

上一篇文章介绍了HTTP协议相关的理论基础,今天来一起看下HTTP的缓存。缓存的作用不言而喻,它可以改善网页性能,提高用户体验。一起来学习一下HTTP的缓存机制。
什么是缓存
当浏览器加载一个页面时html引用的外部资源也会加载。但这些外部资源比如图片、css、js都不经常变化。如果每次都加载这些资源会造成资源的浪费,而且加载时间也会影响用户体验。
HTTP缓存技术就是为了解决这个问题出现的。需要HTTP和浏览器之间相互配合来实现缓存机制。
简单的说,HTTP缓存就是浏览器对之前请求过的静态资源进行缓存,下次请求相同资源时可以直接使用,无需向服务器请求资源,节省带宽,提高访问速度,降低服务器压力。
当然,什么时候需要直接使用浏览器缓存的资源,什么时候不使用,有一系列的策略保证如果资源一旦更新,存储也要随之更新。
浏览器缓存
第一次必须获取到资源后,然后根据返回的信息来告诉如何缓存资源,可能采用的是强缓存,也可能告诉客户端浏览器是协商缓存,这都需要根据响应的header内容来决定的。
浏览器第一请求时:
浏览器后续请求时:
从上图可以看出,浏览器缓存包含两种类型,强缓存和协商缓存。
- 浏览器在第一次请求后,再次请求时:
- 浏览器在请求某一资源时,会先获取该资源缓存的header信息,判断是否命中强缓存(cache-control和expires信息),若命中直接从缓存中获取资源信息,包括缓存header信息;本次请求根本就不会与服务器进行通信。
- 如果没有命中强缓存,浏览器会发送请求到服务器,请求会携带第一次请求返回的有关缓存的header字段信息(Last-Modified/If-Modified-Since和Etag/If-None-Match),由服务器根据请求中的相关header信息来比对结果是否协商缓存命中。若命中,则服务器返回新的响应header信息更新缓存中的对应header信息,但是并不返回资源内容,它会告知浏览器可以直接从缓存获取;否则返回最新的资源内容。
强缓存和协商缓存区别
| 获取资源形式 | 状态码 | 发送请求到服务器 | |
|---|---|---|---|
| 强缓存 | 从缓存取 | 200(from cache) | 否,直接从缓存取 |
| 协商缓存 | 从缓存取 | 304(not modified) | 是,正如其名,通过服务器来告知缓存是否可用 |
强缓存相关的Header
强缓存就是直接从缓存中获取资源,而不用向服务器发送请求,与强缓存相关的header字段有两个:
expires
expires,这是http1.0时的规范;它的值为一个绝对时间的GMT格式的时间字符串,如Mon, 10 Jun 2021 21:31:12 GMT,如果发送请求的时间在expires之前,那么本地缓存始终有效,否则就会发送请求到服务器来获取资源。
expires: Mon, 10 Jun 2021 21:31:12 GMT
expires是一个时间戳,而且是一个绝对时间值。这就会产生一个问题,浏览器发送请求时使用客户端的时间和这个过期时间进行对比,客户端时间可能和服务器端时间不一致,而且客户端的时候还能自行修改,如果这样的话,可能就达不到我们预期的效果。
代码验证
server端代码:
const http = require('http');
function updateTime(){
let time = new Date().toUTCString();
return time;
}
const server = http.createServer((req, res) => {
console.log('url:', `${req.method} ${req.url} `);
const { url } = req;
if ('/' === url) {
res.end(`
<html>
<!-- <meta http-equiv="Refresh" content="5" /> -->
Html Update Time: ${updateTime()}
<script src='main.js'></script>
</html>
`);
} else if (url === '/main.js') {
const content = `document.writeln('<br>JS Update Time:${updateTime()}')`;
// expires
res.setHeader("expires", (new Date(Date.now() + 5000).toUTCString()));
res.statusCode = 200;
res.end(content);
} else if (url === '/favicon.ico') {
console.log('favicon..');
res.end('');
}
});
server.listen(3000, () => {
console.log('server is running at 3000...')
