

如何解决git的大文件存储
在日常的开发中,经常会有大文件,如zip安装包等存储方面的需要。而每次对这些大文件的下载和上传都比较耗时。 因此,基于git的版本控制工具的基础上,Github 开发的一个 Git 的扩展,用于实现 Git 对大文件的支持,工具自身是基于Golang进行实现,并在Github上开源。
Git LFS的设计目的是什么
- 更大:支持GB级别的大文件版本控制
- 更小:让Git仓库占用更小
- 更快:仓库的克隆和拉取更快
- 透明:Git使用上完全透明,上手快
- 兼容:权限控制上完全兼容
如何使用git的LFS
下载安装
- Mac:
# 安装HomeBrew
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
# 安装 git - lfs 到本机
brew install git-lfs
-
Winodws
目前lfs已经集成在了Git for Windows中,直接下载和使用最新版本的Windows Git即可。
项目启用
先cd到要启用的项目中,然后运行下列命令即启用lfs
git lfs install
跟踪文件类型
根据项目情况,以png为例,配置追踪svg类型的文件给lfs管理
git lfs track "*.png"
如图表示配置成功:
然后会在本地目录中,新增一个.gitattributes,用来管理文件类型的跟踪列表。
tips: .gitattributes 需要提交到版本仓库中,否则其他人克隆仓库无法使用lfs
提交和修改文件
由于lfs的操作是透明的,因此正常的git文件的提交和修改流程和基于lfs是一致的 如下:
# 其中 xxx 代表文件路径
$ git add xxx
$ git commit -m '提交 xxx 文件'
$ git push origin master
本地的Git LFS文件是如何存储
要了解如何存储,就需要查看lfs文件的内容。以我之前上传到github的文件为例
