

在这篇文章中,我们想通过一些时间序列分析来解释预测性维护案例中的思考过程。
照片:Khamkéo VilaysingonUnsplash
内容列表
**先决条件
简介
数据
**
- 总体上看
- 目标数据(y)
**清洗数据
**- 去除NaN
进一步的选择
- 去除离群值
- 特征工程
- 特征选择
为
**LSTM准备数据
**- 创建时间序列
- 将数据分成训练验证测试集
- 规范化/标准化数据
- 重塑和单热编码
**使用一个简单的LSTM
**- 层和单元的问题
- 一个简单的模型
**结果
进一步选择
**
步骤
**
总结
**
前提条件
所有的代码都可以在这个Git-repo中找到
要重新创建这篇文章,你可以在这里找到数据集
。
我建议使用anaconda 创建一个Python 3.6环境并安装Python包。
Tensorflow (pip install TensorFlow)
Pandas (pip install pandas)
Numpy pip install NumPy)
Scikit-learn (pip install scikit-learn)
Matplotlib (pip install matplotlib)
绪论
在这篇文章中,我们正在研究泵的传感器数据的预测性维护。我们的方法对于时间序列分析来说是非常通用的,尽管在你自己的项目中,每个步骤可能看起来略有不同。我们的想法是让你了解一般的思考过程,以及你将如何处理这样一个问题。对于步骤的完整概述,请参见文章末尾的图(也许在阅读时可以同时打开)。它应该有助于按逻辑顺序组织所有的步骤。
如果你有一个类似的项目,并且只是在寻找一个演练,你可以直接在Github上查看代码并根据你的需要进行调整。
当然,为了限制文章的长度,很多观点只是被提及,并没有深入研究。不过,我们会指出相关文章的细节。我们希望这些信息能帮助你理解时间序列分析的一般方法。
数据
首先是总体情况
我们首先检查一下数据的总体情况。在我们面前的是什么?我们有多少数据?数据是如何组织的?每一部分的数据是什么类型的?
所以我们用pandas中的一行来读取数据,用简单的打印语句来获得一些概况。
从打印结果中我们可以得出以下信息。
CSV文件包含55个列,每个列都有超过200K的条目。
作者
数据分为52个_传感器_ 列,一个_机器状态_(目标/结果)列,一个_时间戳_ 列,以及一个_Unnamed_ 列,这只是原始索引列。
由作者
从时间戳中,我们可以看到,数据是以1分钟为单位记录的。快速浏览一下,我们就会发现,传感器的数据是浮动32的,振幅不一,时间戳是yyyy-MM-dd HH:mm:ss格式。
由作者
目标数据(y)
继第一眼之后,对我来说第二重要的事情是看一下目标数据(y数据/结果)。这将为解决方案的策略提供一些指示。
现在,在第一眼看到数据后,我们必须检查提供了哪些结果(称为目标),我们可以用它来确定/定义我们的预测性维护目标/路径。在输入代码提取目标数据时,我问自己的一些问题是
- 我们是否有目标信息,或者这将是一个无监督的任务?
- 目标数据是连续数据还是布尔运算?
- 目标的数据类型是什么?值,文本,...
- 目标是以什么间隔记录的?每个传感器条目都有一个条目,还是分组的?
- 每个传感器都有自己的目标(一台机器-一个传感器),还是所有传感器都有一个目标(一台机器-许多传感器)?
- 目标是描述性的,还是我们必须确定哪些算作故障,哪些算作正常?
- 目标信息是否完整和有用?
