

1. DataFrameReader是什么?
目标
- 理解
DataFrameReader的整体结构和组成
SparkSQL 的一个非常重要的目标就是完善数据读取, 所以 SparkSQL 中增加了一个新的框架, 专门用于读取外部数据源, 叫做 DataFrameReader
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.DataFrameReader
val spark: SparkSession = ...
val reader: DataFrameReader = spark.read
DataFrameReader 由如下几个组件组成
| 组件 | 解释 |
|---|---|
schema | 结构信息, 因为 Dataset 是有结构的, 所以在读取数据的时候, 就需要有 Schema 信息, 有可能是从外部数据源获取的, 也有可能是指定的 |
option | 连接外部数据源的参数, 例如 JDBC 的 URL, 或者读取 CSV 文件是否引入 Header 等 |
format | 外部数据源的格式, 例如 csv, jdbc, json 等 |
DataFrameReader 有两种访问方式, 一种是使用 load 方法加载, 使用 format 指定加载格式, 还有一种是使用封装方法, 类似 csv, json, jdbc 等
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.DataFrame
val spark: SparkSession = ...
// 使用 load 方法
val fromLoad: DataFrame = spark
.read
.format("csv")
.option("header", true)
.option("inferSchema", true)
.load("dataset/BeijingPM20100101_20151231.csv")
// Using format-specific load operator
val fromCSV: DataFrame = spark
.read
.option("header", true)
.option("inferSchema", true)
.csv("dataset/BeijingPM20100101_20151231.csv")
但是其实这两种方式本质上一样, 因为类似 csv 这样的方式只是 load 的封装
如果使用 load 方法加载数据, 但是没有指定 format 的话, 默认是按照 Parquet 文件格式读取也就是说, SparkSQL 默认的读取格式是 Parquet |
|---|
总结
- 使用
spark.read可以获取 SparkSQL 中的外部数据源访问框架DataFrameReader DataFrameReader有三个组件format,schema,optionDataFrameReader有两种使用方式, 一种是使用load加format指定格式, 还有一种是使用封装方法csv,json等
2. 初识 DataFrameWriter
目标
- 理解
DataFrameWriter的结构
对于 ETL 来说, 数据保存和数据读取一样重要, 所以 SparkSQL 中增加了一个新的数据写入框架, 叫做 DataFrameWriter
val spark: SparkSession = ...
val df = spark.read
.option("header", true)
.csv("dataset/BeijingPM20100101_20151231.csv")
val writer: DataFrameWriter[Row] = df.write
DataFrameWriter 中由如下几个部分组成
| 组件 | 解释 |
|---|---|
source | 写入目标, 文件格式等, 通过 format 方法设定 |
mode | 写入模式, 例如一张表已经存在, 如果通过 DataFrameWriter 向这张表中写入数据, 是覆盖表呢, 还是向表中追加呢? 通过 mode 方法设定 |
extraOptions | 外部参数, 例如 JDBC 的 URL, 通过 options, option 设定 |
partitioningColumns | 类似 Hive 的分区, 保存表的时候使用, 这个地方的分区不是 RDD 的分区, 而是文件的分区, 或者表的分区, 通过 partitionBy 设定 |
bucketColumnNames | 类似 Hive 的分桶, 保存表的时候使用, 通过 bucketBy 设定 |
sortColumnNames | 用于排序的列, 通过 sortBy 设定 |
mode 指定了写入模式, 例如覆盖原数据集, 或者向原数据集合中尾部添加等
Scala 对象表示 | 字符串表示 | 解释 |
|---|---|---|
SaveMode.ErrorIfExists | "error" | 将 DataFrame 保存到 source 时, 如果目标已经存在, 则报错 |
SaveMode.Append | "append" | 将 DataFrame 保存到 source 时, 如果目标已经存在, 则添加到文件或者 Table 中 |
SaveMode.Overwrite | "overwrite" | 将 DataFrame 保存到 source 时, 如果目标已经存在, 则使用 DataFrame 中的数据完全覆盖目标 |
SaveMode.Ignore | "ignore" | 将 DataFrame 保存到 source 时, 如果目标已经存在, 则不会保存 DataFrame 数据, 并且也不修改目标数据集, 类似于 CREATE TABLE IF NOT EXISTS |
DataFrameWriter 也有两种使用方式, 一种是使用 format 配合 save, 还有一种是使用封装方法, 例如 csv, json, saveAsTable 等
val spark: SparkSession = ...
