一起养成写作习惯!这是我参与「掘金日新计划 · 4 月更文挑战」的第11天,点击查看活动详情。
支持向量机
支持向量机(Support Vector Machine, SVM)是一种非常强大的监督学习算法 ,广泛应用于学术界和工业界,在学习复杂的非线性方程时提供了一种更为清晰的方法。
SVM 的优化目标
每个算法的关键都是优化目标——即代价函数的定义。
从逻辑回归引入 SVM
逻辑回归的激活函数
逻辑回归的激活函数如下(该激活函数同样也是逻辑回归的假设函数):
hθ(x)=1+e−θTx1=g(z)=1+e−z1
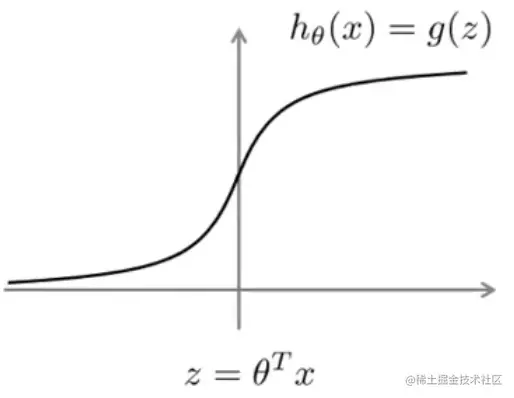
观察上面的函数,可以得出如下结论:
- 若y=1,要使hθ(x)≈1,则θTx≫0
- 若y=1,要使hθ(x)≈0,则θTx≪0
逻辑回归的代价函数:
逻辑回归的代价函数为:
J(θ)=minθm1[i=1∑my(i)(−log(hθx(i)))+(1−y(i))(−log(1−hθ(x(i))))]+2mλj=1∑nθj2
不考虑求和和正则化,只考虑单样本的情况下,逻辑回归的代价函数为:
J(θ)=−(ylog(hθ(x))+(1−y)log(1−hθ(x)))
- y=1(要使θTx≫0),则代价函数为:
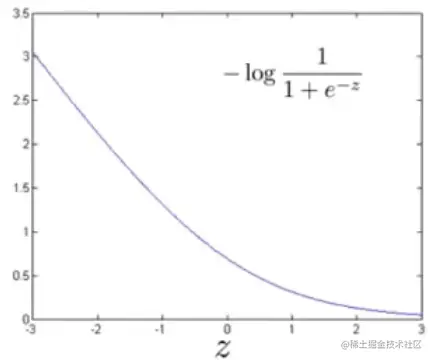
- 若y=0(要使θTx≪0),则代价函数为:
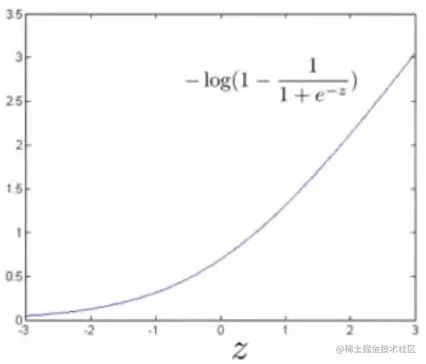
tips:牢记一点,我们优化的目的是使得代价函数最小,y=1/0时,θTx≪/≫0才能时代价函数最小
SVM 的代价函数
SVM 的代价函数为:
J(θ)=minθC[i=1∑my(i)cost1(θTx(i))+(1−y(i))(cost0(θTx(i)))]+21j=1∑nθj2
SVM 的代价函数,非常类似于上面逻辑回归的代价函数,做了如下改动:
- 将左边的−(ylog(hθ(x))替换为 cost1(θTx),将右边−(1−y)log(1−hθ(x))替换为cost0(θTx),这两个函数图像如图(粉红线):