- …
为了得到一些答案,我们将得到独特的类,看看每个类有多少个值。发现标签是char格式的(文本),我们知道,我们必须在某个时候把它们转换成整数值,才能用于我们后面的Ml算法。为了把它们转换成相应的整数值,你可以使用scikit-learn的映射函数。如果你有了映射的目标,我们应该把它绘制出来,以了解什么时候会发生什么。
所以,我们看到,在数据集中有三个类。如前所述,它们是文本形式的,已经给了我们一个很好的指示,它是关于什么的。在其他情况下,你可能只收到一个状态[A、B、C]或类似的信息。
可用的类别[来自作者]
在统计了每个类别的值之后,我们看到我们有大多数的类别 "正常",这是可以预期的,因为机器在大多数时间内应该正常运行。而 "恢复中"和 "损坏"类则是少数类。我们可以直接看到,我们很可能无法使用 "破碎 "类,因为七个数值不足以学习任何模式。
每个类别的价值数量[由作者提供]
我们还看到,通过将这些数值算在一起,我们得到了与现有行相同的数量。这意味着目标数据中没有缺失值(NaN)(当然这也可以用_isna()_函数来检查)。
目标数据的图表显示,有问题的部分并没有集中在例如结尾处,而是分散在整个数据长度上。这对于以后的训练集和测试集的分割是很有意思的。我们还看到,恢复 类总是紧随_破碎_ 类。这意味着只有7个条目的_断裂_ 类是没有问题的,因为我们只需要预测恢复阶段,也可以得到_断裂_ 类。
目标数据[由作者提供]
为了回答之前的一些想法。我们有良好和完整的目标数据。我们每一行都有一个条目,从而形成了一个单机:多传感器的监督学习任务。
清洗数据
现在我们了解了数据,我们将不得不寻找传感器数据的质量,并且很可能对数据进行操作/修复/增强,以便对以后的训练有用。
删除NaNs
数据清理的第一步是检查NaN值。因此,发作时,一个传感器没有发送任何数据。不要与零值混淆,这实际上可能意味着该值为零(数据集中大量的零使得它成为一个稀疏的数据集)。这里的问题是
- 有多少数据是NaN的?
- 是只有少数的传感器,还是大部分的传感器都有NaN?
- 某些传感器的NaN比其他传感器多得多吗?
- NaNs是集中在一起还是分散的?
- 我们可以填补这些NaNs吗,还是必须要删除它们?
所以我们首先检查、打印和绘制NaNs的原貌。我们马上注意到,Sensor_15 是完全空的,所以我们把他删除,以便更好地扩展数据。

显示NaNs,并删除传感器_15 [作者]
我们现在可以简单地从数据中删除所有的NaN,然而,我们将失去大约77000个时间段,这将是大约35%。因此,我们试图逐个传感器去除尽可能多的NaNs。
如果我们看一下下一个最大的NaNs持有者,我们看到传感器50和51。我们可以看到几件事。首先,传感器50只是在某个时间点发出了声音。所以我们将删除传感器50。这里的另一个选择是删除从时间步长~140000开始的所有传感器的所有数据......所以不是一个真正的选择(在其他情况下,这可能实际上是唯一的选择)。
比较sensor_50和sensor_51 [作者]
第二,两个传感器的振幅和数值范围都非常相似。更重要的是,黄色标记的部分实际上非常相似。我们在其他传感器中看到(见下文),几乎所有的传感器都出现了140000标记处的下降。51号传感器似乎也在其数据间隙后就出现了这种下降。因此,我们决定用50的数据来修复51的数据。这不是最干净的方法,但在这里肯定是可行的。
在放弃了传感器_50之后,我们看到现在传感器_00和06-09之间的传感器显示了大部分的NaN。现在是检查方差的好时机,它显示了信号在多大程度上偏离了自身的平均值。意思是说,这个信号是否以任何方式移动?如果我们想检测一个趋势或类的变化,如果信号确实显示出方差,那就很好。
传感器和传感器数据的方差[由作者]。
正如我们在标记部分看到的,传感器00,06-09,并没有显示出高的方差。所以我们允许我们删除这些,因为我们认为它们不会增加足够有价值的信息与我们失去的整体信号量相比。
