时函数的地址。将待打桩函数或方法的实现跳转。具体代码见Github。
基准测试
基准测试是指测试一段程序的运行性能以及耗费CPU的程度。在实际项目开发中,经常会遇到代码性能瓶颈,为了定位问题经常要对代码做性能分析,就会用到基准测试。
服务器负载均衡例子,随机选择执行服务器:
// load_balance_selector.go
var ServerIndex [10]int
func InitServerIndex() {
for i := 0; i < 10; i++ {
ServerIndex[i] = i
}
}
func Select() int {
return rand.Intn(10)
}
func FastSelect() int {
return fastrand.Intn(10)
}
// load_balance_selector_test.go
func BenchmarkSelect(b *testing.B) {
InitServerIndex()
b.ResetTimer()
for i := 0; i < b.N; i++ {
Select()
}
}
func BenchmarkSelectParallel(b *testing.B) {
InitServerIndex()
b.ResetTimer()
//b.SetParallelism(20)
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
Select()
}
})
}
func BenchmarkFastSelectParallel(b *testing.B) {
InitServerIndex()
b.ResetTimer()
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
FastSelect()
}
})
}
命令:go test -bench .
基准测试以Benchmark开头,入参是testing.B,用b中的N值反复递增循环测试。
RestTimer重置计时器,在reset之前做了init或其他准备操作,这些操作不应该作为基准测试的范围;
runparallel是多协程并发测试,执行两个基准测试,发现代码在并发情况存在劣化,主要原因是rand为了保证全局的随机性和并发安全,持有一把全局锁。
// rand.Intn()
func Intn(n int) int { return globalRand.Intn(n) }
var globalRand = New(&lockedSource{src: NewSource(1).(*rngSource)})
type lockedSource struct {
lk sync.Mutex
src *rngSource
}
优化:
为了解决随机性能问题,引入了高性能随机数方法fastrand,性能提升百倍,主要的思路是牺牲一定的数列一致性,在大多数场景适用,遇到随机场景可以尝试用fastrand。开源地址:https://github.com/bytedance/gopkg
项目实战
需求设计
以掘金社区话题入口报名页面为需求模型,该页面包括话题详情、回帖列表、支持回帖、点赞和回帖回复,开发一个服务端小功能。
需求描述:
- 展示话题(标题,文字描述)和回帖列表;
- 不考虑前端页面,实现本地web服务;
- 话题和回帖数据用文件存储。
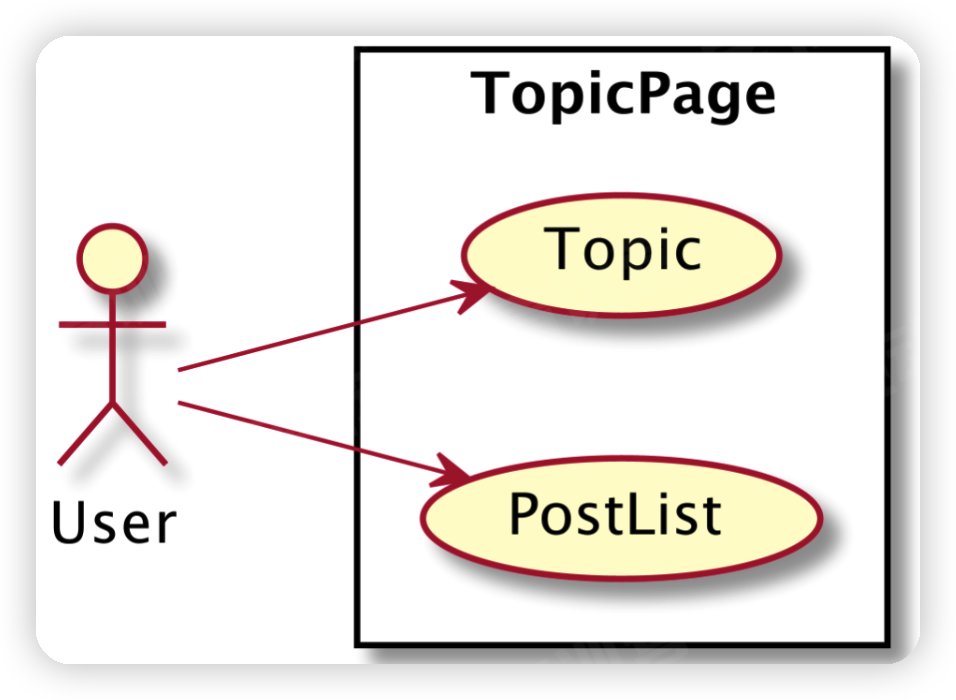
需求用例:User,Topic,PostList。
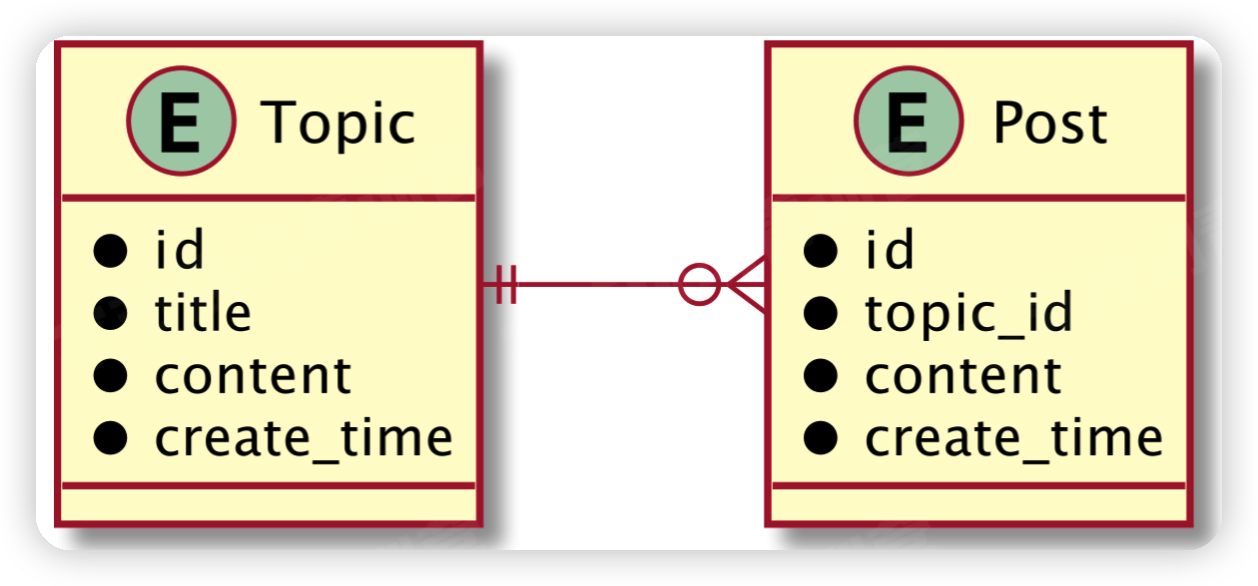
两个实体的ER图:
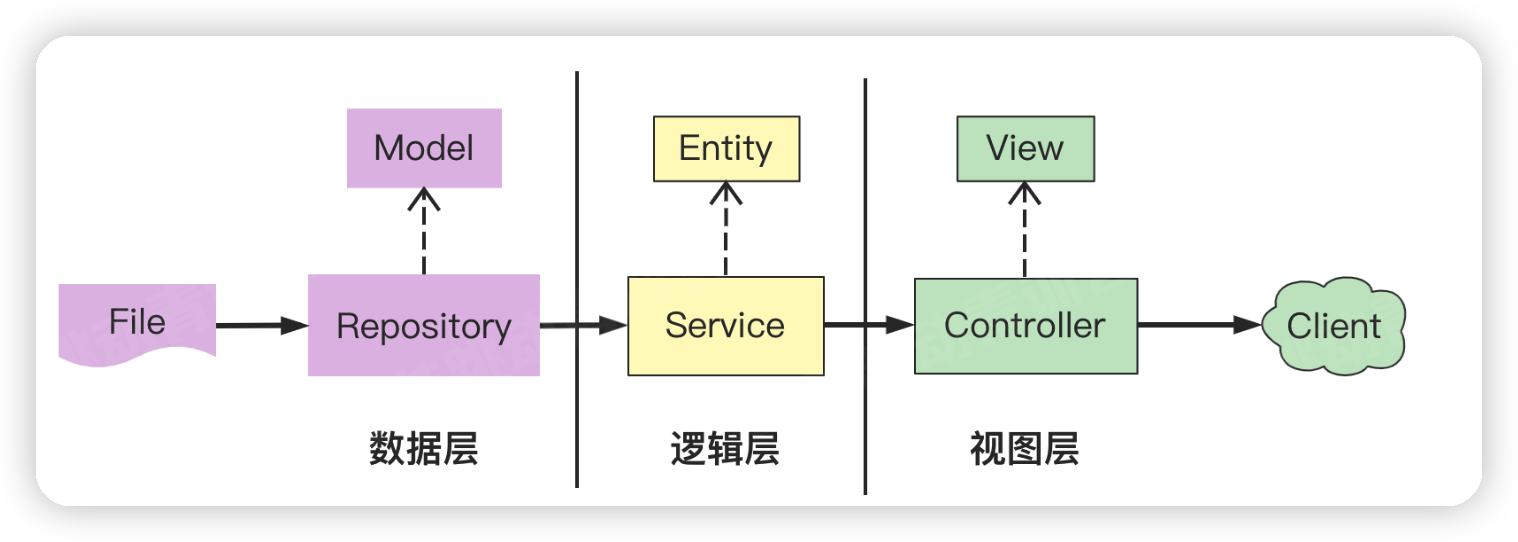
分层结构:
- 数据层:数据 Model,外部数据的增删改查——Repository;
- 逻辑层:业务 Entity,处理核心业务逻辑输出——Service;
- 视图层:视图 View,处理和外部的交互逻辑——Controller。
代码开发
Repository:
// topic,post model
type Topic struct {
