如何打造一个Markdown编辑器呢,而我为什么要做这个。起因呢其实是想去了解编译原理。然后对AST有个动手的认知
接下来呢秀下成果图

- 图片略显苍白无力,但是这不重要吧,我们要学习的是原理、原理、原理,我目前也花不上这么多时间去完善😄 。左边是编辑区,右边是显示区。
首先要前置补充的知识点:Markdown的规范。否则用户在你的编辑器上写出的内容,在别的编辑器无法显示。唉, 人嘛,总得在条条框框下活着。这边推荐一个markdown规范网站:www.markdownguide.org/getting-sta… 砍柴不误磨刀工(😄)。对markdown敢兴趣的朋友不妨花上几分钟去看看。
开始敲重点: 推荐另一网站 astexplorer.net/ 这是一个解析ast的网站。里面支持多种语言的ast解析结构。如果你正在学习webpack打包编译的原理。不妨也先看看这个网站对js生成ast结构的内容。这边先附上markdown的ast结构图
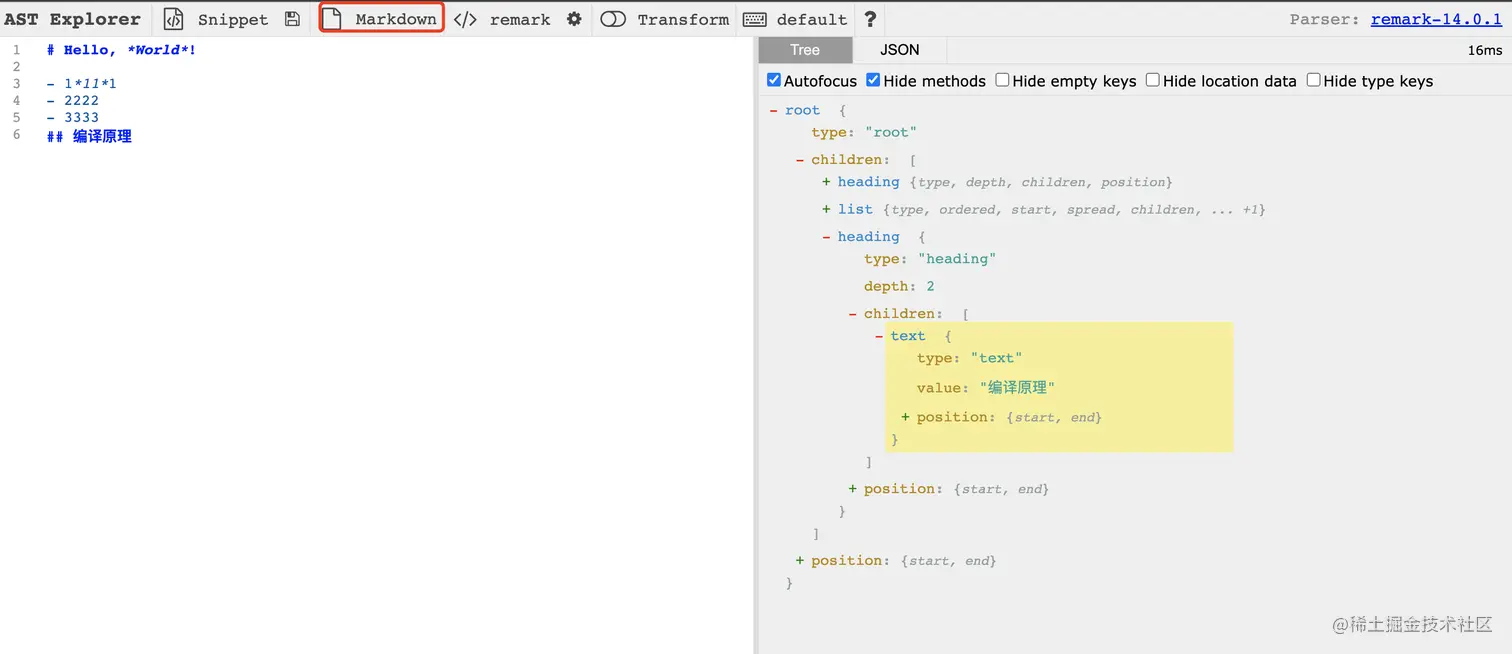
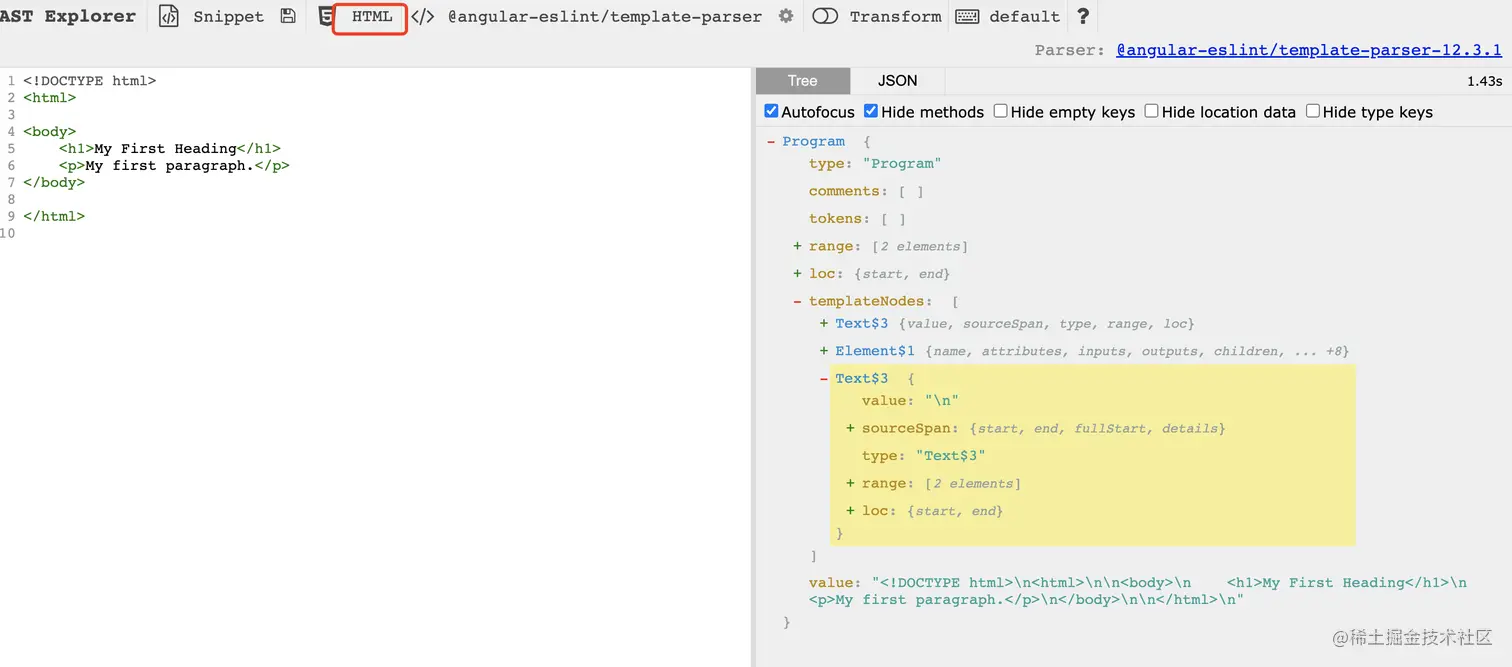
开始理一下开发思路
- 总体思维,我们需要将输入的内容=》转换为markdown AST结构数据 =》转换为Html AST结构 =》 目标代码
- 开发思维, 词法分析(token) => 语法分析(有特性标记的token) => 语义分析(语法规则、主谓宾…)
=> 源语言AST结构 = 》 目标语言AST =〉产生目标语言代码
因为其实开发的过程中逻辑还是比较好理解,所以我一次性贴出所有代码。感兴趣的朋友很容易跟上代码的步骤。如有疑问的可以评论,我加上注释
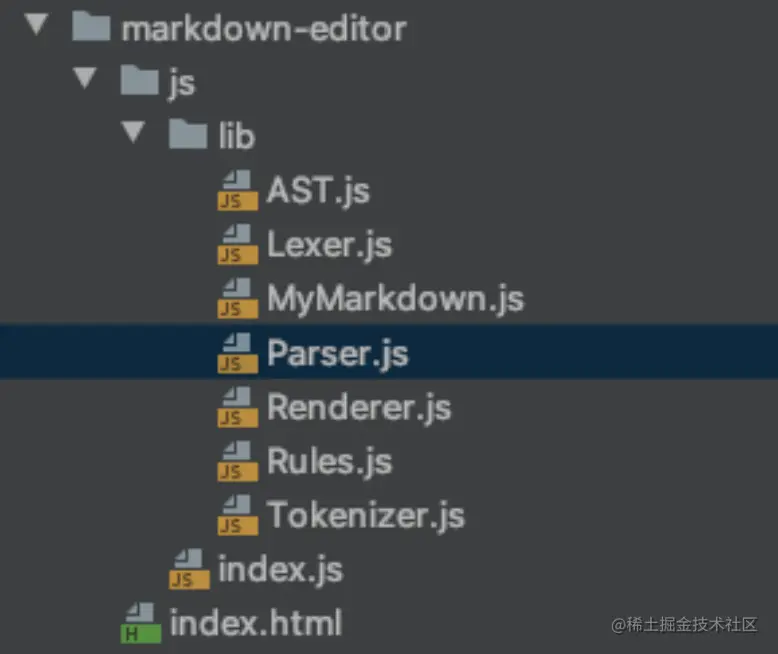
入口index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div style="display: flex">
<textarea style="flex: 1; padding: 10px; min-height: 500px; rows='20'" id="editor"></textarea>
<div style="flex: 1;border: 1px solid #000;padding: 10px;margin-left: 10px" id="viewer"></div>
</div>
<script src="js/index.js" type="module"></script>
</body>
</html>
入口index.js
import MyMarkdown from "./lib/MyMarkdown.js"
let input1 = `
# Hello, *World*!
- 1*11*1
- 2222
- 3333
## 编译原理
`;
let myMarkdown = new MyMarkdown();
const editor = document.getElementById("editor");
const viewer = document.getElementById("viewer");
editor.value = input1;
editor.oninput = parseAndRender;
parseAndRender();
function parseAndRender () {
viewer.innerHTML = "";
const ast = myMarkdown.parse(editor.value);
console.log("astast", ast)