val df = spark.read
.option("header", true)
.csv("dataset/BeijingPM20100101_20151231.csv")
// 使用 save 保存, 使用 format 设置文件格式
df.write.format("json").save("dataset/beijingPM")
// 使用 json 保存, 因为方法是 json, 所以隐含的 format 是 json
df.write.json("dataset/beijingPM1")
默认没有指定 format, 默认的 format 是 Parquet |
|---|
总结
- 类似
DataFrameReader,Writer中也有format,options, 另外schema是包含在DataFrame中的 DataFrameWriter中还有一个很重要的概念叫做mode, 指定写入模式, 如果目标集合已经存在时的行为DataFrameWriter可以将数据保存到Hive表中, 所以也可以指定分区和分桶信息
3. 读写 Parquet 格式文件
目标
- 理解
Spark读写Parquet文件的语法 - 理解
Spark读写Parquet文件的时候对于分区的处理
什么时候会用到 Parquet ?
在 ETL 中, Spark 经常扮演 T 的职务, 也就是进行数据清洗和数据转换.
为了能够保存比较复杂的数据, 并且保证性能和压缩率, 通常使用 Parquet 是一个比较不错的选择.
所以外部系统收集过来的数据, 有可能会使用 Parquet, 而 Spark 进行读取和转换的时候, 就需要支持对 Parquet 格式的文件的支持.
使用代码读写 Parquet 文件
默认不指定 format 的时候, 默认就是读写 Parquet 格式的文件
val spark: SparkSession = new sql.SparkSession.Builder()
.appName("hello")
.master("local[6]")
.getOrCreate()
val df = spark.read
.option("header", value = true)
.csv("dataset/911.csv")
// 保存 Parquet 文件
df.write.mode("override").save("dataset/911.parquet")
// 读取 Parquet 文件
val dfFromParquet = spark.read.parquet("dataset/911.parquet")
dfFromParquet.createOrReplaceTempView("911")
spark.sql("select * from 911 where zip > 19000 and zip < 19400").show()
写入 Parquet 的时候可以指定分区
Spark 在写入文件的时候是支持分区的, 可以像 Hive 一样设置某个列为分区列
val spark: SparkSession = new sql.SparkSession.Builder()
.appName("hello")
.master("local[6]")
.getOrCreate()
// 从 CSV 中读取内容
val dfFromParquet = spark.read.option("header", value = true).csv("dataset/BeijingPM20100101_20151231.csv")
// 保存为 Parquet 格式文件, 不指定 format 默认就是 Parquet
dfFromParquet.write.partitionBy("year", "month").save("dataset/beijing_pm")
这个地方指的分区是类似 Hive 中表分区的概念, 而不是 RDD 分布式分区的含义 |
|---|
分区发现
在读取常见文件格式的时候, Spark 会自动的进行分区发现, 分区自动发现的时候, 会将文件名中的分区信息当作一列. 例如 如果按照性别分区, 那么一般会生成两个文件夹 gender=male 和 gender=female, 那么在使用 Spark 读取的时候, 会自动发现这个分区信息, 并且当作列放入创建的 DataFrame 中
使用代码证明这件事可以有两个步骤, 第一步先读取某个分区的单独一个文件并打印其 Schema 信息, 第二步读取整个数据集所有分区并打印 Schema 信息, 和第一步做比较就可以确定
val spark = ...