在下降之后,剩下的传感器确实显示了一些NaN。现在我们试图通过_fillna()_函数来填补它们,限制为30。意思是说,最多可以填充30个连续的NaN值。这导致了两个传感器留下了大约200个NaN。最后,我们只是删除这些,因为它只占0.09%。
附注。 这里有一个很好的Stackoverflow讨论 关于如何最有效地填补NaN的问题。
填补连续的NaN [作者]
进一步的选择
你总是可以在准备工作中做得更多。对于概念验证,我建议继续使用无NaN的数据,在你建立了一个基线模型的性能之后,再来进一步的数据预处理。
现在,被机器学习使用的第一步已经完成。最初,数据可以被读取并用于训练机器学习网络。然而,还有更多的选项需要优化,需要对数据进行分割,以及后来的扩展,以获得一个好的运行方案。
最常见的进一步优化的步骤是。
- 去除离群点/降低噪音
- 特征工程
- 特征选择
在对这个主题进行了短暂的深入研究后,我们还是要继续研究实际状态下的信号。第一个目标应该是得到一个运行的_概念证明_(POC)。之后应该进行优化,继续进行信号清理、特征创建等工作。
离群点清除/降噪
去除离群点是指识别和去除信号中无助于模式识别或甚至破坏算法的部分。这可以通过不同的已经建立的算法来完成。在下面的文章中可以找到一个很好的概述。
需要记住的一点是,剔除离群值以及降噪,信号的那些部分实际上可以是有价值的信息。因此,盲目地无视它们并自动去除离群点和噪声可能不会毁掉你的算法,但可能会降低其性能。这对降噪来说尤其如此。匆忙执行的降噪会威胁到你的分析。
增加信噪比的一般方法是移动平均数或卡尔曼滤波策略。
特征工程
在我们的案例中,我们可以直接使用信号传感器信号作为特征输入。但是,如果你的问题比较复杂,有不稳定的、有噪音的、高度不稳定的信号,你要把你对问题的认识带进去。这种知识,或者说一般来说好的工程特征,往往能带来更好的模型性能。以不同的方式表述,好的特征减少了对完美模型的需要。
这个话题充满了另一篇文章,因此我们不深入探讨,而是指给你看_Jason Brownlee_的一篇好文章_。_
特征选择
另外,这个话题本身就需要一篇文章,我们将简单解释一下关于我们的数据集的几个要点,并指出_Jason Brownlee_ 的更多文献供你深入研究。
要进行特征选择,因为冗余数据、坏数据或无信息的数据反而会阻碍而不是提升你的机器学习性能。我们总是认为,数据越多越好,但更准确地说,应该是:_好特征的数据越多越好。
_通过特征选择,我们帮助算法事先理清哪些特征会增加解决问题的难度。
一个经验法则是,越是简单的算法,如K-NN,越是受益于特征选择,因为否则它很难从多余的特征中分离出有意义的特征(淹没在特征中)。更复杂的算法,如随机森林和ANN,能够自己找到最佳特征。在这里,我们 "只是 "通过之前的特征选择来减少计算的工作量。
只是要提到的是,正则化在某些情况下可以取代特征选择。关于L1正则化和特征选择的有趣讨论可以在这里找到。一个很好的描述可以在这里阅读。
当查看我们所有的传感器时,我们可以看到有一些传感器组看起来非常相似(在下面的图片中按颜色分组)。这意味着通过相关方法或主成分分析(PCA)减少输入的传感器会很有效。
分组的传感器信号 [作者]
训练一个模型
由于数据已经有了基础准备,我们现在可以选择一种算法类型来解决预测问题。根据数据量、问题的复杂性、最终运行的硬件以及其他考虑,你可以选择不同的算法。
由于我们没有做特征选择,我们应该使用随机森林分类器/预测器或一种ANN,因为两者都可以作为综合特征选择器。
我们选择一个LSTM,以便以后测试它在嵌入式硬件上的支持。
为LSTM准备数据
在选择了一个预测方法后,数据必须再次被准备以适应特定的方法。经典的ML和ANN的数据准备基本上是相似的,但在小的细节上有所不同(例如,输入维度)。
创建时间序列
数据在其当前的形式下可以用来训练一个实际类别的分类器。然而,我们想根据实际值来预测未来的类别。因此,我们需要对目标数据进行转移,创造一个时间差。这里再次感谢_Jason Brownlee_ 关于这个话题的精彩文章。