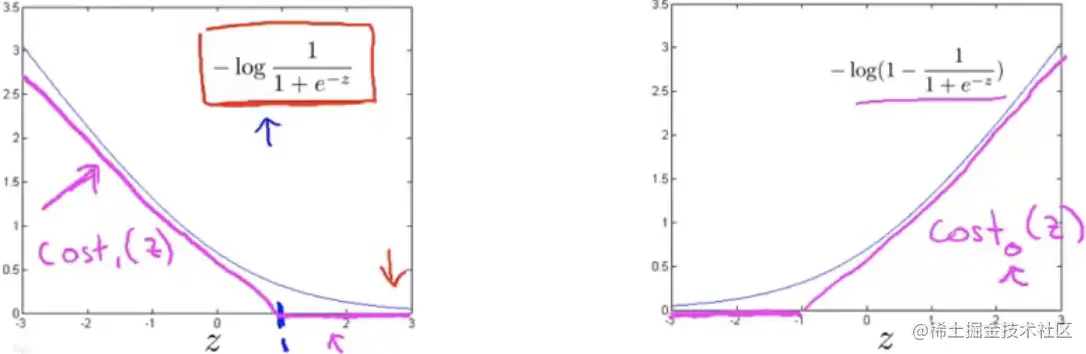
- 取消了求和的常数m,因为这并不影响代价函数求最小值
- 将右边的λ改为左边的常数C,这样设置参数更方便我们关注左边项的优化
tips:可以简单理解为移项,即C=λ1
SVM 的假设函数
SVM 的假设函数并不会输出概率,而是直观地预测y的值是等于 0 还是等于 1,如下:
hθ(x)={10θTx⩾0θTx<0
SVM 的决策边界
支持向量机又被看做是大间距分类器,也就是说 SVM 的决策边界是一种「大边界」,再看一下 SVM 代价函数的图像:
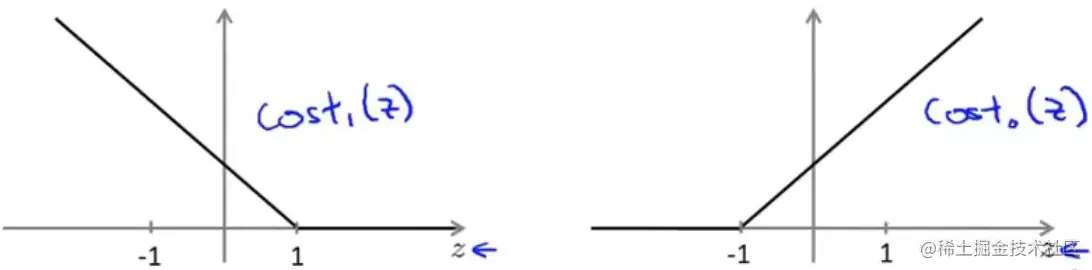
- 若y=1,要使θTx⩾1(不仅⩾0)
- 若y=0,要使θTx⩽−1(不仅<0)
可见,相比于逻辑回归分类中以 0 为界,SVM 对于分类有着更高的要求(以 1 / -1 为界),相当于在 SVM 中加入了一个安全的间距因子 。
举例大边界的含义
举一个例子来形象的理解一下这个「大边界」的含义,观察下面这样一个数据集:
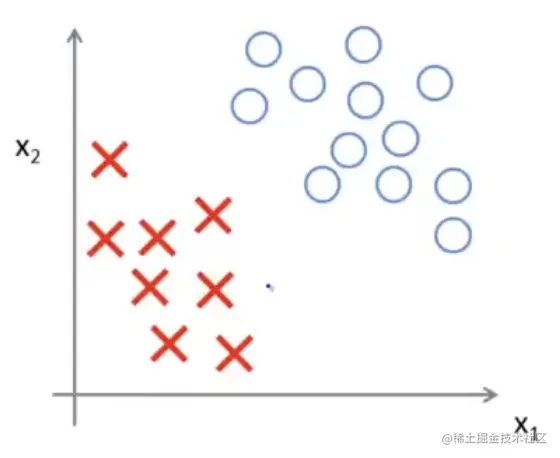
很显然存在很多条线可以将两种样本分割开来:
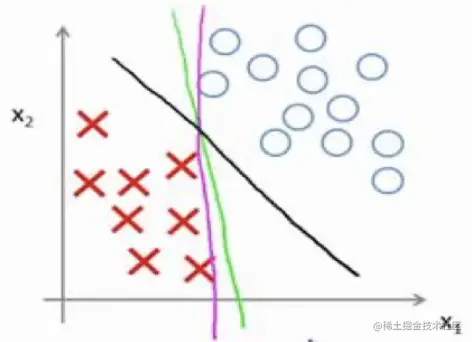
但我们往往认为中间那条黑线最为合适,为什么呢?因为黑线距离两侧的正负样本,有着更大的距离,这个距离称为支持向量机的间距(margin) ,这也就是大边距的含义。
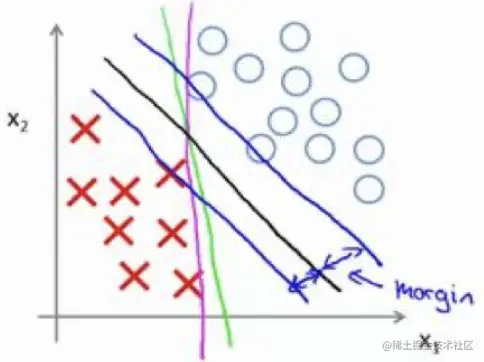
参数对 SVM 的影响
上面的例子中,为方便理解 SVM,实际上我们设置常数C非常大(C=λ1,可以理解为λ非常小),可以实现最大间距地分离正负样本。但这样做,如果遇到了一些异常点(outlier) 的话,为保持最大间距地分离,可能我们的决策边界会受到很大的影响(黑线变粉线)。
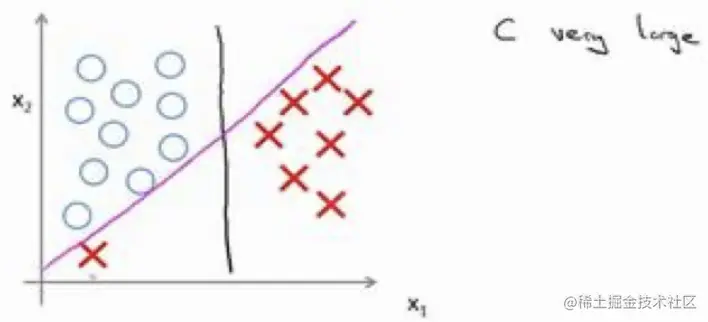
所以不要将C设置的太大,才能忽略掉一些异常点的影响,甚至当数据并不是线性可分的时候,也能得到更好的决策边界。