val partDF = spark.read.load("dataset/beijing_pm/year=2010/month=1")
partDF.printSchema()
| 把分区的数据集中的某一个区单做一整个数据集读取, 没有分区信息, 自然也不会进行分区发现 |
|---|
val df = spark.read.load("dataset/beijing_pm")
df.printSchema()
| 此处读取的是整个数据集, 会进行分区发现, DataFrame 中会包含分去列 |
|---|
| 配置 | 默认值 | 含义 |
|---|---|---|
spark.sql.parquet.binaryAsString | false | 一些其他 Parquet 生产系统, 不区分字符串类型和二进制类型, 该配置告诉 SparkSQL 将二进制数据解释为字符串以提供与这些系统的兼容性 |
spark.sql.parquet.int96AsTimestamp | true | 一些其他 Parquet 生产系统, 将 Timestamp 存为 INT96, 该配置告诉 SparkSQL 将 INT96 解析为 Timestamp |
spark.sql.parquet.cacheMetadata | true | 打开 Parquet 元数据的缓存, 可以加快查询静态数据 |
spark.sql.parquet.compression.codec | snappy | 压缩方式, 可选 uncompressed, snappy, gzip, lzo |
spark.sql.parquet.mergeSchema | false | 当为 true 时, Parquet 数据源会合并从所有数据文件收集的 Schemas 和数据, 因为这个操作开销比较大, 所以默认关闭 |
spark.sql.optimizer.metadataOnly | true | 如果为 true, 会通过原信息来生成分区列, 如果为 false 则就是通过扫描整个数据集来确定 |
总结
Spark不指定format的时候默认就是按照Parquet的格式解析文件Spark在读取Parquet文件的时候会自动的发现Parquet的分区和分区字段Spark在写入Parquet文件的时候如果设置了分区字段, 会自动的按照分区存储
4. 读写 JSON 格式文件
目标
- 理解
JSON的使用场景 - 能够使用
Spark读取处理JSON格式文件
什么时候会用到 JSON ?
在 ETL 中, Spark 经常扮演 T 的职务, 也就是进行数据清洗和数据转换.
在业务系统中, JSON 是一个非常常见的数据格式, 在前后端交互的时候也往往会使用 JSON, 所以从业务系统获取的数据很大可能性是使用 JSON 格式, 所以就需要 Spark 能够支持 JSON 格式文件的读取
读写 JSON 文件
将要 Dataset 保存为 JSON 格式的文件比较简单, 是 DataFrameWriter 的一个常规使用
val spark: SparkSession = new sql.SparkSession.Builder()
.appName("hello")
.master("local[6]")
.getOrCreate()
val dfFromParquet = spark.read.load("dataset/beijing_pm")
// 将 DataFrame 保存为 JSON 格式的文件
dfFromParquet.repartition(1)
.write.format("json")
.save("dataset/beijing_pm_json")
如果不重新分区, 则会为 DataFrame 底层的 RDD 的每个分区生成一个文件, 为了保持只有一个输出文件, 所以重新分区 |
|---|
| | 保存为 JSON 格式的文件有一个细节需要注意, 这个 JSON 格式的文件中, 每一行是一个独立的 JSON, 但是整个文件并不只是一个 JSON 字符串, 所以这种文件格式很多时候被成为 JSON Line 文件, 有时候后缀名也会变为 jsonlbeijing_pm.jsonl```
{"day":"1","hour":"0","season":"1","year":2013,"month":3} {"day":"1","hour":"1","season":"1","year":2013,"month":3} {"day":"1","hour":"2","season":"1","year":2013,"month":3}
| - | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
也可以通过 `DataFrameReader` 读取一个 `JSON Line` 文件
val spark: SparkSession = ...
val dfFromJSON = spark.read.json("dataset/beijing_pm_json") dfFromJSON.show()
`JSON` 格式的文件是有结构信息的, 也就是 `JSON` 中的字段是有类型的, 例如 `"name": "zhangsan"` 这样由双引号包裹的 `Value`, 就是字符串类型, 而 `"age": 10` 这种没有双引号包裹的就是数字类型, 当然, 也可以是布尔型 `"has_wife": true`
`Spark` 读取 `JSON Line` 文件的时候, 会自动的推断类型信息
val spark: SparkSession = ...
