1、温度常数简介
由上一篇我所写知识蒸馏中的温度参数(1)中我介绍了知识蒸馏以及具体的损失函数的表达式。其中损失函数中:

其中Lsoft中就涉及到了常数T,而T有应该设置为多少会比较合适呢?它与模型训练又有哪些具体的联系呢?
2、温度常数设定
2.1 温度常数的特性
- 当 T = 1 时,那即与普通的softmax一致
- 当 T > 1 时,softmax后的值就会分布的更加均匀,平缓
- 当 T < 1 时,softmax取值后会变得更加陡峭
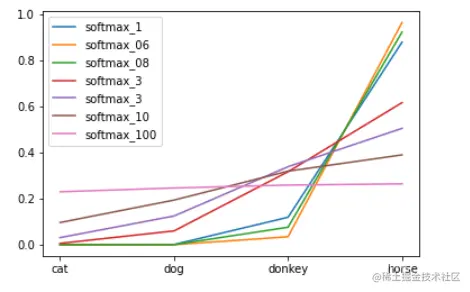
以上图片来自于:知识蒸馏(knowledge distillation)测试以及利用可学习参数辅助知识蒸馏训练Student模型
结论:当T值比较大时,因为各个值都会变得平均,负标签显著变大,此时学生模型对于负标签的关注度也会增大。反之,当T值较小时,负标签会变得更小,学生模型对于负标签的关注也会减少。
所以总结一下:
- 从有部分信息量的负标签中学习 --> 温度要高一些
- 防止受负标签中噪声的影响 --> 温度要低一些
还有一种说法是:Student_Net的参数量小时,因为不能捕获所有Teacher_Net的知识,可以选择适当忽略掉某些负标签,选择一个温度常数较低的值(没有试验过,待考证)
3、讨论
既然Student_Net学习了Teacher_Net输出的logit,为何不用学生模型的logit直接拟合Teacher_Net的logit呢?即直接用两者的平方差公式。
Lossdiff=1/2∗1∑N(vi−ui)2(1)
这里提出了一个观点:当T→∞时,优化Lsoft就等价于平方差公式。
具体公式推导如下:
∂ui∂Lsoft=T1(qi−pi)=T1(1∑Neuj/Teui/T−1∑Nevj/Tevi/T)(2)
根据洛必达法则, 当x→0,则有ex−1→x。
当 T→∞,ui/T→0,可得到euj/T→1+uj/T
所以此时2式可以化简为:
T1(N+∑ui/Tui/T+1−N+∑vi/Tvi/T+1)(3)
由于模型输出一般会符合标准正态分布,所以假设∑ui=∑vi=0
所以3式会化简为
∂ui∂Lsofft≈NT21(ui−vi)(4)
从上可以看到4式得到的偏导结果即是1式对ui求偏导数结果一致。
结论:Lossdiff其实就是T→∞的特殊情况
4、参考
# 知识蒸馏(knowledge distillation)测试以及利用可学习参数辅助知识蒸馏训练
# 知识蒸馏(Knowledge Distillation) 经典之作
以上便是关于温度常数涉及到的知识点。因为本人水平有限,如若文中有错误,欢迎提出。