- C 较大时,相当于λ较小,可能会导致过拟合,高方差。
- C 较小时,相当于λ较大,可能会导致低拟合,高偏差
*大边界分类背后的数学原理
SVM 其实是一个很复杂的算法,理解 SVM 大分类背后的数学理解,才能更好的理解 SVM
内积概念的复习
数量积与向量积


我们通过向量内积的这些性质来尝试理解支持向量机中的优化目标函数
决策边界的数学原理
为方便理解,我们先假设数据集线性可分,即使得:
s.t{θTx⩾1θTx⩽−1y(i)=1y(i)=0
这样的话,代价函数左边的项就直接变为了 0,同时我们暂且不考虑θ0(假设为 0),这时的代价函数变为:
minθ21j=1∑nθj2
如果数据集是二维的,则有:
minθ21j=1∑nθj2=21(θ12+θ22)2=21∣∣θ∣∣2
tips:∣∣θ∣∣2是θ的 L2 范数
通过上面内积的知识,可知:
θTx(i)=θ1x1(i)+θ2x2(i)=p(i)∣∣θ∣∣
将其写入我们的优化目标函数:
s.t{p(i)∣∣θ∣∣⩽1p(i)∣∣θ∣∣⩽−1y(i)=1y(i)=0
大间距分类的原理
tips:SVM 决策边界超平面的公式为θTx=0,所以向量θ与超平面正交(垂直)。
- ⭕️ 和 ❌ 都看成是向量,实际上我们在找一个特殊的θ向量,使得所有 ⭕️ 向量点乘θ向量都<0;使得所有 ❌ 点乘θ向量都>0(假设函数)。
- 找到θ向量后,当一个向量点乘θ等于 0,也就是决策边界(实际上从数学角度来也必然是这样:ax+by=0与(a,b)垂直)。
- SVM 更希望θTx大于/小于某个常数(比如 1/-1 而不是 0 ),这样 ⭕️ 和 ❌ 在θ向量上的投影就会更大,离决策边界更远,从而实现大间距分类。
- 代价函数要求最小的θ的范数(即长度),只有在最佳分类的情况下才能使得θ的范数最小。
- θ0=0只不过决定了决策边界通过原点,即使θ0=0,以上结论依然可以推广。
tips:SVM 利用约束条件,1.θTx=0(前提条件) 2.minθ21∣∣θ∣∣2(决定因素) 3. p 与模长关系(控制参数),来保持边界与样本的距离使函数更加合理。
核函数
其他学习资源
blog.csdn.net/v_JULY_v/ar…