移位x [作者]
下面的代码逐块说明。
- n_in。要预测多少个时间段。n_out。用n_in预测多少个目标。n_out>1意味着预测一系列的目标值。两者都可以用来预测未来。我们在这里只使用n_out=1。
- 第6-7行,根据n_in的数量生成一个移位的输入。因此,例如n_in=3,那么对于剩下的46个传感器中的每一个,都会在一个DataFrame中创建3个移位信号和相应的名称。
- 第10-15行,向前移动以创建一个目标序列。
- 第17-18行,在一个DataFrame中合并所有的信号。
- 第20-22行,删除移位后创建的Nans
这个函数返回一个带有原始值和移位值的DataFrame(如下图)。

带有x(t)和x(t-1)的DataFrame [作者]
我们现在必须删除我们不想要的值。在我们的例子中,就是
- x(t)处的传感器
- 在x(t-n)处的传感器,其中n是所有的,除了想要的移位值。
- 以及x(t-n # a3)处的传感器_44(目标)。
因此,我们将留下所需的移位数据和未移位的目标。我们现在必须删除我们不想要的值。
- 第**1行,**设置要看多少步的未来
- 第2行,首先调用_series_to_supervise()_来创建移位的数据。
- 第3行,获得所有未移位的名称
- 第4行,获得所有移位值的名称,除了我们要用于预测的时间步距_(未来_ 值)。这其实是没有必要的。留下所有移位的值可能会提高性能。在你自己的项目上测试其差异。
- 第6-8行,获取目标数据出来,并删除收集的名称。
现在我们有了移位的X数据和未移位的Y数据。
将数据分成训练验证测试集
下一步是将数据分成训练验证和测试集。通常情况下,这是用例如 sklearn.model_selection.train_test_split() orsklearn.model_selection.StratifiedKFold() Funktion。然而,在我们的概念验证中,我们用手来分割,以便有更多的控制。我们选择。
手动分离的数据[由作者]。
现在我们已经准备好了我们的数据集。同样,对于一个正确的k-fold分析,这不应该手动完成,而应该用sklearn.model_selection.KFold()或sklearn.model_selection.StratifiedKFold_()_函数(分层的意思是每个选择都有相同数量的所有类别)。
正常化/标准化
下一步是对数据进行归一化。如果不同的输入特征(这里是传感器)有不同的振幅范围,那么数据的归一化是必要的。否则,在使用机器学习方法时,数值会被错误地表达出来。机器学习方法主要使用函数内的乘法。大值的乘法会导致更大的值,这将被误解为 "重要性"。在[0,1]之间对所有的值进行缩放,是中性比较的基础。
重塑和一次热编码
在最后两步,我们必须重塑数据,因为LSTM(我们将选择它)期望输入的形式是[样本、时间段、特征]。
而且,由于我们正在寻找分类,我们必须在训练前对我们的目标进行一次性编码,以便softmax激活能够正确解释类,而不会将类的顺序(0,1,2)误解为排名或重要性。这可以通过sklearn.preprocessing.OneHotEncode()函数轻松实现。
两者结合在一个函数中。
现在我们实际上已经准备好在不同的类上训练一个算法了。我们将选择LSTM。
使用一个简单的LSTM
层和单元的问题
所以我们首先为自己建立一个简单的LSTM模型。对于深度神经网络,主要有两个问题。每层有多少隐藏单元(神经元、滤波器......),以及有多少层。关于一个模型应该有多深的问题,经验法则是。
如果你建立自己的模型(没有经过预训练),从一到两层开始,在比较性能的同时逐渐增加。
对于一般的LSTM,你可以质疑更多的层是否意味着更多的长期记忆。这里有一篇 Jason Brownlee关于这个话题的有趣文章。总结一下,似乎更多的LSTM层在时间上提供了不同的扩展,因此有更好的时间分辨率/更好的性能。这相当于在有更多层的CNN中提供更多的分辨率。注意:更多的层意味着更多的复杂性,往往会导致过度拟合。
