

性能分析工具pprof-排查实战 | 青训营笔记
这是我参与「第三届青训营-后端场」笔记创作活动的的第3篇笔记
搭建pprof实践项目
我们的目标是熟悉pprof工具,能够排查性能问题,那么首先我们需要构造一个有问题的程序, 看看如何用pprof来定位性能问题点 这里有个开源项目,已经制造了一些问题代码,需要我们进行排查。大家用pprof示例命令实验下能否正常打开pprof页面,是否缺少graphviz的组件
我们来看看「炸弹I程序是怎么做的。图中代码是main.go中初始化htp服务和pprof接口的代码,无关逻辑有所省略。可以看到,引入http pprof这个包,它会将pprof的入口注册到/debug/pprof这个路径下, 我们可通过浏览器打开这个路径,来查着些基本的性能统计。 运行「炸弹」, 并等待它运行稳定
package main
import (
"log"
"net/http"
_ "net/http/pprof"
"os"
"runtime"
"time"
"github.com/wolfogre/go-pprof-practice/animal"
)
func main() {
log.SetFlags(log.Lshortfile | log.LstdFlags)
log.SetOutput(os.Stdout)
runtime.GOMAXPROCS(1)
runtime.SetMutexProfileFraction(1)
runtime.SetBlockProfileRate(1)
go func() {
if err := http.ListenAndServe(":6060", nil); err != nil {
log.Fatal(err)
}
os.Exit(0)
}()
for {
for _, v := range animal.AllAnimals {
v.Live()
}
time.Sleep(time.Second)
}
}
浏览器查看指标
在浏览器中打开http://localhost:6060/debug/pprof,可以看到这样的页面,这就是我们刚刚引入的net/http/pprof注入的入口了。 页面上展示了可用的程序运行采样数据,下面也有简单说明, 分别是:
- allocs:内存分配情况
- blocks:阻塞操作情况
- cmdline:程序启动命令及
- goroutine:当前所有goroutine的堆栈信息
- heap:堆上内存使用情况(同alloc)
- mutex:锁竞争操作情况
- profile:CPU占用情况
- threadcreate:当前所有创建的系统线程的堆栈信息
- trace:程序运行跟踪信息
cmdline显示运行进程的命令,threadcreate比较复杂,不透明,trace需要另外的工具解析,暂不涉及。
炸弹在CPU,堆内存,goroutine, 锁竞争和阻塞操作上埋了炸弹,可以使用pprofI具进行分析

allocs表示分配了12次内存,block表示有3次阻塞,goroutine表示有55个协程正在运行,heap为堆上内存使用,mutex表示有1个锁竞争,threadcreate表示有6个线程创建。
浏览器访问:http://localhost:6060/debug/pprof/allocs?debug=1

CPU
命令: topN 查看占用资源最多的函数

我们先从CPU问题排查开始,不同的操作系统具可能不同,我们首先使用自己熟悉的工具看看程序进程的资源占用,CPU占用了13.2%,显然这里是有问题的
pprof的采样结果是将一段时间内的信息汇 总输出到文件中,所以首先需要拿到这个profile文件。你可以直接使用暴露的接口链接下载文件后使用,也可以直接用pprofI具连接这个接口下载需要的数据。
这里我们使用go tool pprof +采样链接来启动采样。链接中就是刚刚「炸弹」 程序暴露出来的接口,链接结尾的profile代表采样的对象是CPU使用。 如果你在浏览器里直接打开这个链接,会启动一个60秒的采样,并在结束后下载文件。这里我们加上seconds=10的参数,让它采样+秒。稍等片刻,我们需要的采样数据已经记录和下载完成,并展示出pprof终端
go tool pprof "http://localhost:6060/debug/pprof/profile?seconds=10"

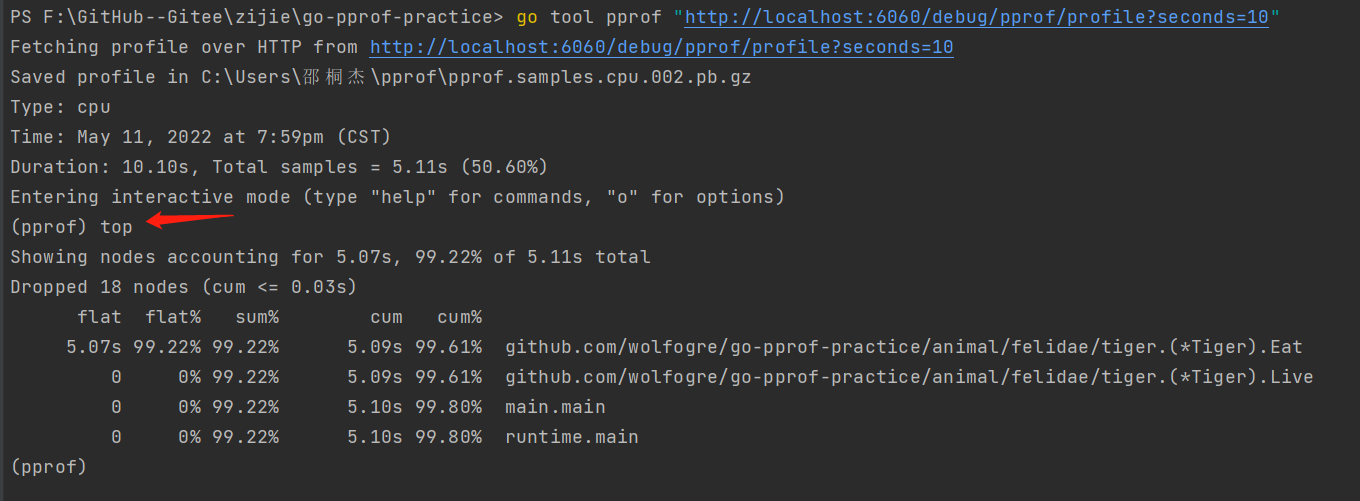
很明显github.com/wolfogre/go-pprof-practice/animal/felidae/tiger.(*Tiger).Eat的调用占用了绝大部分CPU。
输入top, 查看CPU占用最高的函数。这五列从左到右分别是:
| flat | 当前函数本身的执行耗时 |
|---|---|
| flat% | flat占CPU总时问的比例 |
| sum % | 上面每一行的flat%总和 |
| cum | 指当前函数本身加上其调用函数的总耗时 |
| cum % | cum占CPU总时间的比例 |
表格前面描述了采样的总体信息。默认会展示资源占用最高的10个函数,如果只需要查看最高的N个函数,可以输入topN, 例如查看最高的3个调用,输入top3 可以看到表格的第一行里, Tiger.Eat函数本身 占用3.56秒的CPU时间,占总时间的95.44%, 显然问题就是这里引起的
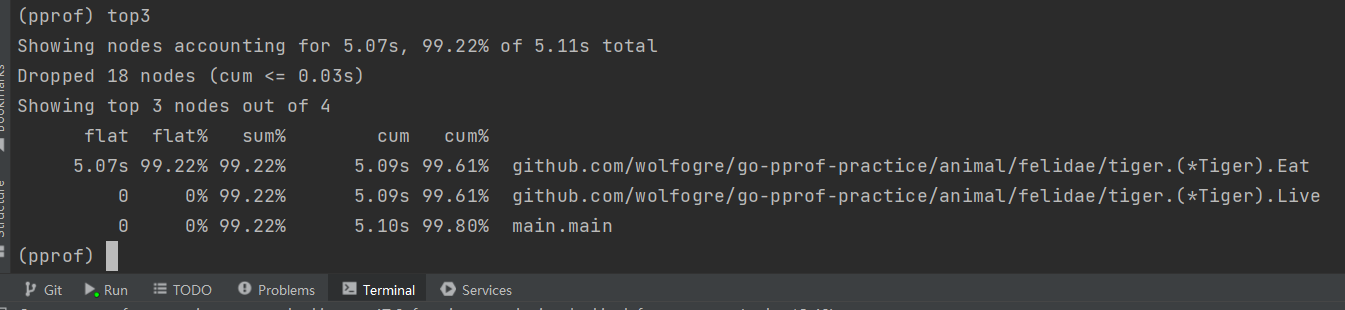
什么情况下Flat ==Cum? 什么情况下Flat ==O?
Flat == Cum,函数中没有调用其他函数 Flat == 0,函数中只有其他函数的调用
命令:list 根据指定的正则表达式查找代码行
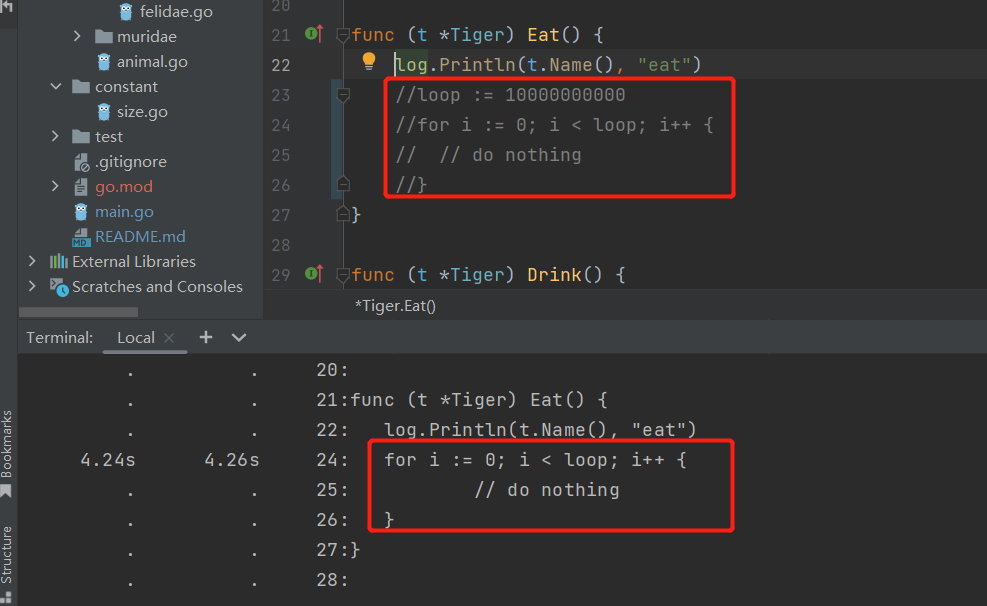
接着,输入list Eat查找这个函数,看看具体是哪里出了问题
List命令会根据后面给定的正则表达式查找代码,并按行展示出每一行的占用。可以看到,第24行有 一个100亿次的空循环,占用了5.07秒的CPU时间,问题就在这儿了,定位成功。