const markdownElement = myMarkdown.render(ast);
console.log(markdownElement);
viewer.appendChild(markdownElement);
}
MyMarkdown.js
import Parser from "./Parser.js"
import Renderer from "./Renderer.js";
class MyMarkdown {
constructor () {
this.parser = new Parser();
this.renderer = new Renderer();
}
parse (src) {
const ast = this.parser.parse(src);
return ast;
}
render (ast) {
return this.renderer.render(ast);
}
}
export default MyMarkdown;
Parse.js
import Lexer from "./lexer.js"
import AST from "./AST.js"
class Parser {
constructor () {
this.lexer = new Lexer();
}
parse (src) {
const tokens = this.lexer.lex(src);
console.log("parse->tokens", tokens);
const ast = (new AST(tokens)).ast;
console.log("ast", ast);
return ast;
}
}
export default Parser;
Lexer.js
import Tokenizer from "./Tokenizer.js";
class Lexer {
constructor () {
this.tokens = [];
this.tokenizer = new Tokenizer();
}
lex (src) {
src = this.preprocess(src);
console.log("进入分词", src);
this.tokens = [];
this.parseBLock(src, this.tokens);
console.log(this.tokens)
return this.tokens;
}
preprocess(src) {
return src.replace(/\r\n?|\n/g, "\n").replace(/\t/g, " ");
}
parseBLock (src, tokens = []) {
let token;
while (src) {
if ((token = this.tokenizer.newline(src))) {
src = src.substring(token.raw.length);
this.tokens.push(token);
continue;
}
if ((token = this.tokenizer.heading(src))) {
this.inlineToken(token.text, token.children);
src = src.substring(token.raw.length);
this.tokens.push(token);
continue;
}
if ((token = this.tokenizer.list(src))) {
this.inlineToken(token.text, token.children);
