持续创作,加速成长!这是我参与「掘金日新计划 · 6 月更文挑战」的第4天,点击查看活动详情
本系列更多文章见专栏:草履虫都能看懂的白话解析《动手学深度学习》
PS:专栏还在更新中。
不带参数的nadaraya-waston核回归
在讲什么是nadaraya-waston核回归之前先来简单回顾一下attention。
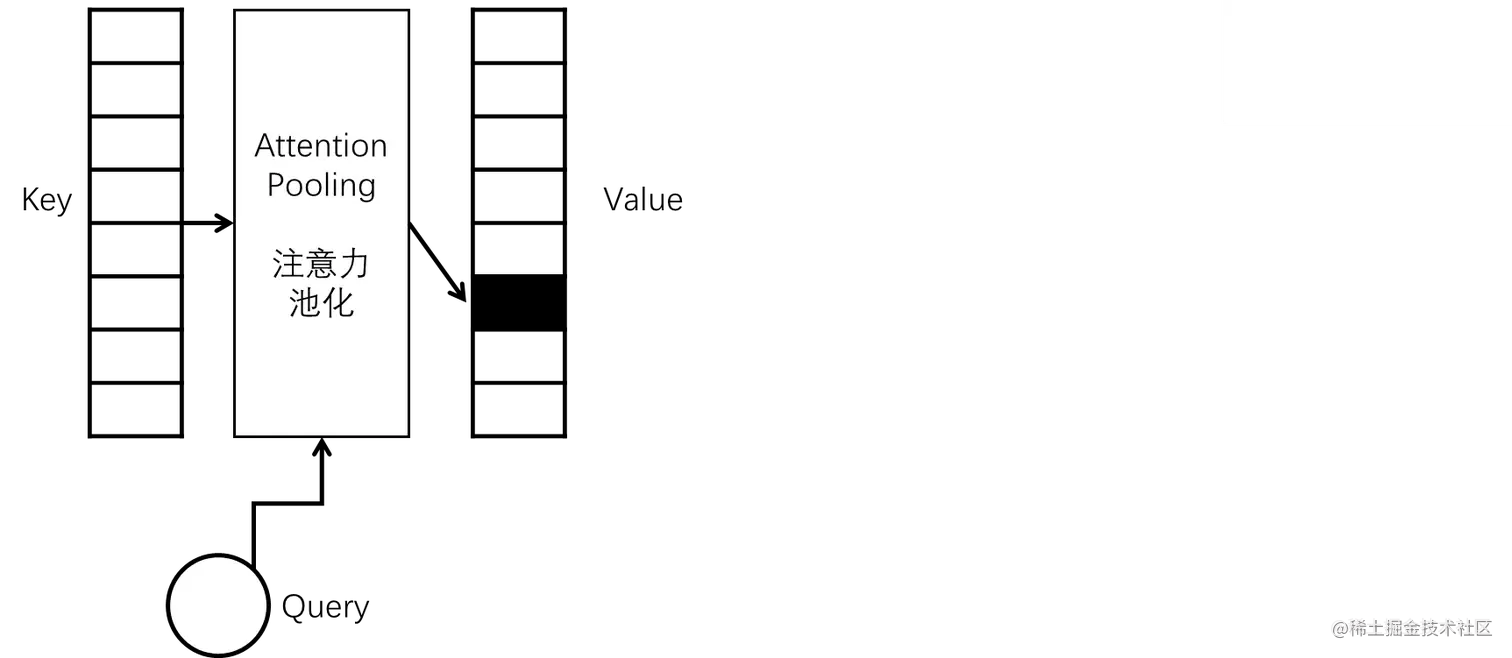
简单来说就是key-value键值对作为输入,现在有一个query,跟你的key经过一顿操作之后就将重心放到了你的某个value值上了。也就是经过注意力池化的计算之后将注意力汇聚到某一处了。
那怎么能做到这一点呢?早在1964年,Nadaraya和 Waston就提出了一个公式:
f(x)=i=1∑n∑j=1nK(x−xj)K(x−xi)yi
其中的K就是一个核,学过SVM(支持向量机)的应该知道,它是可以计算x和xi之间的距离的一个函数。(换言之你可以选择不同的核来计算二者之间的距离。)
在这里我们选定一个计算方法——高斯核:
K(u)=2π1exp(−2u2)
带入上边的公式:
f(x)=i=1∑n∑j=1nexp(−21(x−xj)2)exp(−21(x−xi)2)yi
看着上边的公式有没有那么一丝丝的眼熟。没错就是softmax。
y^=softmax(o)其中y^j=∑kexp(ok)exp(oj)
当用o进行softmax计算y^时,就等于当前的o求幂,再用结果除以所有o求幂之后的总和。这样可以确保输出非负的同时确保结果总和为1。
现在我们上边的式子中的−21(x−xi)2就等价与softmax中的o,所以上边的公式就可以转化为:
f(x)=i=1∑nsoftmax(−21(x−xi)2)yi.
- 在这里x就相当于attention中的query。
- xi相当于attention中的key。
- yi相当于attention中的value。
带参数的nadaraya-waston核回归
你以为上边就完了么!没有!因为上边那个方法只有在数据量足够大的时候才能达到比较好的效果。并且这个和我们平时学的不一样啊。参数呢!w呢! 作为优秀的炼丹人员,不学参数的模型不是好模型(我的谬论),所以我们得让他学参数!
f(x)=i=1∑n∑j=1nexp(−21((x−xi)w)2)exp(−21((x−xi)w)2)yi
给计算核加上一个参数即可w即可。之前说了softmax是对高斯核做求幂之后再除总和,所以在给高斯核并列加一个w,即给求幂函数内部加上一个w。
f(x)=i=1∑nsoftmax(−21((x−xi)w)2)yi.
总结
- attention pooling(注意力汇聚、注意力池化)的作用就是根据x的位置对y进行加权。
- 从Nadaraya-Watson 核回归的注意力池化例子可以知道,注意力汇聚可以分为非参数型和带参数型,并且那个核我们可以根据实际需求进行选择。