代码注释一下
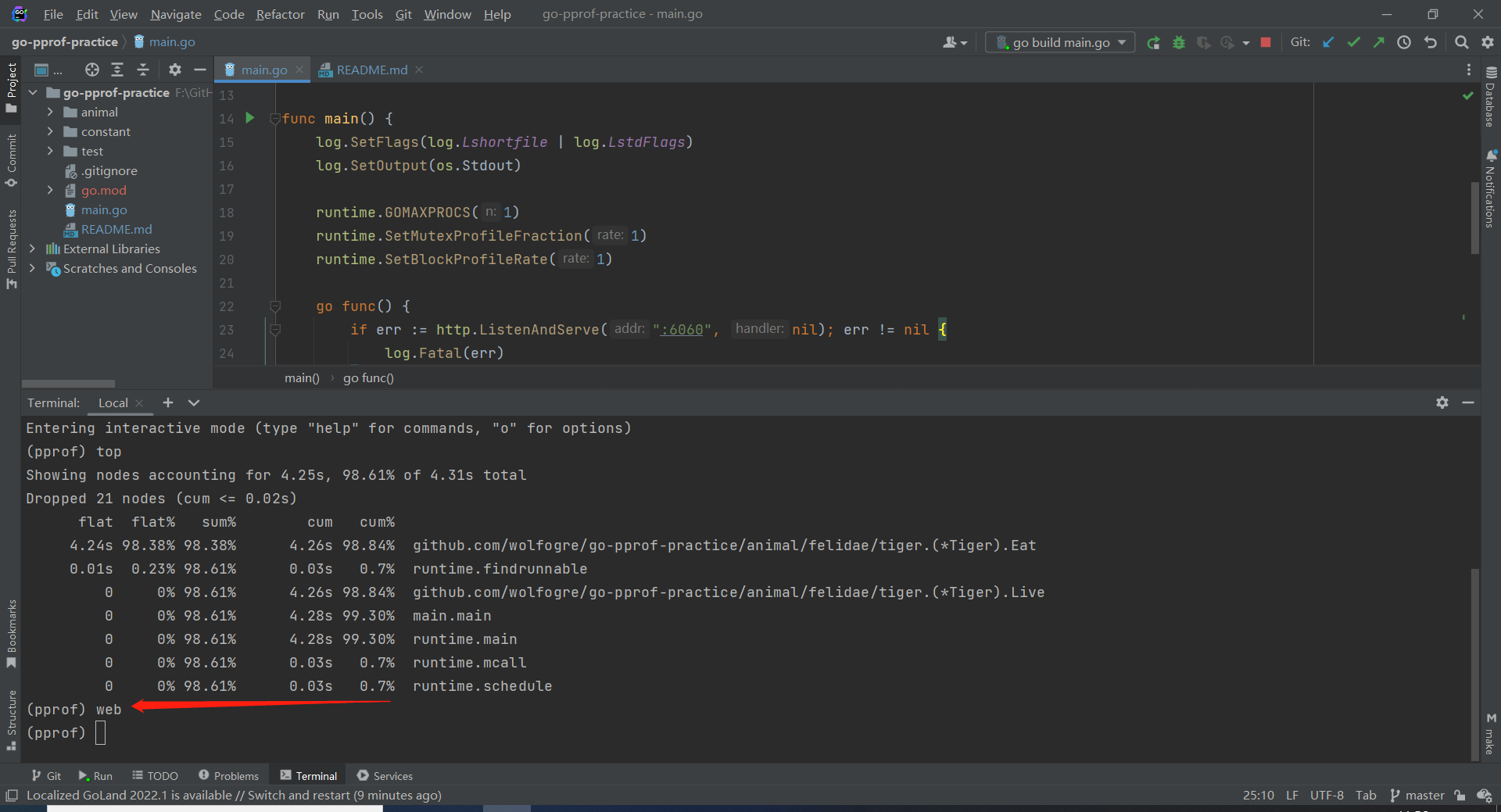
命令:web 调用关系可视化
输入
web命令,这个命令前提是需要下载graphvizgraphviz.org/download/
除了这两种视图之外,我们还可以输入web命令,生成一张调用关系图,默认会使用浏览器打开。图中除了每个节点的资源占用以外,还会将他们的调用关系穿起来。图中最明显的就是方框最红最大,线条最粗的 *Tiger.Eat函数, 是不是比top视图更直观些呢?到这里,CPU的炸弹已经定位完成,我们输入q退出终端。

为了方便后续的展示,我们先将这个「炸弹|拆除,注意这一部分我们的主 要目的是展示如何定位问题,所以不会花太多时间在看代码上,我们将问题代码直接注释掉,重新打开「炸弹」程序。
Heap-堆内存
注释CPU问题代码,重新运行后。打开活动监视器,可以发现进程的CPU已经降下来了。然而内存使用还是很高接我们来排查内存问题。
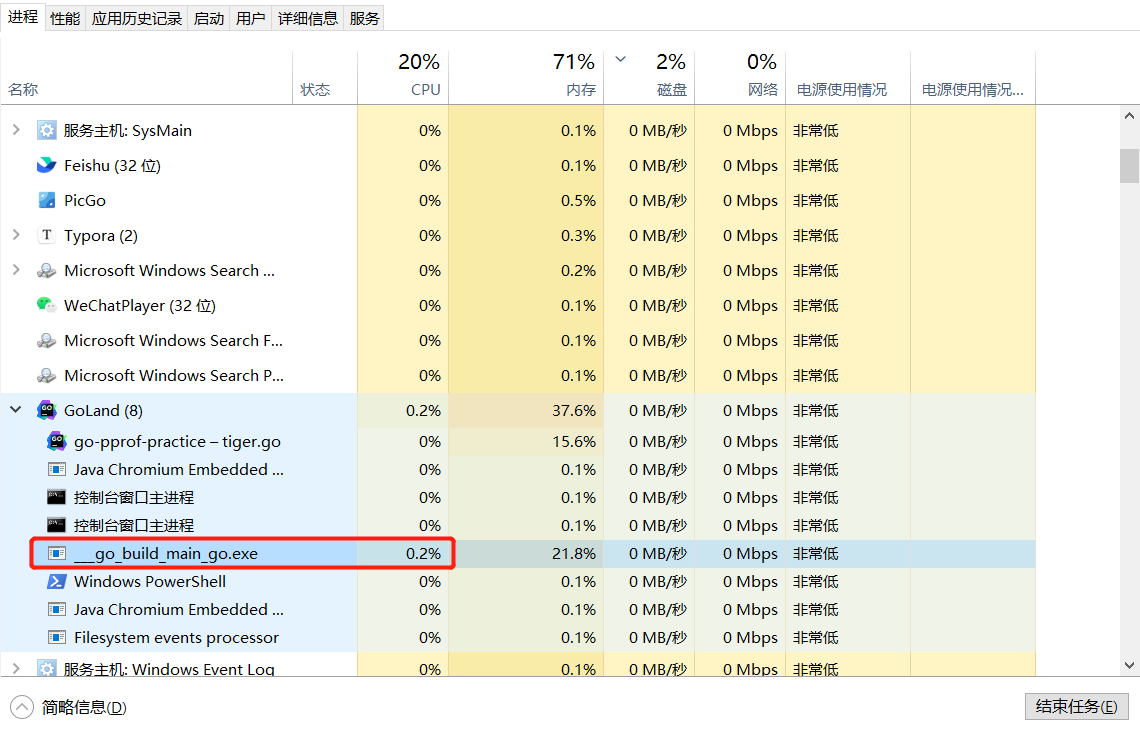
在刚刚排查CPU的过程中,我们使用的是pprof终端,这里我们介绍另一种展示方式。通过-http=:8080参数, 可以开启pprof自带的Web UI,性能指标会以网页的形式呈现。 再次启动pprof工具,注意这时的链接结尾是heap。等待采样完成后,浏览器会被自动打开,展示出熟悉的web视图,同时展示的资源使用从「CPU时间」变为了「内存占用」 可以明显看到,这里出问题的是*Mouse.Steal0函数, 它占用了1GB内存。在页面顶端的View菜单中,我们可以切换不同的视图。
go tool pprof -http=:8080 "http://localhost:6060/debug/pprof/heap“