version https://git-lfs.github.com/spec/v1
oid sha256:949653dd1a1bdf6c920b4b1959909d43af4a0bb95b093ad856d4ce4c88bda4ac
size 12505
- version 表示git-lfs协议的版本
- oid是指该文件的object id,后面的sha256是摘要算法,64位16进制,其代表真实文件的名称,名称通过sha256生成,唯一值
- size 表示文件实际大小,单位为字节
从上面的信息中,可以推断实际上git存储的是指针文件,而实际上的文件是存储在lfs服务器上的,而如果是拉取了lfs的文件,则可以在.git/lfs文件夹看到此文件,如下图
Git LFS 有什么限制
- 不同的服务商对于LFS上传的大小有限制,像Github最多上传单个文件,如下
Git LFS的工作原理是什么
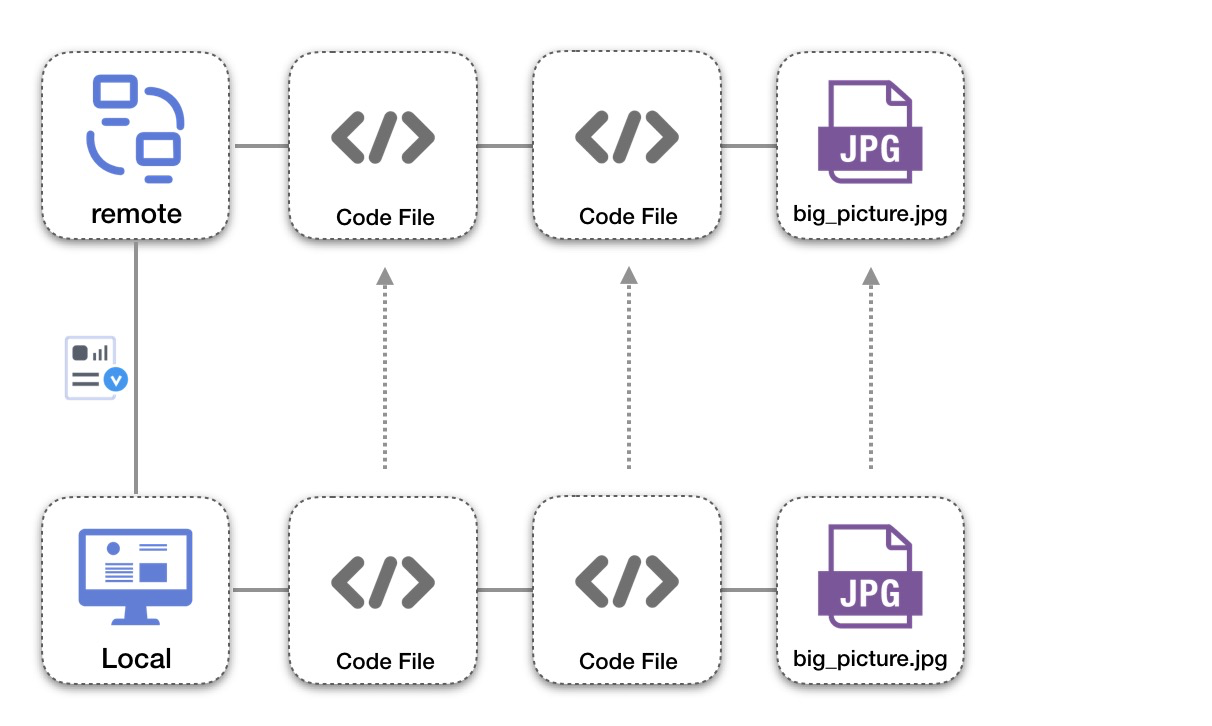
在没有使用lfs之前,普通场景不论是针对小型的代码文本文件、还是比较大型的图片文件,在相关变更从本地提交到远端仓库时,所有的相关文件资源都会完整的存储在git server上。随着时间推移,项目越来越庞大,则会导致体积越来越臃肿,如下图:
而在使用了lfs之后,就可以对一些大文件或者特定的文件类型来使用git lfs的存储能力,减少仓库的大小,同时将大文件的对应指针文件推送到仓库中,如下图:
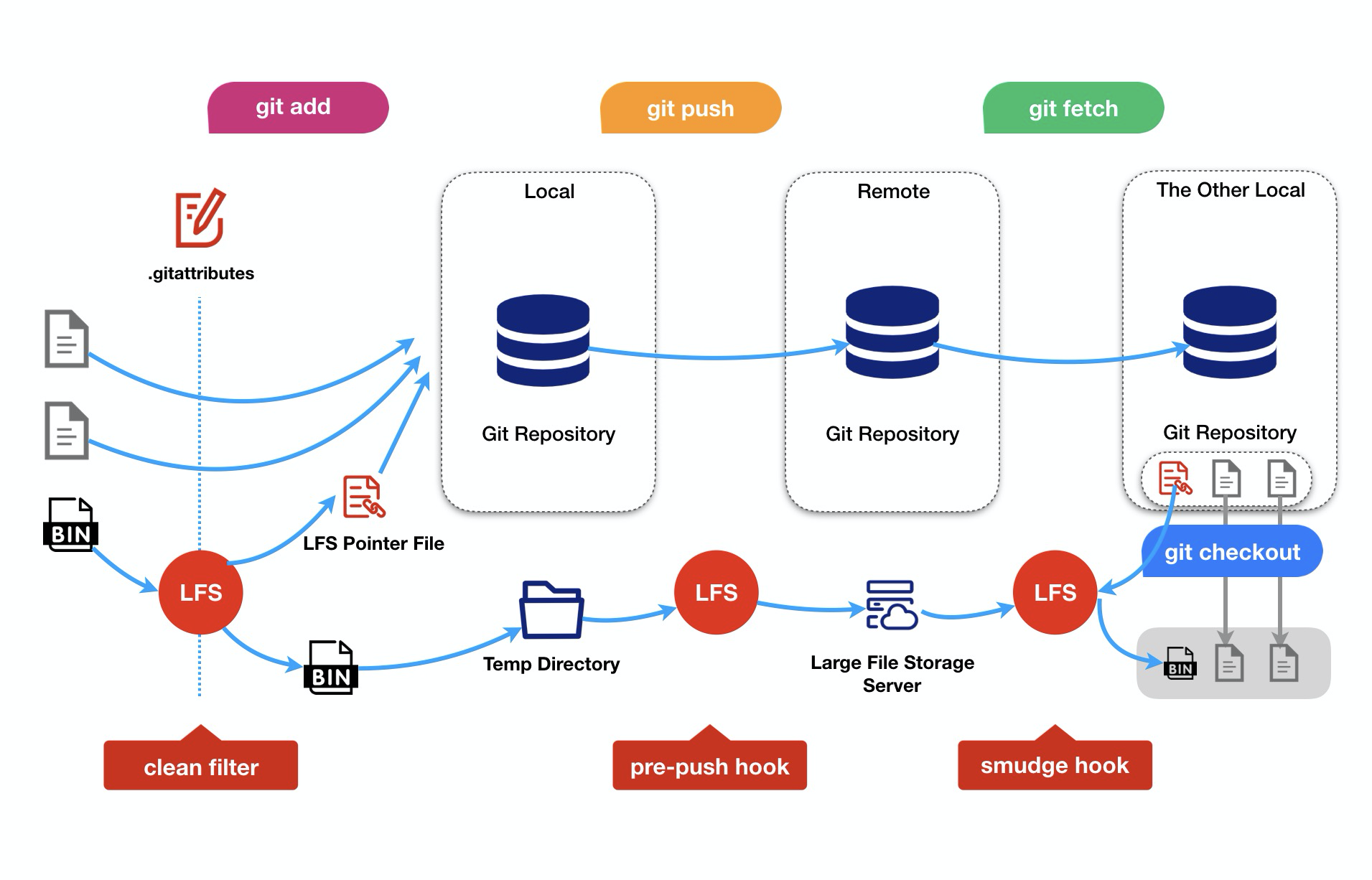
- 通过使用hook技术,在不同的操作如git add,git push等,进行拦截,生成指针文件和推送文件到lfs远程存储server中
- 当数据通过git add添加到仓库时,会触发clean filter,然后根据配置的属性文件,如果匹配到了则将此文件写入到.git/lfs/objects/对应的目录上面,然后再进行git push的时候,会将此文件上传到lfs服务器中。