val dfFromJSON = spark.read.json("dataset/beijing_pm_json")
dfFromJSON.printSchema()
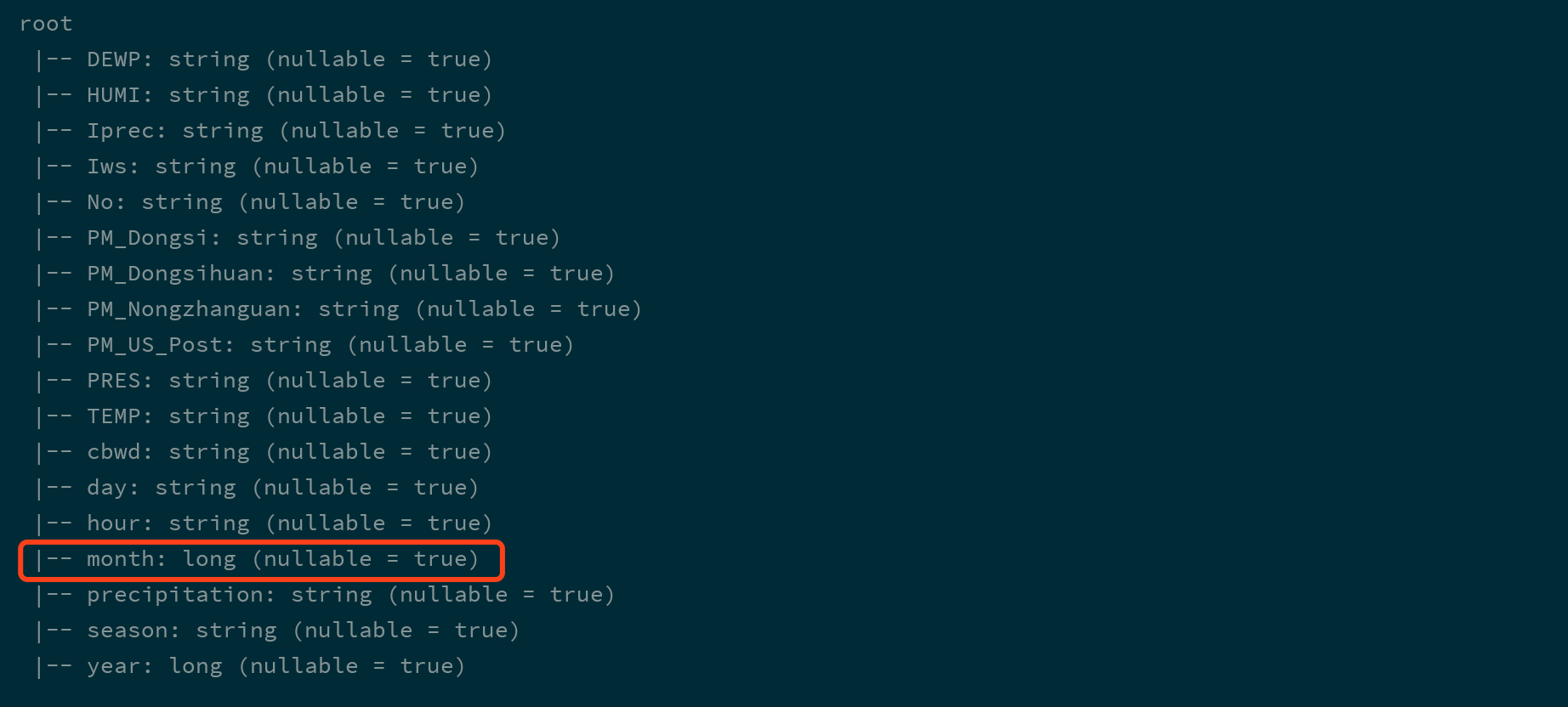
`Spark` 可以从一个保存了 `JSON` 格式字符串的 `Dataset[String]` 中读取 `JSON` 信息, 转为 `DataFrame`
这种情况其实还是比较常见的, 例如如下的流程

假设业务系统通过 `Kafka` 将数据流转进入大数据平台, 这个时候可能需要使用 `RDD` 或者 `Dataset` 来读取其中的内容, 这个时候一条数据就是一个 `JSON` 格式的字符串, 如何将其转为 `DataFrame` 或者 `Dataset[Object]` 这样具有 `Schema` 的数据集呢? 使用如下代码就可以
val spark: SparkSession = ...
import spark.implicits._ //注意这里导入的是上面sparkSession对象的名称。import spark1.implicits._
val peopleDataset = spark.createDataset( """{"name":"Yin","address":{"city":"Columbus","state":"Ohio"}}""" :: Nil)
spark.read.json(peopleDataset).show()
总结
1. `JSON` 通常用于系统间的交互, `Spark` 经常要读取 `JSON` 格式文件, 处理, 放在另外一处
2. 使用 `DataFrameReader` 和 `DataFrameWriter` 可以轻易的读取和写入 `JSON`, 并且会自动处理数据类型信息