命令输入之后,会自动跳转到http://localhost:8080/ui/ ,就可以看到如下画面了
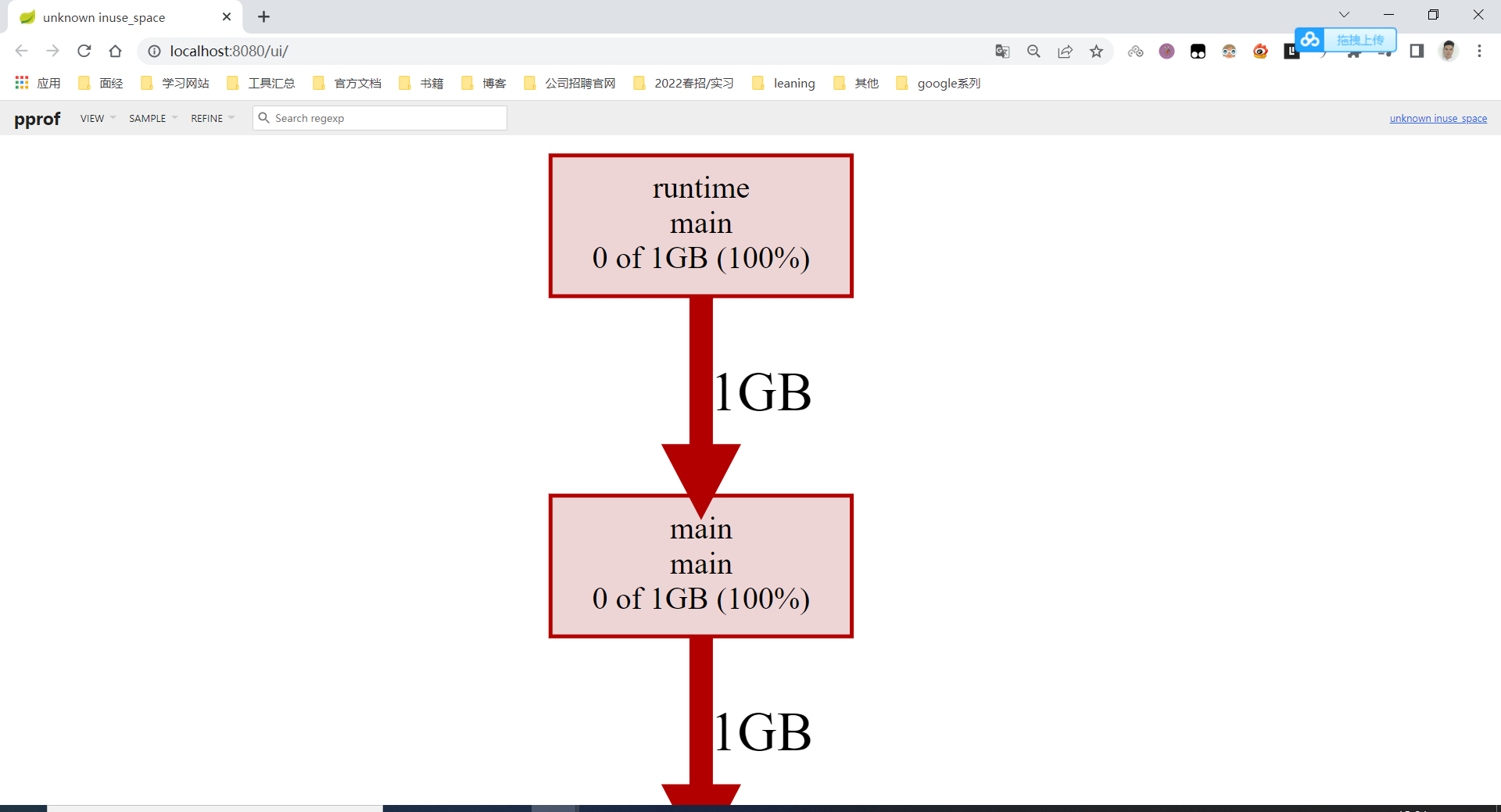
我们再切换到Source视图,可以看到页面上展示出了刚刚看到的四个调用和具体的源码视图。如果觉得内容太多,也可以在顶部的搜索框中输入Steal来使用正则表达式过滤需要的代码。
根据源码我们会发现,在*Mouse.Steal()这 函数会向固定的Buffer中不断追加1MB内存,直到Buffer达到1GB大小为止, 和我们在Graph视图中发现的情况一致。 我们将这里的问题代码注释掉,至此,「炸弹 」已被拔除了两个。

重新运行「炸弹」程序,发现内存占用已经降到了23.6MB,刚才的解决方案起效果了 在采样中,也没有出现异常节点了(实际上没有任何节点了)。不过,内存的问题真的被全部排除了吗? 大家在使用工具的过程中,有没有注意过右上角有个unknown jinuse. space
我们打开sample菜单,会发现堆内存实际上提供了四种指标:
在堆内存采样中,默认展示的是inuse_ space视图,只展示当前持有的内存, 但如果有的内存已经释放,这时inuse采样就不会展示了 。我们切换到alloc_ space指标。后续分析下alloc的内存问题
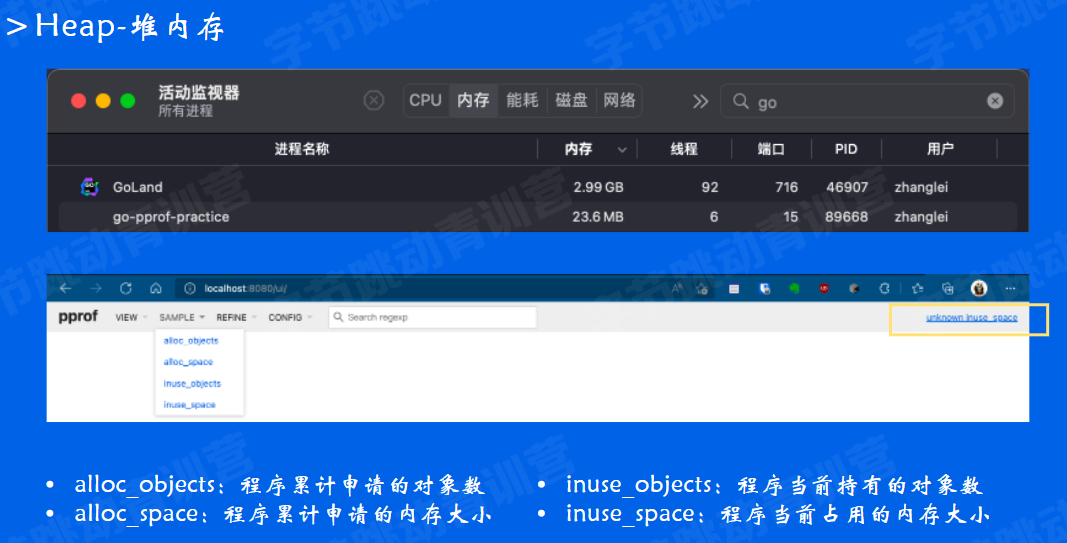
马上就定位到了*Dog.Run0中还藏着一个[炸弹」,它会 每次申请16MB大小的内存,并且已经累计申请了超过3.5GB内存。在Top视图中还能看到这个函数被内联了。
看看定位到的函数,果然,这个函数在反复申请16MB的内存,但因为是无意义的申请,分配结束之后会马上被GC,所以在inuse采样中并不会体现出来。
我们将这一行问题代码注释掉, 继续接下来的排查。至此,内存部分的「炸弹」已经被全部拆除。


