

从零到英雄:使用云功能的端到端自动化分析工作负载 - 数据融合 - BigQuery和数据工作室
摘要。
在这篇文章中,我们将演示如何使用谷歌云平台运行一个自动化的端到端数据加载、转换和可视化过程。在这个练习的最后,每当一个新的数据文件被上传到谷歌云存储桶时,一个云数据融合管道的执行将被自动触发,然后这个数据管道将对数据进行一些转换,并将结果加载到一个BigQuery表中,该表为一个带有在Data Studio中创建的几个可视化的报告提供信息。
介绍。
对于希望开始利用数据和分析工作负载来快速实现业务价值的企业来说,相当常见的用例是快速建立一个自动化的数据转换管道,并将其摄入数据分析仓库,从中生成一些新的简单而经济的报告和/或可视化。
本文提供了一个详细的解决方案,使用谷歌云平台的数据存储、处理和分析来实现这一目标。
该解决方案使用的GCP服务。
- 谷歌云存储。
- 谷歌云功能。
- 谷歌云数据融合。
- Google BigQuery。
- 谷歌数据工作室。
描述我们将在这个练习中实施的解决方案。
我们的想法是在Data Studio中创建一个非常简单的报告,从之前在BigQuery中创建和加载的表格中获取信息。源数据存在于一个累积的CSV文件中,在加载到BigQuery之前需要进行一定程度的转换,因此Data Fusion中的数据转换管道处理文件所需的转换,并将结果摄入BigQuery表中,首先截断该表(尽管通过改变Data Fusion管道中的一个标志,你可以修改它以在BigQuery表中追加数据,而不是每次运行都截断该表)。源文件是持续更新的,并且每天以按需方式多次上传到谷歌云存储,我们不知道新文件何时到达,但我们知道我们需要用任何新到达的数据来刷新报告,所以我们使用云函数在新的CSV文件被上传到云存储桶的情况下触发数据融合管道。这样一来,只需将一个新的数据文件上传到谷歌云存储桶,就可以触发数据摄取、转换、加载和可视化的整个过程。
主要步骤。
- 创建我们将使用的存储桶,并准备用于创建转换管道的源CSV文件。
- 在BigQuery中创建数据集和表,以存储来自CSV文件的数据。
- 创建数据融合实例,并为其使用的服务账户分配适当的角色。
- 在数据融合实例中,创建数据管道,该管道将处理新的CSV文件并将其纳入BigQuery表。
- 创建云功能,当一个新的文件被上传到定义的存储桶时,该功能将被触发,并将新添加的文件传递给数据融合管道,以便处理和摄取到BigQuery。
- 在Data Studio中创建一个简单的报告,对BigQuery中的数据进行一些可视化处理。
先决条件。
- 一个GCP项目,有一个相关的计费账户,并且至少有一个在该项目上具有项目编辑角色的用户。对于这个练习,我们创建了一个名为 "simplecsvbqload "的项目。
- 启用该项目所需的API。
- 云构建
- 云功能
- 云数据融合
步骤。
1.创建将用于数据处理的桶。
使用云外壳,在云存储中创建以下桶。你可以随心所欲地命名它们,它们只需要是唯一的,你将需要在以后的步骤中提供这些**(记得用你自己的桶名替换括号[]中的桶名)。**
gsutil mb gs://
上传到GCP的原始CSV源文件的桶(上传到这个桶的文件将触发数据转换和数据加载过程,这个桶将在编写云功能时作为该功能的触发事件使用)。
gsutil mb gs://
数据融合管道在将数据插入BigQuery时,将使用该桶作为临时存储。
gsutil mb gs://
桶,在云数据融合管道的数据处理过程中,将保存任何错误的输出。