Id int64 `json:"id"`
CreateTime int64 `json:"create_time"`
Title string `json:"title"`
Content string `json:"content"`
}
type Post struct {
Id int64 `json:"id"`
ParentId int64 `json:"parent_id"`
CreateTime int64 `json:"create_time"`
Content string `json:"content"`
}
如何实现查询:QueryTopicById, QueryPostsByParentId
对于全扫描遍历的查询,使用索引进行优化,用map实现内存索引,利用文件元数据初始化全局内存索引,实现O(1)的查找。
var (
topicIndexMap map[int64]*Topic
postIndexMap map[int64][]*Post
)
初始化话题数据索引:
func initTopicIndexMap(filePath string) error {
open, err := os.Open(filePath + "topic")
if err != nil {
return err
}
scanner := bufio.NewScanner(open)
topicTmpMap := make(map[int64]*Topic)
for scanner.Scan() {
text := scanner.Text()
var topic Topic
if err := json.Unmarshal([]byte(text), &topic); err != nil {
return err
}
topicTmpMap[topic.Id] = &topic
}
topicIndexMap = topicTmpMap
return nil
}
初始回帖数据索引:
func initPostIndexMap(filePath string) error {
open, err := os.Open(filePath + "post")
if err != nil {
return err
}
scanner := bufio.NewScanner(open)
postTmpMap := make(map[int64][]*Post)
for scanner.Scan() {
text := scanner.Text()
var post Post
if err := json.Unmarshal([]byte(text), &post); err != nil {
return err
}
posts, ok := postTmpMap[post.ParentId]
if !ok {
postTmpMap[post.ParentId] = []*Post{&post}
continue
}
posts = append(posts, &post)
postTmpMap[post.ParentId] = posts
}
postIndexMap = postTmpMap
return nil
}
使用sync.Once实现单例模式,减少存储的浪费。话题查询的实现:
// topic
var (
topicDao *TopicDao
// singleton, space saving
topicOnce sync.Once
)
func NewTopicDaoInstance() *TopicDao {
topicOnce.Do(
func() {
topicDao = &TopicDao{}
})
return topicDao
}
func (*TopicDao) QueryTopicById(id int64) *Topic {
return topicIndexMap[id]
}
回帖查询的实现:
var (
postDao *PostDao
postOnce sync.Once
)
func NewPostDaoInstance() *PostDao {
postOnce.Do(
func() {
postDao = &PostDao{}
})
return postDao