- 当进行仓库的checkout时,则会触发smudge filter,此filter会读取git服务器下发的前一百个字节的数据,查看是否属于lfs的指针文件,如果是的话则下载到本地的.git/lfs/objects/对应的目录上面。
对于大仓库的克隆,除了使用LFS,有其他方案吗
对于大仓库的克隆,git提供了一种部分克隆(Partial clone)的技术,部分克隆允许您在克隆您的代码仓库时,通过添加--filter选项来配置需要过滤的对象,从而达到按需下载的目的,这种按需下载大大减少了传输的数据量和过程的耗时,同时还可以降低本地磁盘空间的占用。在后续工作中需要用到这些缺失文件的时候,Git会自动的按需下载这些文件,在不必进行任何额外的配置的情况下,用户仍然可以正常的开展工作。
部分克隆可以利用文件大小筛选器来排除麻烦的大文件,从而解决这一问题。当需要时,Git 会自行下载缺失的文件。克隆仓库时,请使用 --filter=blob:limit= 参数。例如要克隆存储库(不包括大于 1 MB的文件)。如下
git clone --filter=blob:limit=1m git@gitlab.com:gitlab-com/www-gitlab-com.git
同时现在很多项目使用了monorepo来管理项目,可以首先启用部分克隆,并指定--no-checkout选项来指定克隆完成后不执行自动检出,避免检出时自动下载当前分支下的所有文件。之后,再通过稀疏检出功能,只按需下载并检出指定目录下的文件来达到性能的提升。
部分克隆功能更适用于一些具有较长历史的仓库,或者只需要代码的最新版本等场景。而lfs更适合处理体积较大的二进制文件,两者可以相互配合。
参考资料
Managing huge files on the right storage with Git LFS-youtube