src = src.substring(token.raw.length);
this.tokens.push(token);
continue;
}
if (src) {
src = ""
}
}
}
inlineToken (src, tokens = []) {
let token;
while (src) {
if ((token = this.tokenizer.em(src))) {
src = src.substring(token.raw.length);
tokens.push(token);
continue;
}
if ((token = this.tokenizer.inlineText(src))) {
src = src.substring(token.raw.length);
tokens.push(token);
continue;
}
if (src) {
src = ""
}
}
}
}
export default Lexer;
Tokeninzer.js
import Rules from "./Rules.js";
class Tokenizer {
constructor () {
}
newline (src) {
const res = Rules.block.newline.exec(src);
console.log("exec", res);
if (res) {
return {
type: "newline",
raw: res[0]
}
}
}
heading (src) {
const res = Rules.block.heading.exec(src);
console.log("heading", res);
if (res) {
let text = res[2].trim();
return {
type: "heading",
raw: res[0],
depth: res[1].length,
text: text,
children: []
}
}
}
list (src) {
const res = Rules.block.list.exec(src);
if (res) {
return {
type: "list",
raw: res[0],
text: res[2] && res[2].trim(),
children: []
}
}
}
em (src) {
const res = Rules.inline.em.exec(src);
if (res) {
return {
type: "em",
raw: res[0],
text: res[1]
}
}
}
inlineText (src) {
const res = Rules.inline.text.exec(src);
if (res) {
return {
type: "text",
raw: res[0],
text: res[0]
}
}
}
}
export default Tokenizer;
Rule.js
export default {
block: {
newline: /^(?: *(?:\n|$))+/,
heading: /^ {0,3}(#{1,6})(?=\s|$)(.*)(?:\n+|$)/,
list: /^( {0,3}(?:[*+-]|\d{1,9}[.)]))( [^\n]+?)?(?:\n|$)/
},
inline: {
text: /^(`+|[^`])(?:(?= {2,}\n)|[\s\S]*?(?:(?=[\<![`*_]|\b_|$)|[^ ](?= {2, }\n)))/,
em: /^*([^*]+)*/