另一方面,隐藏单元(神经元、过滤器......)的数量在CNN中是不同的。在CNN中,经验法则是增加每层的数量,因为要分析更详细的信息。在LSTM中,就分析时间序列而言,存储单元的数量不如层的数量重要。这里的经验法则是隐藏单元(存储单元)比输入特征少。从小的开始,例如2,然后慢慢增加。所以只要尝试不同的值,但不要太强调它们。这里我们选择42;-)。
一个简单的模型
我们为概念验证所尝试的模型看起来是这样的。

该模型[由作者]。
两个LSTM层,每层42个隐藏单元,两个输出层。你可以在这里使用一个有一个输出的简单顺序模型。我们有两个作为,我们想展示不同的用例。signal_out是一个有一个单元的Dense层,给我们一个预测的信号,而class_out是一个有3个单元的Dense层,用softmax激活给我们预测的类别_"正常"_、"恢复中"和 "破碎"。
signal_out在这里似乎没有太大意义,但我们想说明的是,你可以用这种方法来提高预测率(见结果),预测一个信号而不是一个类别。
现在我们来训练这个模型。
结果
训练指标看起来很有希望。验证(这里标注为_测试_)损失和准确率看起来不错。

准确率和损失[由作者]。
但是我们看到一件事。即使你在下面看到的预测信号并不完美,但验证准确率显示为99%。这是一个很好的例子,说明为什么不对不平衡的数据集使用准确性。仅仅通过把所有的东西都归为多数类,我们就已经达到了高准确率。因此,对于不平衡的数据集,最好采用Kappa统计学、ROC、F1、Anova等测量方法。而且,为了在科学上做到滴水不漏,要使用这些测量方法中的一个以上,并进行k-fold交叉验证。
现在运行推理。
最后,让我们把目标和预测的目标画在一起。

预测目标与原始目标的对比[由作者提供]
你可以看到,故障情节没有被直接分类(由于只有7个样本可供处理),然而,恢复阶段被检测得相当好,在这种情况下,提前了10分钟。作为一个工程问题,这已经足够了,因为我们可以肯定地检测到故障事件的开始和结束,并有时间做出反应(关闭、转移到另一个泵、降低速度,......)。如果你提前需要更多的时间,可以增加_series_to_supervised()函数中的_n_in 变量。然而,移位的DataFrame变得相当大,我的笔记本电脑已经无法处理它了。是时候转移到Azure了。
如果我们把预测类(模型的signal_out输出)绘制成一个连续的信号,而不是最大类,我们可以看到,如果我们为例如输出设置一个简单的阈值,或者我们对计算的方差设置阈值,这可能会导致一个更稳定的分类。

作为持续信号的预测目标与作为二进制的原始目标[作者]
一般来说,用这种输出方法,你可以预测一个信号。意思是,你可以用一些传感器的数据来预测另一个传感器即将到来的数据。对于这种方法,你唯一要改变的是将你要预测的信号作为目标,而不是类(例如,现在传感器_42的数据是目标)。
进一步的选择
如果在你的项目中结果不令人满意,可以有以下选择(可能我漏掉了很多)。
- 玩弄超参数
- 添加更多的层
- 使用上面提到的信号处理/清理步骤
- 使用轻量级的 "经典 "机器学习
- 使用新的转化器模型
- 用GAN、SMOTE、ADASYN等合成更多的少数民族状态。
- 加重少数人类别的惩罚
- …
步骤总结
这篇文章相当长,也许会让人困惑。因此,我们再次总结了我们对每一章的所有想法。这将使你能够很容易地重构思想脉络。
请重复使用这张图片,但别忘了引用它。
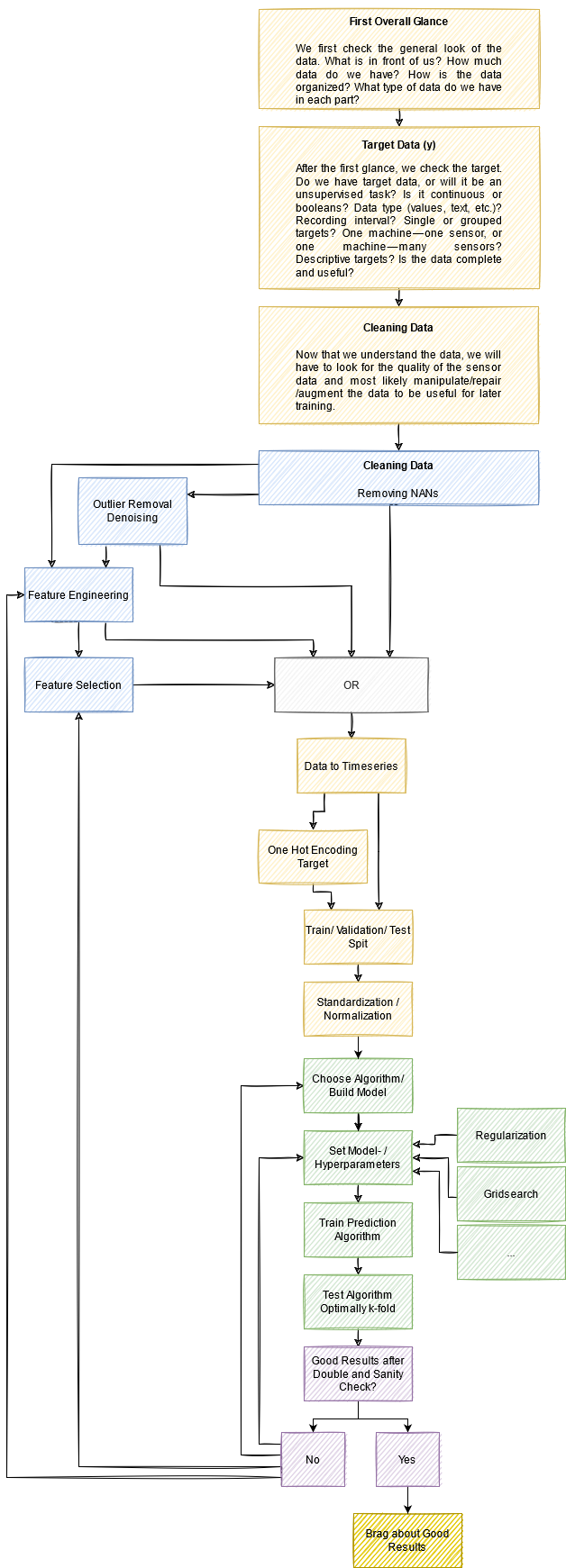
思想脉络[作者]
LSTM for Predictive Maintenance on Pump Sensor Data》最初发表在《Towards Data Science》上,人们在Medium上通过强调和回应这个故事继续对话。
