决策树
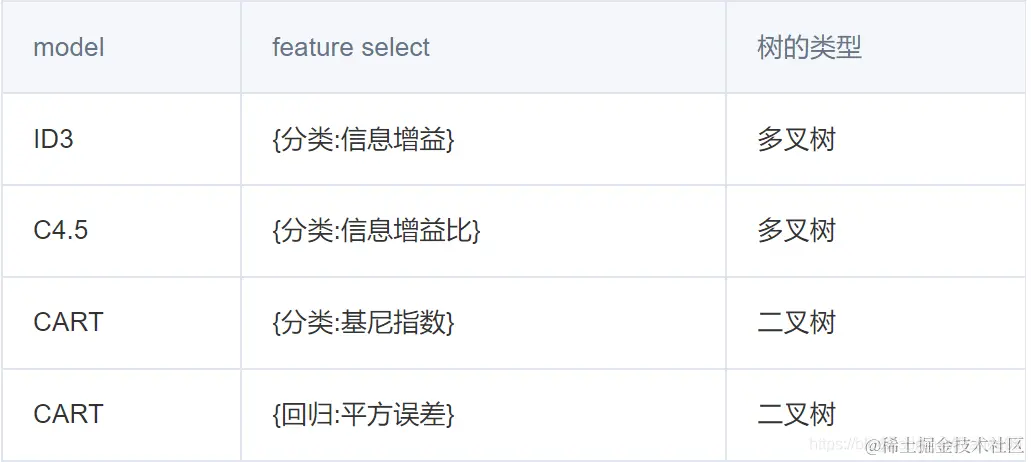
- ID3、C4.5 只处理离散特征。 (1次遍历:最优特征)
- cart 既能处理离散特征,也能处理连续特征。(2次遍历:最优特征,最优特征分割点)
- ID3、C4.5是多叉树。cart是二叉树。
- GBDT、Xgboost既可以处理回归问题做预测,也可以处理分类问题,也可以得到高阶特征交叉的特征。
- GBDT、Xgboost都是回归树。cart自己做分类时,才是分类树。
from math import sqrt
from math import log
import operator
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts:
labelCounts[currentLabel]=0
labelCounts[currentLabel]+=1
shannonEnt = 0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob*log(prob,2)
return shannonEnt
def createDataSet1():
dataSet = [['长','粗','男'],
['短','粗','男'],
['短','粗','男'],
['长','细','女'],
['短','细','女'],
['短','粗','女'],
['长','粗','女'],
['长','粗','女'],]
labels = ['头发','声音']
return dataSet,labels
def splitDataSet(dataSet,axis,value):
retDataSet = []
for featVec in dataSet:
if featVec[axis]==value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0])-1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet,i,value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob*calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
if infoGain>bestInfoGain:
bestInfoGain = infoGain
bestFeature = i
return bestFeature
def majorityCnt(classList):
classCount={}
for vote in classList:
if vote not in classCount.keys():
classCount[vote]=0
classCount[vote]+=1
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel: {}}
del (labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
return myTree
def predict(mytree, tips, list1):
res = []
for item in list1:
tmp_tree = mytree
iter = tmp_tree.__iter__()
while 1:
try:
key = iter.__next__()
if isinstance(key, str) and (key == "男" or key == "女"):
res.append(key)
break
v = tmp_tree[key]
index = tips[key]
item_res = item[index]
tmp_tree = v[item_res]
iter = tmp_tree.__iter__()
except StopIteration:
break
return res
if __name__ == '__main__':
dataSet, labels = createDataSet1()
mytree = createTree(dataSet, labels)
print(mytree)
tips = {"头发": 0, "声音": 1}
res = predict(mytree, tips, [['长', '粗'], ['短', '粗']])
print(res)