}
}
AST.js
class AST {
constructor (tokens) {
this.ast = {
type: "root",
children: []
};
this.createChildren(tokens, this.ast)
}
createChildren (tokens, parent) {
let listContainer;
const _parent = parent;
tokens.forEach((token) => {
switch (token.type) {
case "list" :
if (!listContainer) {
listContainer = {
type: "listContainer",
children: []
};
_parent.children.push(listContainer)
}
parent = listContainer;
break;
default:
listContainer = null;
parent = _parent;
break;
}
this.createNode(token,parent)
});
}
createNode (token,parent) {
parent.children.push({...token})
}
}
export default AST;
Renderer.js
class Renderer {
constructor () {
}
render (ast) {
let rootElement = document.createElement("div");
this.renderNodes(ast.children, rootElement);
return rootElement;
}
renderNodes (children, parent) {
if (Array.isArray(children)) {
children.forEach((n) => {
let el;
switch (n.type) {
case "heading":
el = document.createElement(`h${n.depth}`);
parent.appendChild(el);
this.renderNodes(n.children, el);
break;
case "text":
el = document.createElement('span');
el.innerText = n.text;
parent.appendChild(el);
this.renderNodes(n.children, el);
break;
case "em":
el = document.createElement('em');
el.innerText = n.text;
parent.appendChild(el);
this.renderNodes(n.children, el);
break;
case "listContainer":
el = document.createElement('ul');
parent.appendChild(el);
this.renderNodes(n.children, el);
break;
case "list":
el = document.createElement('li');
parent.appendChild(el);
this.renderNodes(n.children, el);
break;
}
})
}
}
}
export default Renderer;
代码就先这么多。