}
func (*PostDao) QueryPostByParentIdd(parentId int64) []*Post {
return postIndexMap[parentId]
}
Service:
PageInfo实体:
type PageInfo struct {
Topic *repository.Topic
PostList []*repository.Post
}
实现流程是:参数校验,准备数据,组装实体。代码流程编排:
func (f *QueryPageInfoFlow) Do() (*PageInfo, error) {
if err := f.checkParam(); err != nil {
return nil, err
}
if err := f.prepareInfo(); err != nil {
return nil, err
}
if err := f.packPageInfo(); err != nil {
return nil, err
}
return f.pageInfo, nil
}
prepareInfo中,话题和回帖可以并行处理,提高执行效率。
func (f *QueryPageInfoFlow) prepareInfo() error {
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
topic := repository.NewTopicDaoInstance().QueryTopicById(f.topicId)
f.topic = topic
}()
go func() {
defer wg.Done()
posts := repository.NewPostDaoInstance().QueryPostByParentIdd(f.topicId)
f.posts = posts
}()
wg.Wait()
return nil
}
Controller:
构建View对象PageData,通过code msg打包业务状态信息,用data承载业务实体信息。
type PageData struct {
Code int64 `json:"code"`
Msg string `json:"msg"`
Data interface{} `json:"data"`
}
server.go:
- 初始化数据索引
- 初始化引擎配置
- 构建路由
- 启动服务
func main() {
// 1. init Index
if err := repository.Init("./data/"); err != nil {
fmt.Printf("init Index failed, err:%v\n", err)
return
}
// 2. init engine
r := gin.Default()
// 3. register router
r.GET("/community/page/:id", func(c *gin.Context) {
topicId := c.Param("id")
data := controller.QueryPageInfo(topicId)
c.JSON(http.StatusOK, data)
})
// 4. run
err := r.Run(":9091")
if err != nil {
fmt.Printf("run failed, err:%v\n", err)
return
}
}
测试运行
命令:go build ./project-demo1
课后实践
- 支持发布帖子
- 本地Id生成需要保证不重复、唯一性(snowflake算法)
- Append文件,更新索引,注意Map的并发安全问题(读写锁)
完整代码见Github。
总结
本篇主要是对Golang并发编程,依赖管理和单元测试等基础知识进行总结归纳。最后通过一个Web需求熟悉了Gin框架,对于Web开发的一个流程有了初步认识。同时对于snowflake算法和map并发安全访问也进行了实践和学习。
写blog是一个梳理思路的过程,应该循序渐进,详略得当,同时要坚持分享,这是一个良好的正反馈循环,奥利给。欢迎大家评论转载,多多发表自己的意见或建议。