

Apache spark是广泛使用的数据处理分析引擎之一。Spark为执行分析和查询提供了广泛的API。连接是数据框架上最重要的操作之一,根据数据框架的性质或查询的基础,Spark选择不同类型的连接策略。
节点间的通信
Spark集群由驱动器和许多执行器节点组成,由于数据将被分割到不同的执行器上,因此有必要在不同的执行器之间共享数据,主要有两种类型的节点通信方法。
节点内通信。在这种方法中,数据将在不同的集群中被洗牌,洗牌可能成为Spark中最昂贵的操作之一。
广义转换中,数据的转换导致数据在不同的集群中被洗牌,这是节点内通信策略的一个例子。
广义和狭义转换
每个节点通信策略。在这种通信方式中,数据不是在不同的集群中洗牌,而是从一个节点广播给所有其他节点。
星火中的广播例子
广播式连接是spark中每个节点通信的例子,其中一个较小的数据帧将被广播给不同的执行器。
不同的连接策略
分类合并连接
这是一种重要的也是最常用的连接策略,主要用于大型数据帧,这些数据帧不能被广播到不同的节点(spark数据帧的广播限制是8GB)。分类合并连接分三个阶段进行。
- Phase1:Shuffle阶段--用于执行连接的两个表按照集群内的连接键被重新分区。
- 第二阶段:排序阶段--在每个分区内平行地对数据进行排序。
- 第三阶段:合并阶段--在这个阶段,每个数据集将被迭代,并加入具有相同连接键值的行。
分类合并连接的例子
分类合并连接的理想条件
- 确保分区已被放置在同一位置。这将导致更少的数据洗牌。
- 数据帧应该均匀地分布在各处。
- 更多的唯一键意味着有更好的并行性。
广播式连接
广播式连接是spark中有效的连接策略之一,因为在节点间的数据洗牌量最少。它只适用于大小小于8GB的小数据集。
val
val
ItemsDF
在上面的例子中,数据帧项目DF被广播给所有的执行者,从而产生了下面的DAG。

广播连接例子
散列哈希(Shuffledhash)连接
spark join的另一个最重要的策略是shuffled hash join,它基于map reduce的概念工作。
- **第1步:**使用连接ID作为键来映射数据帧
- **第二步:**执行洗牌操作,在不同的节点上传输数据
- 第三步: 基于键进行还原。
将preferSortmergejoin的值设置为false,并设置autobroadcastjoinThreshold限制,将阻止spark执行广播和sortmergejoin。
spark.conf.set("spark.sql.autoBroadcastJoinThreshold",
val
val
val
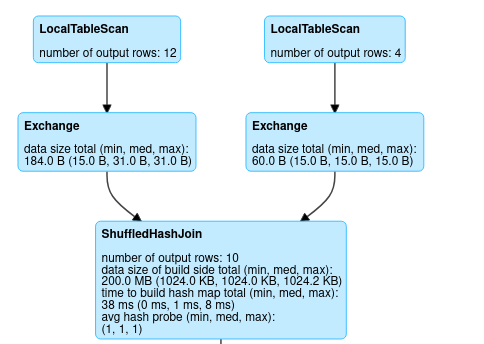
洗牌的哈希连接DAG例子
Apache Spark中的连接策略》最初发表在《Nerd For Tech》杂志上,人们通过强调和回应这个故事来继续对话。