最后,我们将上传一个带有数据子集的样本CSV文件,以便以后在用数据融合构建数据管道时,更容易使用Wrangler得出数据结构和模式。
gsutil cp SampleFile.csv gs://
从上面的数据预览中可以看出,将为该流程提供的源文件具有以下模式。
- id:长
- status_code:长
- 发票号码。长
- item_category:字符串
- channel:字符串
- order_date: 数据时间
- Delivery_date: 数据时间
- 数量。浮点
在将数据插入BigQuery之前,需要做一些改变,数据集中的日期列的格式是dd-MM-yyy H:mm,需要解析为yyyy-MM-dd hh:mm,以便BigQuery正确插入,另外,在浮动列中,小数点分隔符是逗号而不是点,我们也需要替换它,以便能够在BigQuery中将数字作为浮动数据类型插入。我们将在以后的数据融合管道中执行所有这些转换。
2.在BigQuery中创建数据集和表。
如上一节所述,我们将使用模式作为输入,在BigQuery中创建将容纳数据的表。
导航到BigQuery服务,在你的项目中,创建一个新的数据集,为了简单起见,我把它命名为dataset1。
然后,在新创建的数据集中,我只是创建了一个简单的空表,并命名为table1,其列名与源CSV文件相同,并容纳相应的数据类型。所以它看起来像这样。
3.创建数据融合实例。
如果你还没有启用云数据融合API,请启用。
一旦API被启用,在左边的菜单中导航到数据融合,点击创建实例。
用你喜欢的任何名字命名你的实例,我把它命名为cdf-test-instance。
Data Fusion利用Cloud Dataproc作为其底层大数据处理引擎,这意味着当数据管道被执行时,Data Fusion会产生一个短暂的Dataproc集群来为你执行数据处理,并将管道处理作为一个火花作业提交给Dataproc集群,一旦作业执行完毕,Data Fusion就会为你删除Dataproc集群。确保授予Data Fusion使用的服务账户适当的权限,以催生云Dataproc集群,它会提示你授权,当它这样做时,点击GRANT PERMISSION按钮**(还要记住部署Data Fusion实例的区域,需要与创建BigQuery数据集的区域相匹配)**。
点击CREATE按钮,实例创建将需要几分钟时间。
一旦数据融合实例被创建,复制数据融合正在使用的服务账户,并通过导航到IAM并点击+ADD按钮授予其**"云数据融合API服务代理 "**角色,在这个角色分配给数据融合服务账户后,数据融合可以从/到其他服务,如云存储、BigQuery和Dataproc访问数据。
现在,实例已经创建,并且我们确保数据融合使用的服务账户具有所需的权限,我们准备创建数据转换管道,它将接受CSV源文件,对其进行一些转换,并将数据加载到我们先前创建的BigQuery中的表。
4.在数据融合中创建数据管道
在数据融合部分,你会看到数据融合实例,点击查看实例链接以访问数据融合用户界面。
数据融合用户界面将在你的浏览器的另一个标签中打开。
如果你对数据融合不熟悉,你可以点击 "开始浏览 "按钮,看看并熟悉它。为了这个练习的目的,我们将暂时跳过它,点击No Thanks 按钮。
为了清楚起见,我们将从头开始设计管道,所以点击集成卡下的工作室链接。
你将被转到工作室页面,首先,在屏幕的顶部中央给管道一个有意义的名字**(你将需要在以后的云功能python脚本中引用管道的名字,当云功能引用它来开始执行)。**
接下来,我们将读取样本CSV文件,我们只是将整个文件传递到下一个阶段,并将在下一步解析CSV。