github.com/wolfogre/go-pprof-practice/animal/muridae/mouse.(*Mouse).Steal
D:\Golang\GoWordPlace\pkg\mod\github.com\wolfogre\go-pprof-practice@v0.0.0-20190402114113-8ce266a210ee\animal\muridae\mouse\mouse.go
Total: 1GB 1GB (flat, cum) 100%
45 . .
46 . . func (m *Mouse) Steal() {
47 . . log.Println(m.Name(), "steal")
48 . . max := constant.Gi
49 . . for len(m.buffer) * constant.Mi < max {
50 1GB 1GB m.buffer = append(m.buffer, [constant.Mi]byte{})
51 . . }
52 . . }
runtime.main
D:\Golang\Go\src\runtime\proc.go
Total: 0 1GB (flat, cum) 100%
198 . . // A program compiled with -buildmode=c-archive or c-shared
199 . . // has a main, but it is not executed.
200 . . return
201 . . }
202 . . fn := main_main // make an indirect call, as the linker doesn't know the address of the main package when laying down the runtime
203 . 1GB fn()
204 . . if raceenabled {
205 . . racefini()
206 . . }
207 . .
208 . . // Make racy client program work: if panicking on
github.com/wolfogre/go-pprof-practice/animal/muridae/mouse.(*Mouse).Live
D:\Golang\GoWordPlace\pkg\mod\github.com\wolfogre\go-pprof-practice@v0.0.0-20190402114113-8ce266a210ee\animal\muridae\mouse\mouse.go
Total: 0 1GB (flat, cum) 100%
18 . . m.Eat()
19 . . m.Drink()
20 . . m.Shit()
21 . . m.Pee()
22 . . m.Hole()
23 . 1GB m.Steal()
24 . . }
25 . .
26 . . func (m *Mouse) Eat() {
27 . . log.Println(m.Name(), "eat")
28 . . }
main.main
F:\GitHub--Gitee\zijie\go-pprof-practice\main.go
Total: 0 1GB (flat, cum) 100%
26 . . os.Exit(0)
27 . . }()
28 . .
29 . . for {
30 . . for _, v := range animal.AllAnimals {
31 . 1GB v.Live()
32 . . }
33 . . time.Sleep(time.Second)
34 . . }
35 . .
36 . . }
goroutine-协程
goroutine泄露也会导致内存泄露
Golang是门自带垃圾回收的语言,一般情况 下内存泄露是没那么容易发生的
但是有种例外: goroutine是很容易泄露的,进而会导致内存泄露。所以接下来,我们来看看goroutine的使用情况。
打开http://ocalhost:6060/debug/pprof/ 发现「炸弹」程序已经有54条goroutine在运行了,这个量级并不是很大,但对于一个简单的小程序来说还是很不正常的。
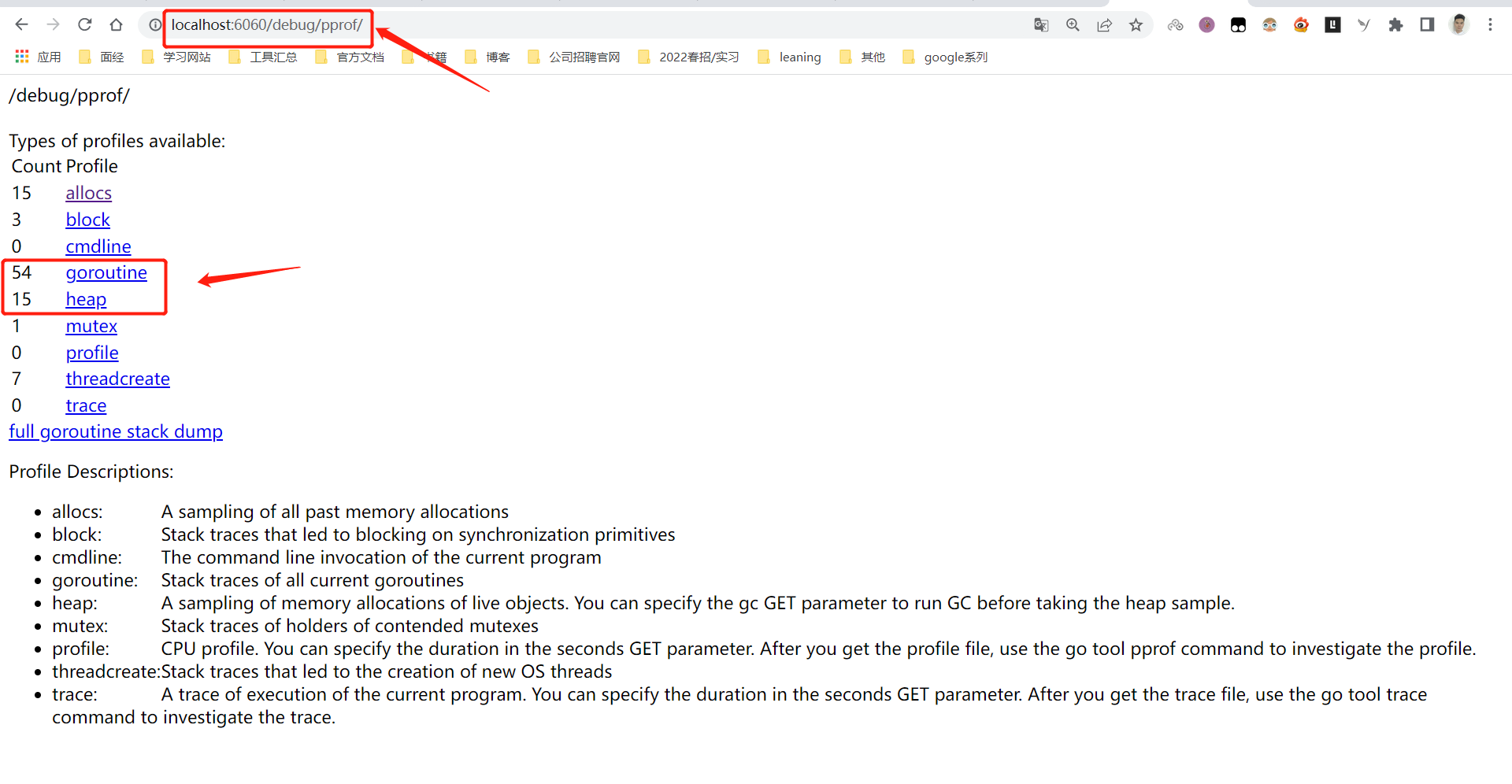
大家对链接含义应该很熟悉了,把链接末尾换成goroutine, 可以看到,pprof生成了一张非常长的调用关系图,尽管最下方的问题用红色标了出来,不过这么多节点还是比较难以阅读的。这里我们介绍另一种更加直观的展示方式一火焰图。
go tool pprof -http=:8080 "http://localhost:6060/debug/pprof/goroutine”

