


情感分析
情感分析是自然语言处理(NLP)的一种应用,用于寻找互联网上用户的评论、意见等的情感。如今,Facebook、Twitter等社交网站被广泛用于发布用户对不同事物的评论,如电影、新闻、食品、时尚、政治等。评论和意见在确定用户对某一特定实体的满意程度方面发挥着重要作用。然后,这些被用来寻找极性,即积极、消极和中立。在这个项目中,我们讨论了一种对电影评论进行情感分析的方法。
问题陈述
某公司ABC希望有一个高度可扩展的情感分析模型。因此,它决定超越他们的评论生态系统,让他们现有的模型在更多的数据上进行训练。训练样本是评论和推文的组合。
属性描述。
- ID - 唯一的标识符
- 作者--用户ID
- 评论 - 不同的类型
- class - 代表各种情绪**(0**: 负面**,1**: 中性2: 正面)
必要的安装
HuggingFace Transformer
!pip install transformers
导入所需的包
import
读取训练和测试数据样本
train = pd.read_csv("/content/disk/MyDrive/Machine_Hack/train.csv")
train.head()
test.head()
训练样本中的标签分布
提取特征和标签
train_texts = train['Review'].values.tolist()
将训练样本分成训练集和验证集
from
微调自定义模型的步骤
- 准备数据集
- 加载预训练的标记器,用数据集调用它
- 用编码建立Pytorch数据集
- 加载预训练的模型
- 加载训练器并训练它(或者)使用本地的Pytorch训练管道
注:这里我们使用的是训练器
导入所需的转化器库
import
设置模型名称
model_name = 'distilbert-base-uncased'
符号化
使用标记器对语料库进行编码。
tokenizer = DistilBertTokenizerFast.from_pretrained('distilbert-base-uncased',num_labels=3)
- 这里标签的数量=3
train_encodings = tokenizer(train_texts, truncation=
- 设置Truncation =True将在BERT的情况下消除超过max_length(512)的标记。
- 设置 padding =True 将用空符号(即0)来填充长度小于max_length的文档,确保我们所有的序列都被填充到相同的长度。
- 设置return_tensors = 'pt' 将以pytorch tensors的形式返回编码。
- 这将允许我们在同一时间将成批的序列送入模型。
将我们的标签和编码变成一个数据集对象
- 将标记化的数据打包成一个Torch数据集
- 在PyTorch中,这是通过子类化torch.utils.data.Dataset对象并实现len和getitem来完成的。
class
class
Genearte DataLoaders
- 将标记化的数据转换为Torch数据集
train_dataset = SentimentDataset(train_encodings, train_labels)
定义一个简单的度量函数
from
定义训练参数
training_args = TrainingArguments(
用训练器进行微调
model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased",num_labels=3)
基于验证数据集评估训练器
由于load_best_model_at_end被设置为True,作为训练的一部分,这将在训练完成后自动加载最佳模型。
trainer.evaluate()

对测试数据进行预测
test[‘Sentiment’] = 0 test_texts = test[‘Review’].values.tolist() test_labels = test[‘Sentiment’].values.tolist()
preds = trainer.predict(test_dataset=test_dataset)
检索预测概率
probs = torch.from_numpy(preds[0]).softmax(1)

将相关的预测概率转换为一个数据框架
newdf = pd.DataFrame(predictions,columns=['Negative_0','Neutral_1','Positive_2'])
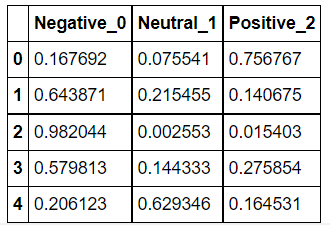
定义函数来格式化预测标签
def

预测的可视化
import
总结
- 在这里,我们使用huggingface变换器库在自定义数据集上训练了BERT模型。
- 同样,我们也可以使用其他转化器模型,如GPT-2与GPT2ForSequenceClassification,DistilBert与DistilForSequenceClassification等。
参考文献。
数据
使用Python中的变形器微调预训练的BERT进行情感分类》最初发表在《Nerd For Tech》杂志上,人们通过强调和回应这个故事继续对话。