将鼠标悬停在绿色的GCS盒子上,这个盒子是你点击左边菜单上的GCS图标时添加到画布上的。会出现一个 "属性 "按钮,点击这个按钮。
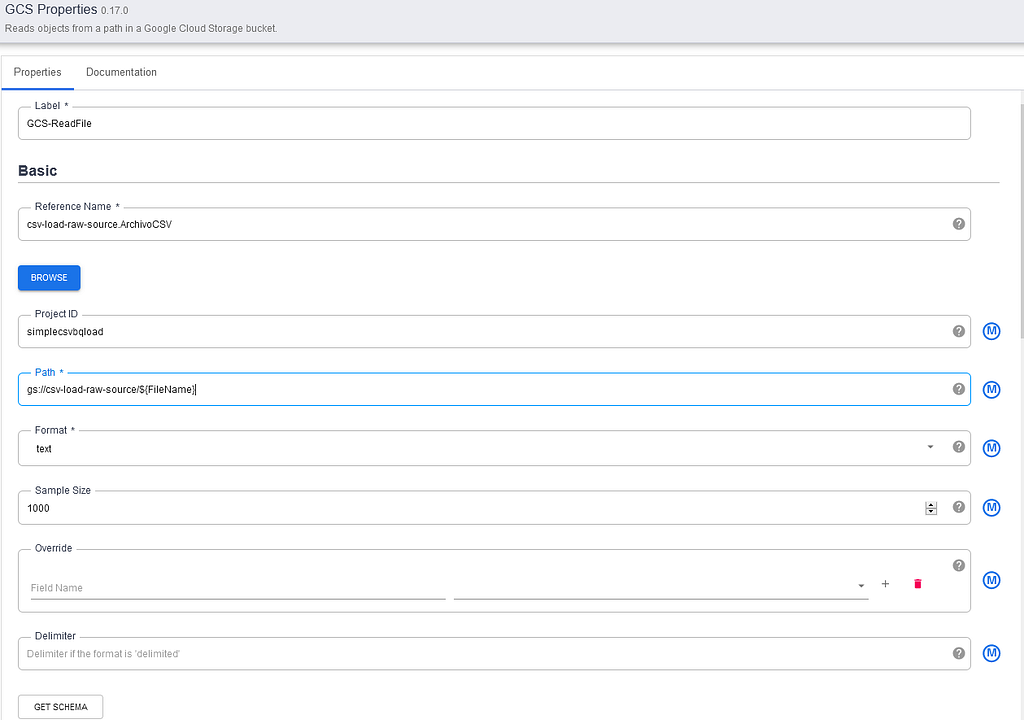
在GCS源组件的属性页面中,将 "路径 "属性设置为:gs://[YOUR_DATA_SOURCE_BUCKET]/${FileName}。
其中${FileName}作为运行时参数变量,将在执行时传递给管道(我们将在后面定义该变量作为管道元数据的一部分)。
在右边的输出模式部分,删除偏移量 字段,这样它就不会被传递到管道的下一步,只有文本的主体被传递到我们将在管道的下一步设置的数据rangler组件中。
接下来,我们将在画布上添加一个wrangler操作,我们将在其中执行步骤1中提到的转换和解析。要做到这一点,展开左边的转换菜单,并点击Wrangler工具。它将被添加到画布上,如下图中的蓝色方框所示。
现在,我们需要将读取的CSV文件的输出连接到Wrangler上,如下图所示。然后,悬停在rangler上,点击出现的属性按钮,访问rangler属性。
在这里,你可以给标签加上任何你喜欢的名字,现在,我们将保留所有的默认值,但我们将把错误处理行为从默认的 "跳过错误",改为 "发送到错误端口",这样我们就可以把管道执行期间的错误重定向到GCS的一个文件,以便以后进一步处理。我们可以使用JEXL语法(https://commons.apache.org/proper/commons-jexl/reference/syntax.html)直接用指令编写转换的配方,但为了简单起见,并利用数据融合用户界面的优势,我们将使用wrangler工具来做,无论我们在wrangler中做什么,以后都会被翻译成JEXL指令并显示在这里的配方下。点击指令部分下面的WRANGLE按钮。
现在是上传SampleFile.csv文件到步骤1中创建的源数据桶的时候了,在打开的GCS浏览器中,导航到[YOUR_DATA_SOURCE_BUCKET]并选择你在步骤1中上传的文件。通过向wrangler提供数据文件的样本,我们可以让wrangler推断出数据结构并直观地执行数据整理任务。
文件内容将显示在左边,而将走出wrangler的列则显示在右边的部分。就目前而言,wrangler将文件中的每一行作为一个名为 "body "的字段来读取,并按原样输出。我们现在开始进行转换。
从wrangler默认输出
首先,我们将让Wrangler把文件解析为一个以分号分隔的CSV文件。点击列名**(body)**左边向下的小箭头,并选择parse→CSV选项。
由于CSV文件中的列是用分号(;)分隔的,我们在弹出的窗口中选择自定义分界符,并在其中插入一个分号,我们还勾选了将第一行作为标题的标志,然后点击应用。
现在,Wrangler已经分离了文件中的所有输入字段,并为每个字段创建了一个列,这反映在右边的输出列列表中,它将正文输入作为一个单独的列,但我们不需要它,所以我们将像之前那样选择它并选择 "删除列 "选项来删除它。
现在我们可以开始进行解析和转换,将数据纳入BigQuery表。
默认情况下,由于这是一个CSV文件,Data Fusion将所有的输入都视为字符串,我们需要改变这一点以正确插入数据。我们将使用列上的箭头菜单中的改变数据类型选项,将数据类型设置为与我们在步骤2中定义的BigQuery表中的列相匹配。
首先,通过这个相同的程序,我们将改变字段id、status_code 和 invoice_number的数据类型为Long,所以它们可以插入BigQuery表中。