打开View菜单,切换到Flame Graph视图。可以看到,刚才的节点被堆叠了起来
图中,自顶向下展示了各个调用,表示各个函数调用之间的层级关系
每一行中,条形越长代表消耗的资源占比越多。显然,那些[又平又长」的节点是占用资源多的节点
可以看到,*Wolf.Drink()这 个调用创建了超过90%的goroutine,问题可能在这里
火焰图是非常常用的性能分析工具,在程序逻辑复杂的情况下很有用,可以重点熟悉
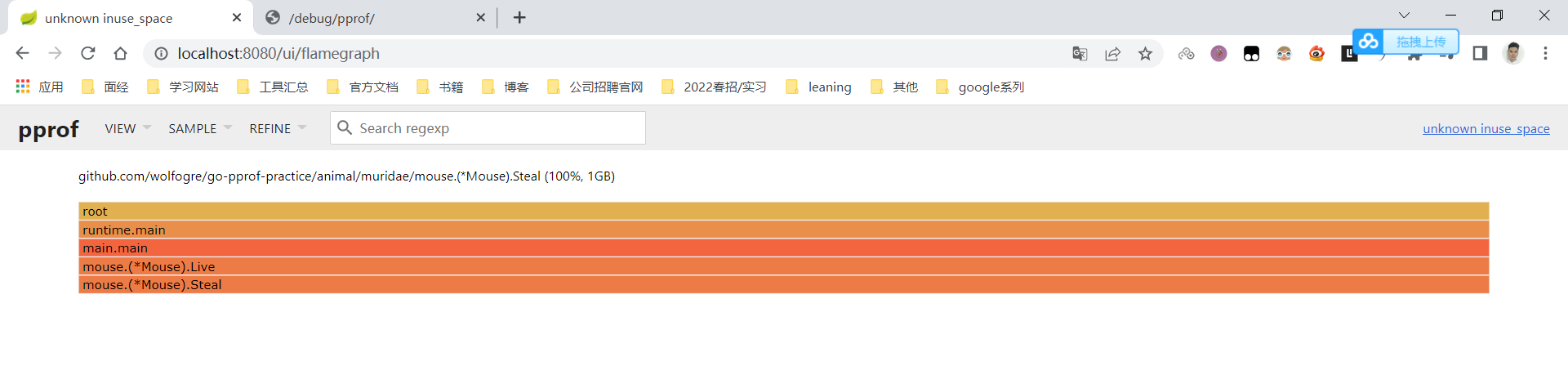
- 由上到下表示调用顺序
- 每一块代表一个函数,越长代表占用
CPU的时间更长 - 火焰图是动态的,支持点击块进行分析
这里为了模拟泄漏场景,只等待了30秒就退出了试想下,如果发起的goroutine没有退出,同时不断有新的goroutine被启动, 对应的内存占用持续增长,CPU调度压力也不断增大, 最终进程会被系统il掉
- 支持搜索,在
Source视图下搜索wolf

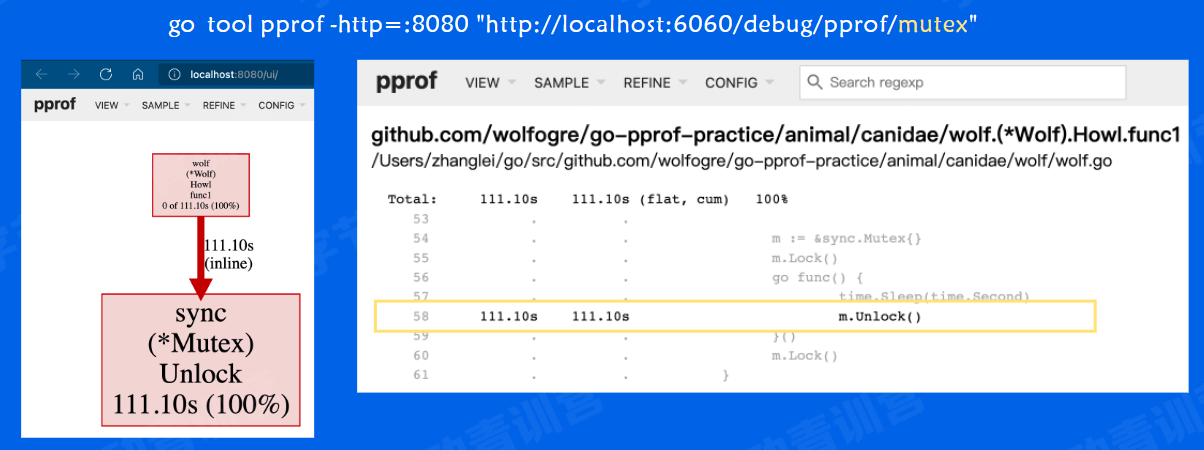
mutex-锁
修改链接后缀,改成mutex,然后打开网页观察,发现存在1个锁操作
同样地,在Graph视图中定位到出问题的函数在*Wolf.HowI()。然后在Source视图中定位到具体哪一行发生了锁竞争
在这个函数中,goroutine足足等待 了1秒才解锁,在这里阻塞住了,显然不是什么业务需求,注释掉。
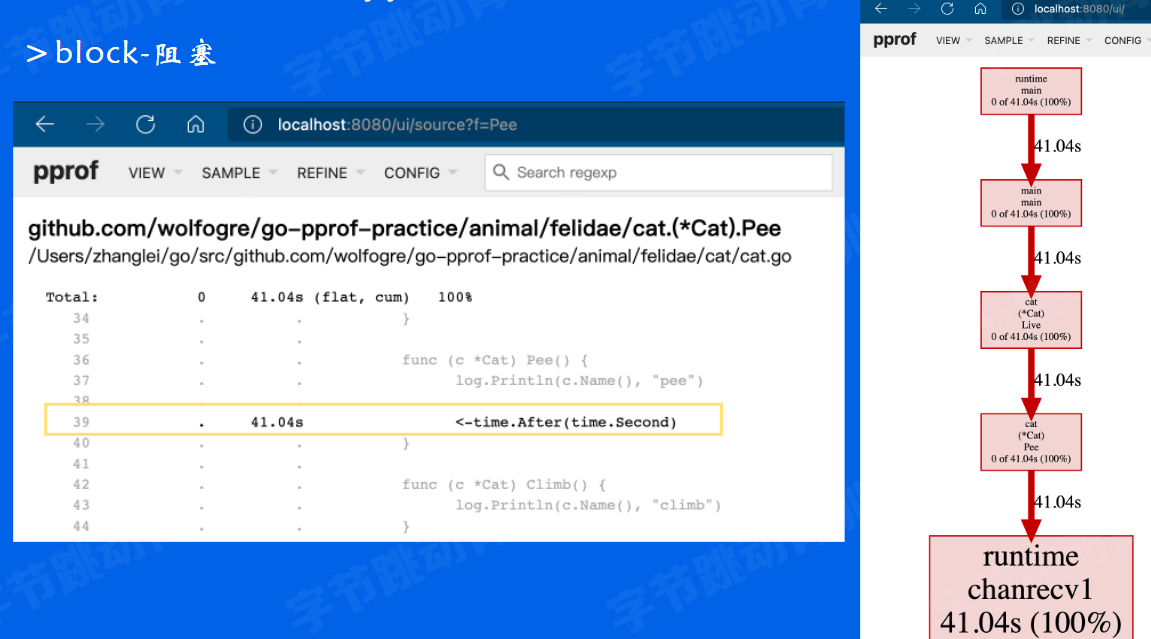
block-阻塞
浏览器访问:http://localhost:6060/debug/pprof/block
我们开始排查最后一个阻塞问题。在程序中,除了锁的竞争会导致阻塞之外,还有很多逻辑(例如读取一个channel) 也会导致阻塞,在页面中可以看到阻塞操作还剩两个强调)。链接地址末尾再换成block

和刚才一样,Graph到Source的视图切换。可以看到,在*Cat.Pee0函数中读取 了一个time.After()生成的channel,这就导致了这个goroutine实际上阻塞了1秒钟,而不是等待了1秒钟。
两个Block为什么只展示了一个
go tool pprof "http://localhost:6060/debug/pprof/block"

不过通过上面的分析,我们只定位到一个block的问题
有同学可能会发现。刚刚的计数页面上有两个阻塞操作,但是实际上只有一个, 那么另一个为什么没有展示呢?
提示,可以关注一下pprof Top视图中表格之外的部分,从框住的地方可以发现,有4个节点因为cumulative小于1.41秒被drop掉了 ,这就是另一个阻塞操作的节点,但他因为总用时小于总时长的千分之5,所以被省略掉了。这样的过滤策略能够更加有效地突出问题所在,而省略相对没有问题的信息。如果不作任何过滤全部展示的话,对于-个复杂的程序可能内容就会非常庞大了,不利于我们的问题定位。
我们知道了另-个阻塞是确实存在的,接下来大家可以进一步猜测一下:没有展示的这个阻塞操作发生在哪里? 需要点击哪个链接查看?
提示:程序除了在跑性能「炸弹」之外, 还有什么工作呢?我们是怎样访问它的采样信息的?
尽管占用低的节点不会在pprof工具中展示出来,但实际上他是被记录下来的。我们还可以通过暴露出来的接口地址直接访问它。
所以,打开Block指标的页面,可以看到,第二个阻塞操作发生在了http handler中,这个阻塞操作是符合预期的。