});
第一次访问main.js,可以看到response header中有我们指定的expires(5秒后失效)。
紧接着第二次访问main.js,由于还在有效期内,所以直接从缓存中取。
5秒后,再次访问,由于过了有效期,则向服务器重新请求。
cache-control
cache-control:max-age=number,正是由于上面说的问题,HTTP1.1新增了这个header来解决问题。这是HTTP1.1时出现的header信息,主要是利用该字段的max-age值来进行判断,它是一个相对值;资源第一次的请求时间和Cache-Control设定的有效期,计算出一个资源过期时间,再拿这个过期时间跟当前的请求时间比较,如果请求时间在过期时间之前,就能命中缓存,否则就不行;cache-control除了该字段外,还有下面几个比较常用的设置值:
-
- no-cache:不使用本地缓存。需要使用缓存协商,先与服务器确认返回的响应是否被更改,如果之前的响应中存在ETag,那么请求的时候会与服务端验证,如果资源未被更改,则可以避免重新下载。
- no-store:直接禁止游览器缓存数据,每次用户请求该资源,都会向服务器发送一个请求,每次都会下载完整的资源。
- public:可以被所有的用户缓存,包括终端用户和CDN等中间代理服务器。
- private:只能被终端用户的浏览器缓存,不允许CDN等中继缓存服务器对其缓存。
注意:
如果cache-control和expires同时存在的话,cache-control的优先级高于expires。
代码验证
- 验证max-age,no-cache,no-store;
// expires
// res.setHeader("expires", (new Date(Date.now() + 5000).toUTCString()));
// cache control
res.setHeader("cache-control", "max-age=5");
max-age设置5秒后过期。
// cache control
// res.setHeader("cache-control", "max-age=5");
res.setHeader("cache-control", "no-cache");
// res.setHeader("cache-control", "no-store");
no-cache需要进行协商缓存,到后面的例子再看协商缓存的情况。
- 验证优先级;
// expires
res.setHeader("expires", (new Date(Date.now() + 5000).toUTCString()));
// cache control
res.setHeader("cache-control", "max-age=2");
可以看出,缓存在2秒后失效,而不是5秒。
协商缓存相关的header
协商缓存是由服务器来确定缓存资源是否可用的,所以客户端与服务器端要通过某种标识来进行通信,从而让服务器判断请求资源是否可以缓存访问,这主要涉及到下面两组header字段。
- Last-Modified 和 If-Modified-Since;
- Etag 和 If-None-Match;
这两组搭档都是成对出现的,即第一次请求的响应头带上某个字段(Last-Modified或者Etag),则后续请求则会带上对应的请求字段(If-Modified-Since或者),若响应头没有Last-Modified或者Etag字段,则请求头也不会有对应的字段。
Last-Modified/If-Modified-Since 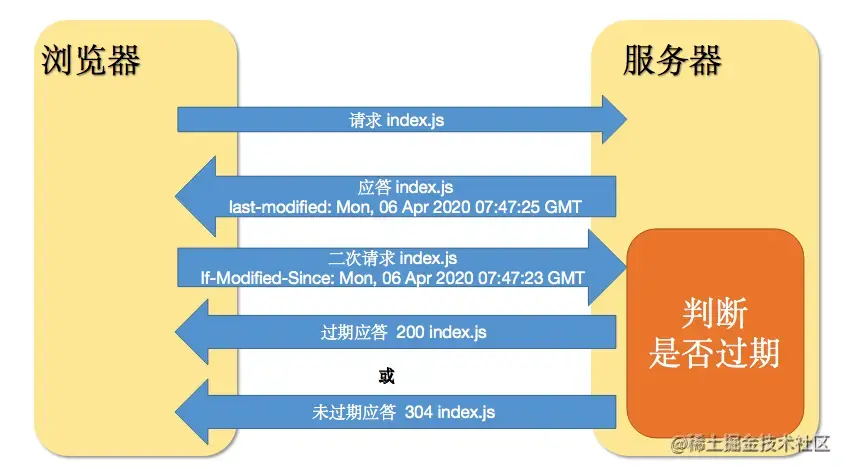
这两个的值都是GMT格式的时间字符串,具体过程:
-
浏览器第一次跟服务器请求一个资源,服务器在返回这个资源的同时,在respone的header加上Last-Modified的header,这个header表示这个资源在服务器上的最后修改时间;
-
浏览器再次跟服务器请求这个资源时,在request的header上加上If-Modified-Since的header,这个header的值就是上一次请求时返回的Last-Modified的值;
-