接下来,在将数据类型改为浮动之前,我们将把金额字段中的逗号替换为点,这样它就可以很容易地作为一个浮动值插入BigQuery中,这样逗号就不会被误解为千位数分隔符(这是由非英语国家使用点作为千位数分隔符而不是逗号以及逗号被用作小数分隔符造成的)。我们将使用查找和替换功能来处理这个问题,在旧值字段填写逗号,在新值字段填写点,然后点击全部替换按钮。
现在我们可以将该字段的数据类型改为浮动。
现在,我们将解析order_date字段,以便将其作为Datetime类型正确插入BigQuery中。
如前所述,我们必须使用自定义格式,因为输入日期的格式是dd-MM-yyy H:mm ,所以选择 "自定义格式 "选项,在文本字段中提供格式,然后点击应用。
接下来,我们将使用 "发送到错误 "功能来过滤掉金额为0的行,这些行将被发送到错误文件中,在那里可以进一步审查,并在以后需要时重新处理(因为我们之前将这个字段的数据类型改为浮动,Wrangler自动将输入值从0替换为0.0,所以我们需要相应地设置过滤器为0.0)。
选择金额 列中的发送错误转换,将条件设置为 "值是" ,值为0.0,然后点击应用。
源数据中的delivery_date字段有一些空值,我们也将把这些记录发送到错误端口,以便以后可以审查这些记录。
选择delivery_date 列中的Send to errorTransformation,将条件设置为 "值为空" ,然后点击Apply。
最后,我们将解析字段delivery_date,作为数据时间,其过程与我们对order_date字段的解析相同。
现在我们已经为所有的转换做了配方,在wrangler屏幕的右侧,我们可以看到转换步骤的摘要,如果你想删除步骤,也可以这样做。
最后,点击右上方的Apply按钮,你将回到wrangler属性页面,现在你将看到JEXL语法中的配方,你还将看到右边的输出字段,这些字段将从管道中的wrangler步骤中产生。
现在你可以点击Validate按钮来验证一切正常,然后在准备好之后,点击按钮旁边的X,回到管道设计画布。
现在我们将处理错误,在画布中,我们将展开左侧菜单中的 "错误处理程序和警报 "部分,并点击 "错误收集器"。
然后,我们将从Wrangler中的错误端口拖放一个箭头到错误收集器,以引导和收集来自Wrangler的输出错误,我们不会在错误收集器属性中执行任何进一步的配置。相反,我们将在左边的菜单中展开水槽部分,并点击 "GCS",在画布上添加一个GCS写入器,我们将把从ErrorCollector收集的错误输出写入其中。
从ErrorCollector拖动一个箭头到GCS Writer,然后将鼠标悬停在新添加的GCS Writer上,访问其属性。在这里,我们将设置标签 为 "GCS-WriteErrors",路径 字段为步骤1中创建的gs://[YOUR_CDAP_ERRORS_BUCKET],格式 为CSV,写头标志为True,最后我们将设置输出文件前缀为 "errors"。这将写一个CSV文件到你定义的路径上,并在管道执行过程中,按每一个从wrangler出来的错误添加一个新行。
现在我们已经正确处理了错误,我们将添加管道的最后一步,将wrangler的输出摄入BigQuery表。在左边菜单的同一水槽部分,点击BigQuery图标,并从wrangler的输出拖动一个箭头到这个新图标。
现在管道应该是这样的,将鼠标悬停在画布中的BigQuery图标上,并访问其属性以设置管道的最后部分。
在BigQuery水槽的属性中,我们将设置一些值。
