持续创作,加速成长!这是我参与「掘金日新计划 · 6 月更文挑战」的第4天,点击查看活动详情
感觉很少有人能一次就把文章写得比较完整,所以自己也准备不断学习,然后推敲文字,争取以后把每一篇文章写得不说浅显易懂吧,希望对您了解这方面知识会有所帮助
概要
- 简单回顾一下 HMM 的数学模型
- 评估问题求解一般方法
- 为什么引入前向概率来求解 P(O∣λ)
- 前向概率的推导
简单回顾
上一次分享简单总结一下前向算法,有点过于简单,这一次我们准备详细地推导一遍前向算法,在开始之前我们简单对 HMM 模型总结一下
隐马尔可夫模型中,是由隐含随机变量和观测随机变量组成时序模型,在每一个时刻 t 我们能够观测到的随机变量用 O 来表示,这里 O 表示一个随机变量集合,通常可以表示为 Q={o1,o2,⋯,oT} 那么每一个随机变量取值可能用集合 V 记做 V={v1,v2,⋯,vm} 那么也就是观测随机变量可能是 m 个值,每一个观测值都是与对应时刻的隐含随机变量相关的,那么用大写字母 I 表示隐含变量,记做 I={i1,i2,⋯,iT} ,每一个时刻隐含变量可能取值为 Q 来表示也就是 Q={q1,q2,⋯,qN}。
每一个时刻从某一个状态转移到另一个状态记做 aij=P(it+1=qj∣it=qi) 而某一个状态到观测值的概率为观测生成概率为 bj(k)=P(ot=vk∣it=qj) 这两个概率是状态转移概率 A 和观测生成概率 B。
然后我们再去总结 2 个假设,分别是齐次马尔科夫假设和
P(it+1∣i1,i2,⋯,it,o1,⋯,ot)=P(it+1∣it)P(ot∣i1,⋯,it,o1,⋯,ot)=P(ot∣it)
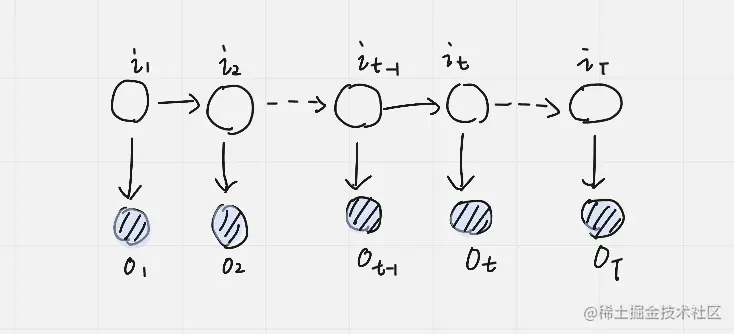
评估问题
我们要求解的是 P(O∣λ) 也就是在给定了参数 λ 条件下,观测到 O 的观测序列的概率是多少
P(O∣λ)=I∑P(I,O∣λ)=I∑P(O∣I,λ)P(I∣λ)
然后可以通过引入隐含状态序列 I ,引入后通过 I 求和也就是利用边缘概率性质可以将 P(O∣λ)=∑IP(I,O∣λ) 接下来我们联合概率的乘法可以得到 ∑IP(I,O∣λ)=∑IP(O∣I,λ)P(I∣λ)。
然后我们先 P(I∣λ) 中 I 序列进行展开
P(I∣λ)=P(i1,i2,⋯,it∣λ)=P(it∣i1,⋯,it−1,λ)P(i1,⋯,it−1,λ)
其中 P(it∣i1,⋯,it−1,λ) 利用齐次马尔科夫性质可以得到 P(it∣it−1), 也就是 ait−1,it 这种写法,然后再看 P(i1,⋯,it−1∣λ) 不难看出递归的形式,所以可以递归下去
ait−1,itait−2,it−1⋯ai1,i2π(i1)π(ai1)t=2∑Tait−1,it
然后我们再去看 P(O∣I,λ) 这里推导过程和上面也比较类似
P(O∣I,λ)=P(o1,⋯,ot∣i1,⋯,it,λ)
开始还是将其展开写成 P(o1,⋯,ot∣i1,⋯,it,λ) 然后将联合概率写成条件概率