服务器再次收到资源请求时,根据浏览器传过来If-Modified-Since和资源在服务器上的最后修改时间判断资源是否有变化,如果没有变化则返回304 Not Modified,但是不会返回资源内容;如果有变化,就正常返回资源内容。当服务器返回304 Not Modified的响应时,response header中不会再添加Last-Modified的header,因为既然资源没有变化,那么Last-Modified也就不会改变,这时服务器返回304时的response header;
-
浏览器收到304的响应后,就会从缓存中加载资源;
-
如果协商缓存没有命中,浏览器直接从服务器加载资源时,Last-Modified的Header在重新加载的时候会被更新,下次请求时,If-Modified-Since会启用上次返回的Last-Modified值;
代码验证
{
"name": "cache",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo "Error: no test specified" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"devDependencies": {
},
"dependencies": {
"express": "^4.17.3",
"http": "0.0.1-security"
}
}
// last-modified
res.setHeader("last-modified", new Date().toUTCString());
if (new Date(req.headers["if-modified-since"]).getTime() + 3000 > Date.now()) {
// 协商缓存
console.log("命中协商缓存!");
res.statusCode = 304;
res.end();
return;
}
Etag/If-None-Match
这两个值是由服务器生成的每个资源的唯一标识字符串,只要资源有变化就这个值就会改变;其判断过程与Last-Modified/If-Modified-Since类似,与Last-Modified不一样的是,当服务器返回304 Not Modified的响应时,由于ETag重新生成过,response header中还会把这个ETag返回,即使这个ETag跟之前的没有变化。
代码验证
// etag
const etag = "ckjwn12mcsq";
res.setHeader("Etag", etag);
if (req.headers["if-none-match"] === etag) {
// 协商缓存
console.log("Etag命中协商缓存!");
res.statusCode = 304;
res.end();
return;
}
Last-Modified和Etag
到这里,大家肯定会有疑问,既然有了Last-modified可以实现协商缓存,那为什么还需要Etag呢??
这是因为,Last-modified在一些场景下会有一些问题:
-
一些文件也许会周期性的更改,但是他的内容并不改变(仅仅改变的修改时间),这个时候我们并不希望客户端认为这个文件被修改了,而重新GET;
比如:一些场景下需要在资源末尾添加一些标识,使用完后又把标识删除,但这些资源内容并没有改变。 -
某些文件修改非常频繁,比如在秒以下的时间内进行修改,(比方说1s内修改了N次),If-Modified-Since能检查到的粒度是s级的;
-
某些服务器不能精确的得到文件的最后修改时间;
这时,利用Etag能够更加准确的控制缓存,因为Etag是服务器自动生成或者由开发者生成的对应资源在服务器端的唯一标识符。
Last-Modified与ETag是可以一起使用的, 服务器会优先验证ETag ,一致的情况下,才会继续比对Last-Modified,最后才决定是否返回304。
ajax缓存
Ajax通常会分为Get、Post、Put、Delete等情况,其中Get操作通常会用作哪些不会改变的服务状态的操作。缓存机制依然会沿用HTTP缓存的处理方式。
用户行为对缓存的影响
强缓存如何重新加载缓存过的资源
使用强缓存时,浏览器不会发送请求到服务端,根据设置的缓存时间浏览器一直从缓存中获取资源,在这期间若资源产生了变化,浏览器就在缓存期内就一直得不到最新的资源,那么如何防止这种事情发生呢?
在日常开发中,webpack每次打包会生成新的hash,从而使浏览器对旧文件的缓存失效。