我们将把数据 集和表 设置为我们在步骤2期间在BigQuery中创建的数据集和表。我们将设置临时桶名称为gs://[YOUR_CDAP_TEMP_BUCKET]。
我们还将启用Truncate Table标志,以便管道每次运行时都能截断该表。
现在管道已经完成,你可以通过点击画布顶部的预览按钮来尝试管道的模拟运行,并手动设置我们设置的文件名作为管道定义的运行时参数(在管道部署并从云功能执行后,该运行时参数将被填充为上传到gs的 实际文件名**。//[YOUR_DATA_SOURCE_BUCKET]** ,它将在运行时传递给管道),现在我们将提供我们在步骤1中上传到桶中的相同的文件名,以便于本次试运行,然后点击运行。
管道的预览将运行约一分钟,但不会进行实际执行,不会产生Dataproc集群,也不会有记录被写入BigQuery表。
一旦预览运行结束,你可以预览每一步有哪些数据到达输入端,以及每一步的处理后有哪些数据出来。你可以通过点击每个管道步骤的**"预览数据 "**链接来实现。
一旦你审查了预览,并对管道的行为方式感到满意,就可以部署它了。为此,回到画布,再次点击预览按钮,禁用预览模式,然后点击部署按钮。
几秒钟后,管道将被部署并准备执行。
5.创建云功能,在有新文件上传到数据源存储桶时触发管道的执行。
现在,转换数据并将其加载到BigQuery的数据融合管道已经部署并准备好执行,我们将设置云函数,当有新文件上传到数据源GCS桶时,该函数将被触发。这个函数的目的是将新上传的文件传递给数据融合管道并开始执行。
为此,我们将需要首先启用云构建API,如果你还没有这样做,请启用它。
然后,导航到云功能。
一旦你进入那里,点击CREATE FUNCTION。
设置基本的功能配置和触发行为。
给新的函数起一个有意义的名字,将触发器类型设置为云存储,事件类型为最终确定/创建,桶为**[YOUR_DATA_SOURCE_BUCKET] ,** 然后 点击SAVE按钮。
然后点击下面的NEXT按钮。
**注意:**如果你还没有启用Cloud Build API,你会被提示这样做(如下图中的红色横幅所示,迫使你启用它)。
红色横幅表明云构建API尚未启用。
在云功能向导的代码部分,在左边你会看到一个文件模板的列表,这些模板是自动为你创建的,根据你将使用的运行时间和语言来创建你的功能,这些模板是必须的。由于我们将使用Python 3.9运行时来创建函数,因此将创建2个文件:main.py和requirements.txt。
requirements.txt 文件包含了Python函数本身所引用的Python库及其版本的列表,因此是该函数运行所必需的。main.py 文件包含实际的 Python 代码,这些代码在函数被触发时被执行。
首先,我们将编辑requirements.txt文件,在那里我们将列出云函数所需的Python库,在这种情况下,唯一没有默认捆绑在Runtime中的库,我们将在main.py文件中使用的是requests库(我们将在脚本中使用它来向Data Fusion REST API发送HTTP POST请求,以启动我们之前用Data Fusion创建的数据管道,并从Metadata服务器检索访问令牌)。
在Runtime 下拉菜单中选择Python 3.9 ,然后点击下面的requirements.txt文件,在requirements.txt文件中添加以下一行。
requests>=2.25.1
所以它看起来像这样。
然后我们编辑main.py文件,写下python脚本,每当有新文件上传到我们之前指定的存储桶时,该脚本就会运行。
Python脚本。