小结:
至此,我们已经发现了代码中存在的所有「炸弹J。以上我们介绍了五种使用pprof采集的常用性能指标: CPU、堆内存、Goroutine、 锁竞争和阻塞;
两种展示方式交 互式终端和网页:四种视图: Top、Graph、 源码和火焰图。 pprof除了http的获取方式之外,也可以直接在运行时调用runtime/pprof包将指标数据输出到本地文件。视图中还有一个更底层的[反汇编」视图。有兴趣的同学可以尝试一下它们的用法。
俗话说,知其然还要知其所以然,接下来我们来看看它们内部的实现
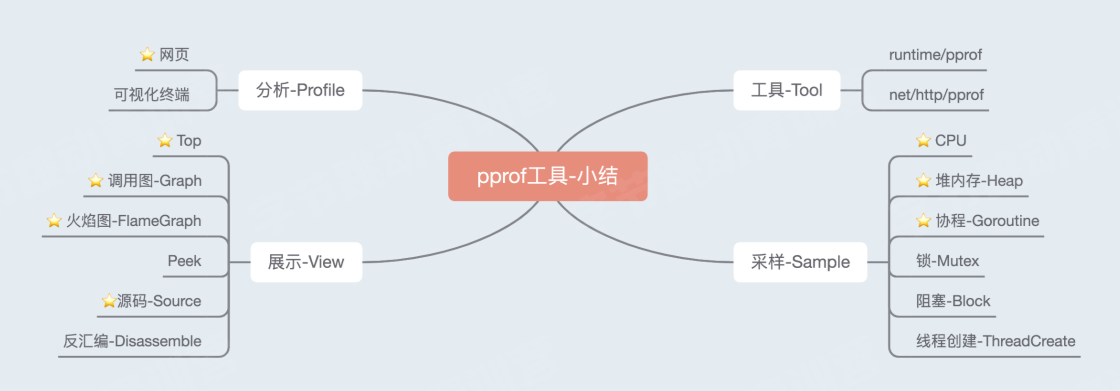
2.2.3性能分析工具pprof-采样过程和原理
首先来看CPU。CPU采样会记录所有的调用栈和它们的占用时间。
在采样时,进程会每秒暂停一百次, 每次会记录当前的调用栈信息。汇总之后,根据调用栈在采样中出现的次数来推断函数的运行时间。
你需要手动地启动和停止采样。每秒100次的暂停频率也不能更改。这个定时暂停机制在unix或类unix系统上是依赖信号机制实现的。
每次「暂停」都会接收到一个信号,通过系统计时器来保证这个信号是固定频率发送的。接下来看看具体的流程。
CPU
- 采样对象:函数调用和它们占用的时间
- 采样率: 100次/秒,固定值
- 采样时间:从手动启动到手动结束

一共有三个相关角色:进程本身、操作系统和写缓冲。
启动采样时,进程向OS注册一个定时器,OS会每隔10ms向进程发送一个SIGPROF信号, 进程接收到信号后就会对当前的调用栈进行记录。
与此同时,进程会启动一个写缓冲的goroutine,它会每隔100ms从进程中读取已经记录的堆栈信息,并写入到输出流。
当采样停止时,进程向OS取消定时器,不再接收信号,写缓冲读取不到新的堆栈时,结束输出。

接下来看看堆内存采样。 提到内存指标的时候说的都是「堆内存」而不是「内存」, 这是因为pprof的内存采样是有局限性的。
内存采样在实现上依赖了内存分配器的记录,所以它只能记录在堆上分配,且会参与GC的内存,一些其他的内存分配, 例如调用结束就会回收的栈内存、一 些 更底层使用cgo调用分配的内存,是不会被内存采样记录的。
它的采样率是一个大小, 默认每分配512KB内存会采样一 次,采样率是可以在运行开头调整的, 设为1则为每次分配都会记录。
与CPU和goroutine都不同的是,内存的采样是一个持续的过程, 它会记录从程序运行起的所有 分配或释放的内存大小和对象数量,并在采样时遍 历这些结果进行汇总。
还记得刚才的例子中,堆内存采样的四种指标吗? alloc的两项指标是从程序运行开始的累计指标,而inuse的两项指标是通过累计分配减去累计释放得到的程序当前持有的指标。你也可以通过比较两次alloc的差值来得到某一段时间程序 分配的内存[大小和数量]
Heap-堆内存
- 采样程序通过内存分配器在堆上分配和释放的内存,记录分配/释放的大小和数量
- 采样率:每分配512KB记录一次,可在运行开头修改,1为每次分配均记录
- 采样时间:从程序运行开始到采样时
- 采样指标:
alloc space,alloc objects,inuse_ space,inuse_ objects - 计算方式:
inuse = alloc- free
Goroutine-协程 & ThreadCreate-线程创建
接下来我们来看看goroutine和系统线程的采样。这两个采样指标在概念上和实现上都比较相似,所以在这里进行对比。
goroutine采样会记录所有用户发起,也就是入口不是runtime开头的goroutine, 以及main函数所在goroutine的信息和创建这些goroutine的调用栈:
他们在实现上非常的相似,都是会在STW之后,遍历所有goroutine/所有线程的列表(图中的m就是 GMP模型中的m,在golang中和线程一对应) 并输出堆栈。
最后Start The Word继续运行。这个采样是立刻触发的全量记录,你可以通过比较两个时间点的差值来得到某一时间段的指标。
-
Goroutine
- 记录所有用户发起且在运行中的
goroutine(即入口非runtime开头的) runtime.main的调用栈信息
- 记录所有用户发起且在运行中的
-
ThreadCreate
- 记录程序创建的所有系统线程的信息

Block-阻塞&Mutex-锁
阻塞和锁竞争这两种采样
这两个指标在流程和原理上也非常相似。两个采样记录的都是对应操作发生的调用栈、次数和耗时,不过这两个指标的采样率含义并不相同。
-
阻塞操作的采样率是一个「阈值」,消耗超过阈值时间的阻塞操作才 会被记录,1为每次操作都会记录。记得炸弹程序的main代码吗?里面设置了rate= 1
-
锁竞争的采样率是一个「比例」,运行时会通过随机数来只记录固定比例的锁操作, 1为每次操作都会记录。
它们在实现上也是基本相同的。都是一个「主动上报」的过程。
在阻塞操作或锁操作发生时,会计算出消耗的时间,连同调用栈一起主动上报给采样器,采样器会根据采样率可能会丢弃些记录。
在采样时,采样器会遍历已经记录的信息,统计出具体操作的次数、调用栈和总耗时。和堆内存一样,你可以对比两 个时间点的差值计算出段时间内的操作指标。
阻塞操作
- 采样阻塞操作的次数和耗时
- 采样率:阻塞耗时超过闽值的才会被记录,1为每次阻塞均记录