P(O∣I,λ)=P(o1,⋯,ot∣i1,⋯,it,λ)P(ot∣o1,⋯,ot−1,i1,⋯,it,λ)P(o1,⋯,ot−1∣i1⋯it,λ)
根据马尔科夫观测独立假设 P(ot∣o1,⋯,ot−1,i1,⋯,it,λ) 可得到 P(ot∣it)=bit(ot)
P(O∣Iλ)=t=1∏Tbit(ot)
然后继续将 P(O∣I,λ) 和 P(I∣λ) 带入到上面式子得到
P(O∣λ)=I∑π(ai1)t=2∏Tait−1,itt=1∏Tbit(ot)
这里 ∑I 表示 T 个 it 求和符号,所以将 ∑I 展开来写成
i1∑i2∑⋯it∑
可以将上面式子改写为
i1∑i2∑⋯it∑π(ai1)t=2∏Tait−1,itt=1∏Tbit(ot)
这样计算时间复杂度为 O(NT) 接下来我们来看一看如何将计算过程进行化简来得到,这是因为其计算时间复杂度问题,所以才引入前向概率算法
前向概率
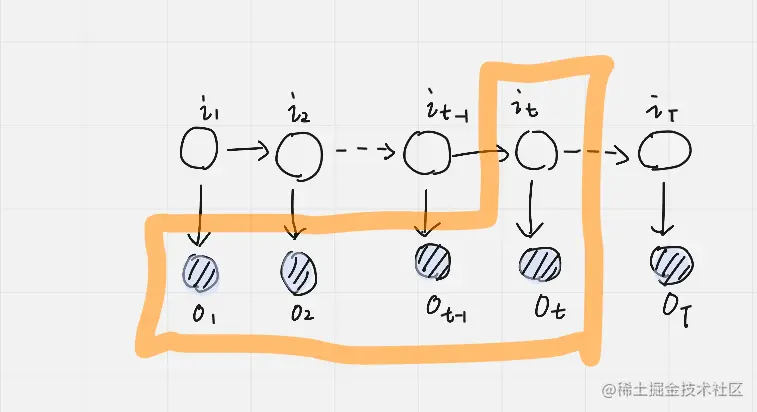
这里设计一个前向概率如上图,所谓前向概率就是对应某一个时刻,例如上图 t 时刻的联合概率用 αt(i) 这里 t 表示时刻,而 i 表示 t 时刻状态为 qi 的联合概率值。
αt(i)=P(o1,…,ot,it=qi∣λ)
结合上面图中橘黄色部分的我们可将 αt(i) 展开为 αt(i)=P(o1,…,ot,it=qi∣λ),那么求解 P(O∣λ) 概率就会转为为求 T 时刻的前向概率问题
αT(i)=P(O,it=qi∣λ)
P(O∣λ)=i=1∑NP(O,it=qi∣λ)=i=1∑NαT(i)
然后通过就是要找到 αt+1(j) 与 αt(i) 之间关系,只要能够找到一个等式中存在 αt+1(j) 与 αt(i) 我们就建立之间关系,由于这部分内容比较多,所以放到下一节给大家解释
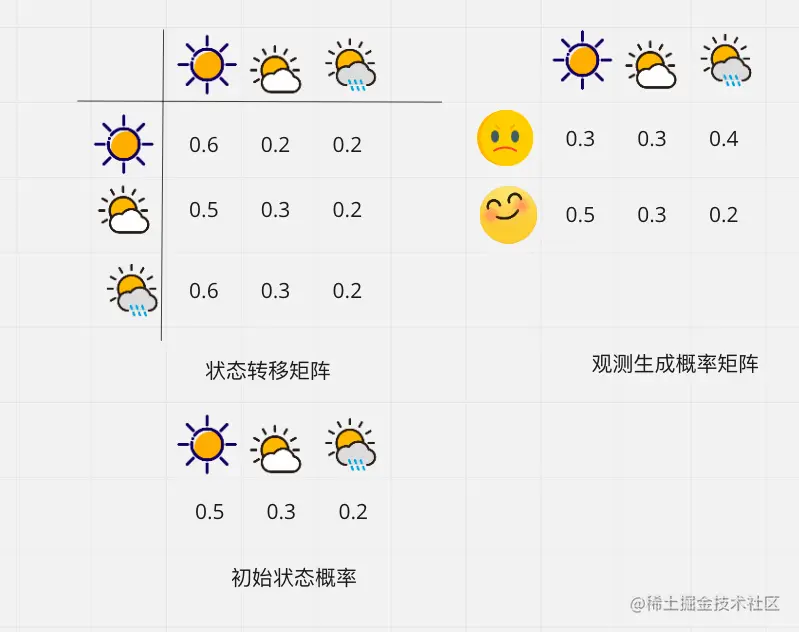
上面列出已知条件,也就是分别是π 状态初始值概率分布,状态转移概率和观测生成概率矩阵

这是我们观察序列
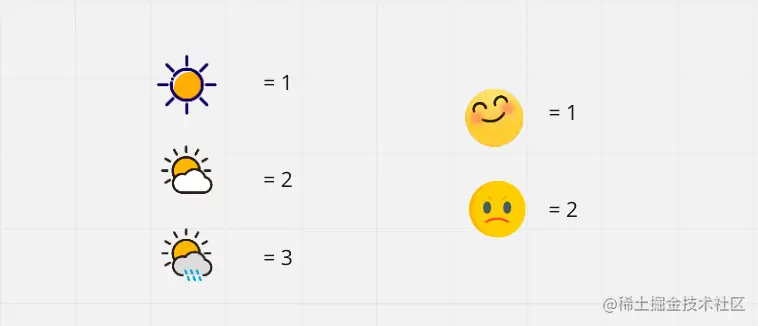
为了便于计算我们将随机事件用数值来表示
import numpy as np
pi_0 = np.array([0.5,0.3,0.2])
A = np.array([
[0.6,0.2,0.2],
[0.5,0.3,0.2],
[0.6,0.2,0.2]
])
B = np.array([
[0.5,0.3,0.2],
[0.3,0.3,0.4]
])
a_1 = pi_0 * B[0]
print(a_1)
a_1 = pi_0 * B[0]
print(a_1)
[0.25 0.09 0.04]
a_2 = np.dot(a_1,A)*B[1]
print(a_2)
[0.0657 0.0255 0.0304]
a_3 = np.dot(a_2,A)*B[0]
print(a_3)
[0.035205 0.008061 0.004864]
P(O∣λ)=i=1∑3α3(i)=0.04813
print(a_3.sum())