记住把YOUR_CDAP_INSTANCE_ENDPOINT和YOUR_PIPELINE_NAME这两个常量的值替换成你的Data Fusion实例的端点。你可以通过在云端外壳中运行以下命令来了解你的实例的端点。
gcloud beta data-fusion instances describe \
例子。
你可以在GitHub的main.py文件中找到相关代码。
gcp-functions-bq/main.py at main - davavillerga/gcp-functions-bq
最后,点击DEPLOY,这个函数应该需要几分钟的时间来部署。当它完成后,你应该看到它作为一个正确部署的函数列在已部署的函数下,像这样。
为了测试到目前为止一切都在按预期进行,我们将简单地上传一个CSV文件到gs://[YOUR_DATA_SOURCE_BUCKET],你如何命名这个文件并不重要,只要数据和标题与我们一开始上传的样本文件保持一致。
你可以通过检查你函数中的函数日志来确认云函数的运行。
你也可以通过数据融合实例用户界面中的函数来确认数据融合管道已经启动。
状态将从部署,变为供应 ,然后变为运行。
在Dataproc集群页面,你会看到Data Fusion已经产生了一个短暂的集群,只要管道在运行,它就会保持活力,当它结束时,它会被销毁。
大约5到6分钟后,管道的执行将结束,状态将变为Succeeded,你将在Data Fusion中看到有多少记录从每一步传到下一步。通过点击顶部的Runtime Args,你还可以看到云功能作为FileName参数传递给管道的值。
最后,在BigQuery中,你可以检查记录被加载到BigQuery表中。
6.在Data Studio中创建一个简单的报告,对BigQuery中的数据进行一些可视化处理。
现在我们有一些BigQuery中的数据可供利用,我们将在Data Studio中快速创建一个简单的报告。在同一个BigQuery表浏览器中,用右边的导出菜单导出表,开始在Data Studio中探索数据。
Data Studio用户界面将在一个单独的标签中打开,并预先加载表的数据。
我们刚刚添加了3个非常简单的可视化数据,一个是列金额的总和,一个是按项目_类别划分的记录百分比分布的环形图,一个是按订单_日期划分的金额的时间序列图**,现在由于输入的数据在订单_日期**列中只有2天的数据,图表看起来很奇怪,我们将添加一个有更多记录的新文件来看看区别。
我们用保存按钮保存数据探索,并点击共享 下拉菜单,选择创建报告和共享来保存报告,从探索模式进入报告模式。
在弹出的对话框中确认提示,让DataStudio从BigQuery访问数据。现在,从这里开始,我们可以继续向报告添加页面、可视化和图表,对报告进行格式化并应用一些漂亮的样式,使其看起来漂亮整洁,并准备以许多不同的方式进行共享,甚至安排电子邮件来共享。
我们上传文件UpdateFile.csv(其中包含更多的数据)到数据源桶,并等待数据更新过程的完成,一旦完成,我们可以在Data Studio中轻松刷新报告,以发送另一个最新的报告。
数据被刷新,你可以发送另一份更新的报告。
就这样!"。现在你有了一个功能齐全的自动初始ETL+分析的工作负载。你现在要做的就是继续向GCS输入数据,无论何时你需要它,你都可以让Data Studio发送最新数据的计划报告。
享受吧!
从零到英雄:使用云功能的端到端自动化分析工作负载--数据融合--......最初发表于Google Cloud - Communityon Medium,在那里人们通过强调和回应这个故事继续对话。