锁竞争
- 采样争抢锁的次数和耗时
- 采样率:只记录固定比例的锁操作,1为每次加锁均记录

2.2性能分析工具pprof
小结
- 掌握常用
pprof工具功能 - 灵活运用
pprof工具分析解决性能问题 - 了解
pprof的采样过程和工作原理
在实战过程中,虽然我们只是模拟了一个使用pprof分析性能问题的小场景,但是大部分排查思路和想法是通用的,熟悉pprof工具后, 分析真正的服务问题也会得心应手,对解决性能问题和性能调优很有帮助。
2.3性能调优素例
简介
- 介绍实际业务服务性能优化的案例
- 对逻辑相对复杂的程序如何进行性能调优
- 业务服务优化
- 基础库优化
- Go语言优化
在实际工作中,当服务规模比较小的时候,可能不会触发很多性能问题,同时性能优化带来的效果也不明显,很难体会到性能调优带来的收益。而当业务量逐渐增大,比如一个服务使用了几千台机器的时候,性能优化一个百分点,就能节省数百台机器,成本降低是非常可观的
接下来我们来了解下工程中进行性能调优的实际案例
程序从不同的应用层次上看,可以分为业务服务、基础库和Go语言本身三类,对应优化的适用范围也是越来越广
- 业务服务一般指直 接提供功能的程序,比如专门处理用户评论操作的程序
- 基础库一般指提供通用功能的程序,主要是针对业务服务提供功能,比如监控组件,负责收集业务服务的运行指标
- 另外还有对Go语言本身进行的优化项
2.3.1性能调优案例-业务服务优化
基本概念
- 服务:能单独部署,承载一定功能的程序
- 依赖:ServiceA的功能实现依赖ServiceB的响应结果,称为Service A依赖Service B
- 调用链路:能支持一个接口请求的相关服务集合及其相互之间的依赖关系
- 基础库:公共的工具包、中间件
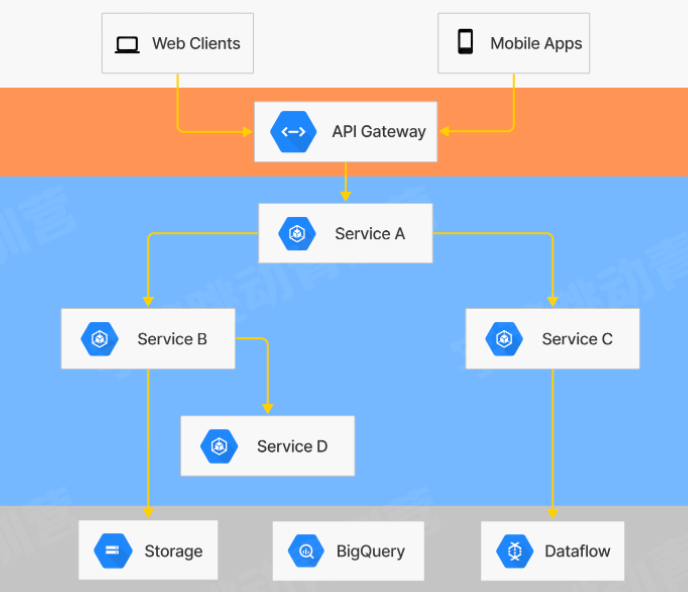
那么针对逻辑相对复杂的业务服务,它的性能调优流程是怎么样的呢?在介绍真正流程之前,可能有的同学对部分名词不太了解,先介绍一下
右边是系统部署的简单示意图,客户端请求经过网关转发,由不同的业务服务处理,业务服务可能依赖其他的服务,也可能会依赖存储、消息队列等组件。接下来我们以业务服务优化为例,说明性能调优的流程,图中的Service B被Service A依赖,同时也依赖了存储和Service D
流程
- 建立服务性能评估手段
- 分析性能数据,定位性能瓶颈
- 重点优化项改造
- 优化效果验证
那么接下来就来看一下业务服务优化的主要流程,主要分四步,这些流程也是性能调优相对通用的流程,可以适用其他场景和上面评估代码优化效果的benchmarkI具类似,对于服务的性能也需要一个评估手段和标准优化的核心是发现服务性能的瓶颈,这里主要也是用ppro采样性能数据,分析服务的表现发现瓶颈后需要进行服务改造,重构代码,使用更高效的组件等
最后一步是优化效果验证,通过压测对比和正确性验证之后,服务可以上线进行实际收益评估
整体的流程可以循环并行执行,每个优化点可能不同,可以分别评估验证
建立服务性能评估手段
-
服务性能评估方式
- 单独
benchmark无法满足复杂逻辑分析 - 不同负载情况下性能表现差异
- 单独
-
请求流量构造
- 不同请求参数覆盖逻辑不同
- 线上真实流量情况
-
压测范围
- 单机器压测
- 集群压测
性能数据采集
- 单机性能数据
- 集群性能数据
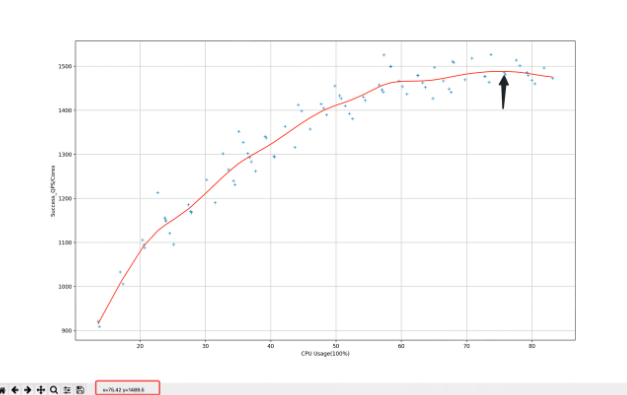
之所以不用benchmark是因为实际服务逻辑比较复杂,希望从更高的层面分析服务的性能问题,同时机器在不同负载下的性能表现也会不同,右图是负载和单核qps的对应数据。
另外因为逻辑复杂,不同的请求参数会走不同的处理逻辑,对应的性能表现也不相同,需要尽量模拟线上真实情况,分析真正的性能瓶颈 压测会录制线上的请求流量,通过控制回放速度来对服务进行测试,测试范围可以是单个实例,也可以是整个集群,同样性能采集也会区分单机和集群
建立服务性能评估手段
评估手段建立后,它的产出是什么呢?实际是一个服务的性能指标分析报告
实际的压测报告截图,会统计压测期间服务的各项监控指标,包括qps,延迟等内容,同时在压测过程中,也可以采集服务的ppro数据,使用之前的方式分析性能问题

分析性能数据,定位性能瓶颈
使用库不规范
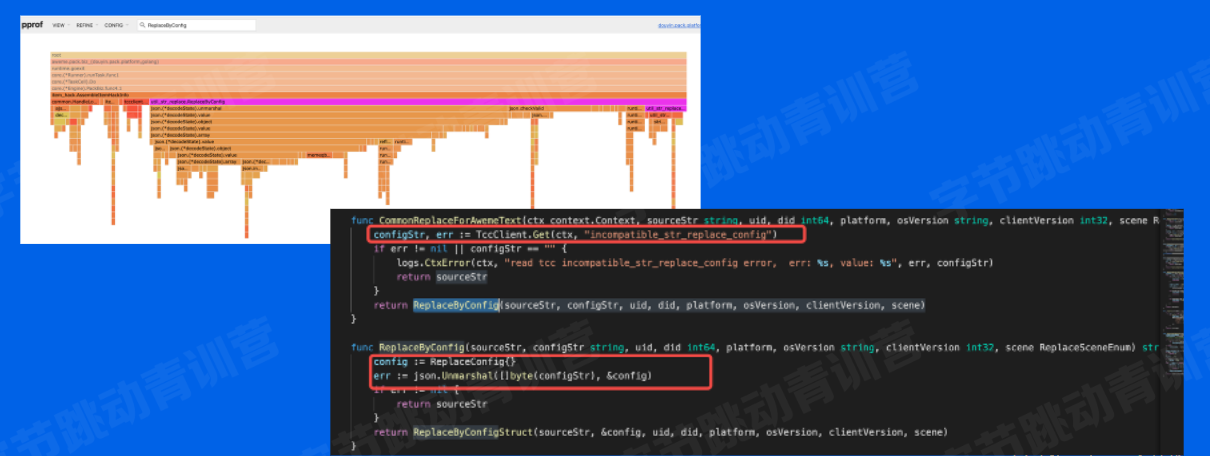
有了服务优化前的性能报告和一些性能采样数据, 我们可以进行性能瓶颈分析了业务服务常见的性能问题可能是使用基础组件不规范
比如这里通过火焰图看出json的解析部分占用了较多的CPU资源,那么我们就能定位到具体的逻辑代码,是在每次使用配置时都会进行json解析, 拿到配置项,实际组件内部提供了缓存机制,只有数据变更的时候才需要重新解析json
还有是类似日志使用不规范,一部分是调试日志发布到线上,一部分是线上服务在不同的调用链路上数据有差别,测试场景日志量还好,但是到了真实线上全量场景,会导致日志量增加,影响性能

高并发场景优化不足
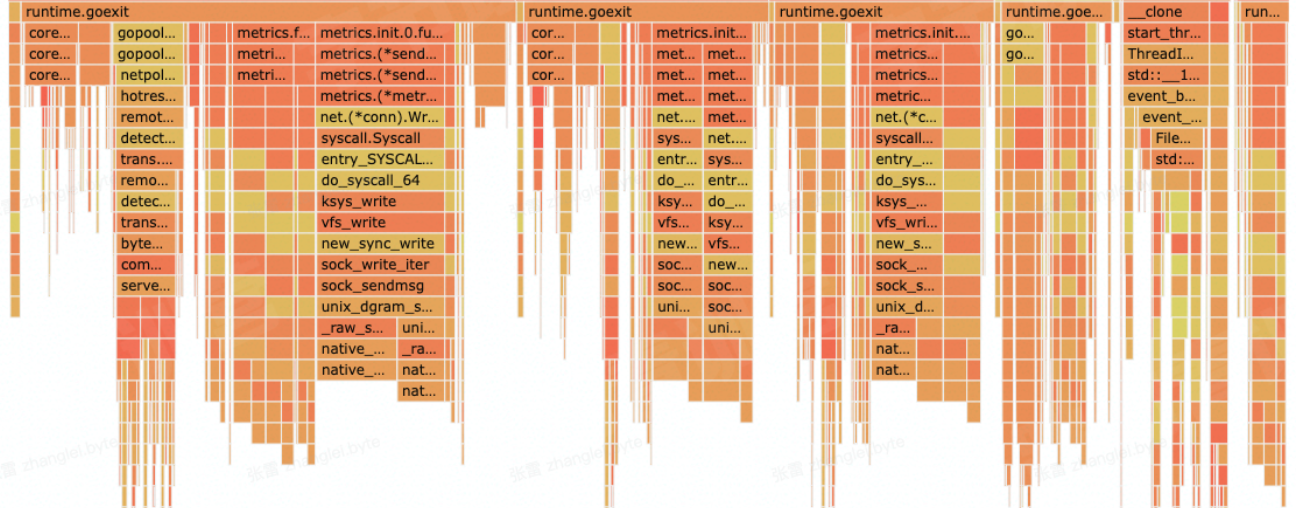
另外常见的性能问题就是高并发场景的优化不足,左边是服务高峰期的火焰图,右边是低峰期的火焰图,可以发现metrics, 即监控组件的CPU资源占用变化较大,主要原因是监控数据上报是同步请求,在请求量上涨,监控打点数据量增加时,达到性能瓶颈,造成阻塞,影响业务逻辑的处理,后续是改成异步上报的机制提升了性能

重点优化项改造
- 正确性是基础
- 响应数据diff
- 线上请求数据录制回放
- 新旧逻辑接口数据diff

定位到性能瓶颈后,我们也有了对应的修复手段,但是修改完后能直接发布上线吗? 性能优化的前提是保证正确性,所以在变动较大的性能优化上线之前,还需要进行正确性验证,因为线上的场景和流程太多,所以要借助自动化手段来保证优化后程序的正确性
同样是线上请求的录制,不过这里不仅包含请求参数录制,还会录制线上的返回内容,重放时对比线上的返回内容和优化后服务的返回内容进行正确性验证。比如图中作者信息相关的字段值在优化有有变化,需要进一步排查原因
优化效果验证
- 重复压测验证
- 上线评估优化效果
- 关注服务监控
- 逐步放量
- 收集性能数据
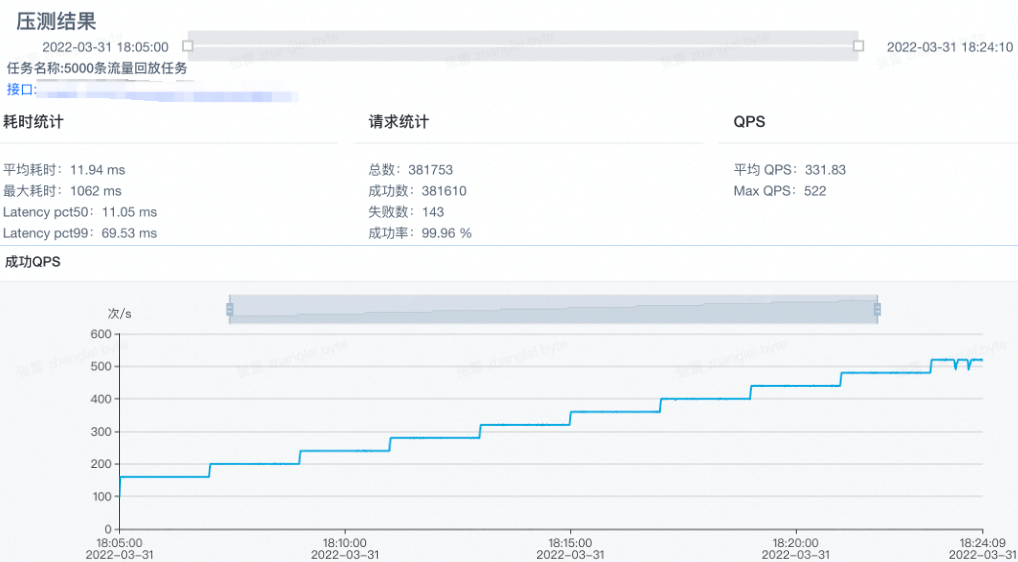
改造完成后,可以进行优化效果验证了
验证分两部分,首先依然是用同样的数据对优化后的服务进行压测,可以看到现在的数据比优化前好很多,能够支持更多的qps 正式上线的时候会逐步放量,记录真正的优化效果。同时压测并不能保证和线上表现完全一致, 有时还要通过线上的表现再进行分析改进,是个长期的过程
进一步优化,服务整体链路分析
- 规范上游服务调用接口
- 明确场景需求,分析链路,通过业务流程优化提升服务性能
以上的内容是针对单个服务的优化过程,从更高的视角看,性能是不是还有优化空间? 在熟悉服务的整体部署情况后,可以针对具体的接口链路进行分析调优。比如Service A调用Service B是否存在重复调用的情况,调用Service B服务时,是否更小的结果数据集就能满足需求,接口是否一定要实时数据,能否在Service A层进行缓存,减轻调用压力
这种优化只使用与特定业务场景,适用范围窄 ,不过能更合理的利用资源
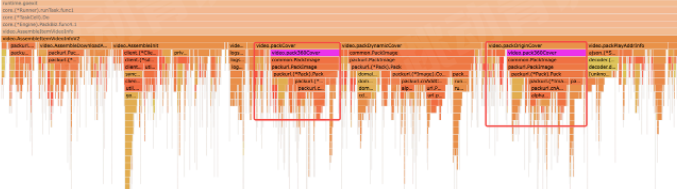

2.3.2性能调优素例-基础库优化
AB实验SDK的优化
-
分析基础库核心逻辑和性能瓶颈
- 设计完善改造方案
- 数据按需获取
- 数据序列化协议优化
-
内部压测验证
-
推广业务服务落地验证
适用范围更广的就是基础库的优化
比如在实际的业务服务中,为了评估某些功能上线后的效果,经常需要进行AB实验,看看不同策略对核心指标的影响,所以公司内部多数服务都会使用AB实验的SDK,如果能优化AB组件库的性能,所有用到的服务都会有性能提升
类似业务服务的优化流程,也会先统计下各个服务中AB组件的资源占用情况,看看AB组件的哪些逻辑更耗费资源,提取公共问题进行重点优化
图中看到有部分性能耗费在序列化上,因为AB相关的数据量较大,所以在制定优化方案时会考虑优化数据序列化协议,同时进行按需加载,只处理服务需要的数据。完成改造和内部压测验证后,会逐步选择线上服务进行试点放量,发现潜在的正确性和使用上的问题,不断迭代后推广到更多服务
编译器&运行时优化
- 优化内存分配策略
- 优化代码编译流程,生成更高效的程序
- 内部压测验证
- 推广业务服务落地验证
- 优点
- 接入简单,只需要调整编译配置
- 通用性强
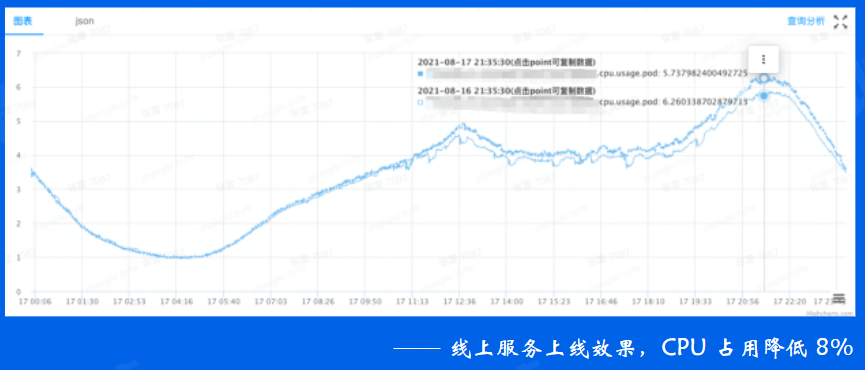
接下来是适用范围最广的优化,就是针对Go本身进行的优化,会优化编译器和运行时的内存分配策略,构建更高效的go发行版本
这样的优化业务服务接入非常简单,只要调整编译配置即可,通用性很强,几乎对所有go的程序都会生效, 比如右图中服务只是换用新的发行版本进行编译,CPU占用降低8%
参考:1. 【Go 语言原理与实践学习资料】第三届字节跳动青训营-后端专场:juejin.cn/post/709372… 2. 《Go 语言教程》:www.runoob.com/go/go-tutor…
