2. AlexNet
1. 基本结构
1. 基本网络结构
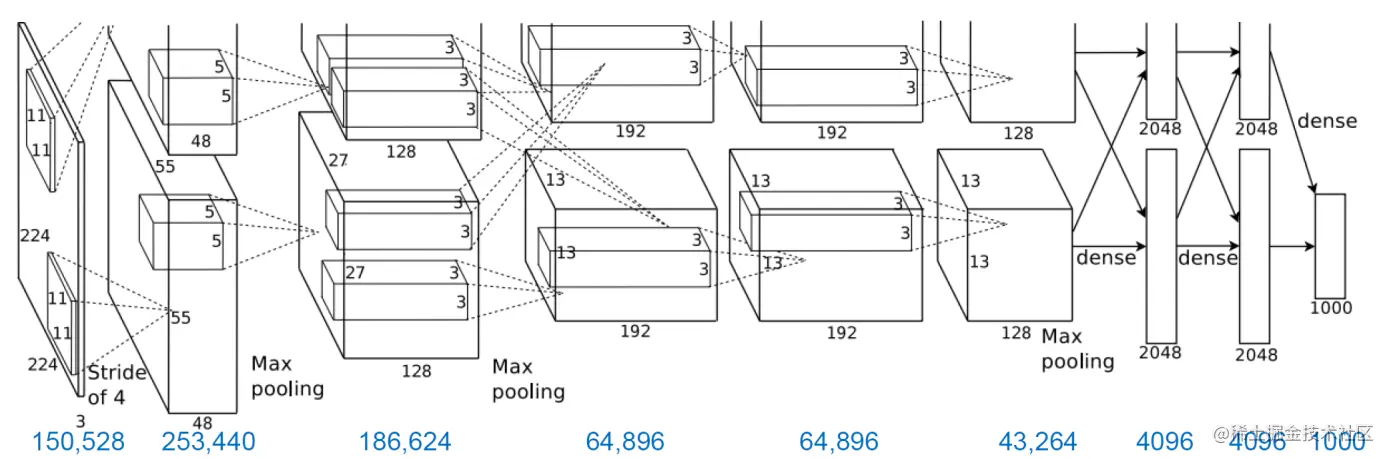
2. 细化的网络结构
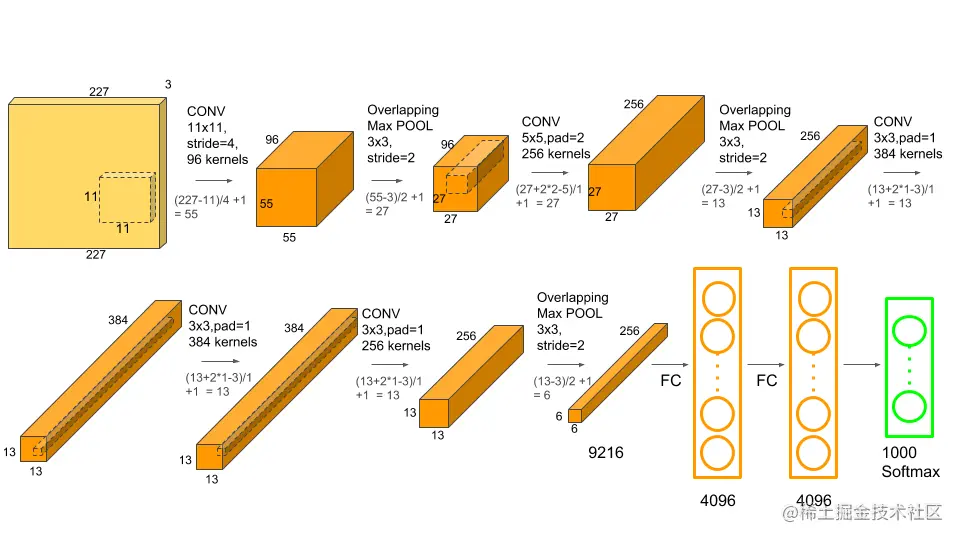
2. AlexNet基本技术
1. ReLu函数作为激活函数
2. 局部响应归一化(Local Response Normalization)
1. 基本作用
ReLu函数不像sigmod核tanh是有限区间函数,因此使用ReLu作为激活函数后需要进行归一化处理
2. LRN的基本公式
3.重叠池化
重叠池化:池化移动步长小于池化核的大小,相邻的感受野存在重叠部分,使用重叠池化的好处有:
- 减缓过拟合:重叠池化也是池化的一种方式,因此具有一般池化的降维,实现减少过拟合
- 提高精度:重叠池化的特征提取精度较高
3. 层次结构分析
AlexNet有 8个带权层,前5个为卷积层,后三个为全连接层,将同一层分为两块,分别在两个GPU上运行
1. Input(224×224×3)
输入层是彩色图,分为RGB共3个通道,每个通道为224×224大小的输入图
2.C1(2×48×11×11×3)
使用大小为11×11×3,步长为4像素的大卷积核,C1层一共是分为2×48个卷积核,对RGB三个通道进行卷积,平均每个通道使用32个卷积核进行卷积,每48个通道放在一块GPU上运算,实现并行计算,其相关的参数计算为
∵padding=2sieze_filter−1带入带入sizefilter=11得:∴padding=5
-
特征映射的大小计算
∵nout=⌊snin+2p−f+1⌋带入输入大小nin=224,padding大小2p=3,卷积核大小f=11,步长s=4得:nout=4227−11+1=55∵C1层一共使用了2×48个卷积核∴C1层featuremap=2×48×55×55∵系统使用双GPU进行运算∴每个GPU处理的数据为:55×55×48
-
overlapping pooling/subsamping操作
使用大小3×3,步长为2的重叠池化单元,步长小于池化单元的宽度,则输出为
nout=snin+2p−f+1带入nin=55,f=3,得:nout=255+0−3+1=27
-
局部响应归一化
3. C2层
-
输入的大小:2×48×27×27,一共两个GPU,每个GPU训练48个通道,每个通道27×27
-
C2层卷积核
-
规格:
- 使用128个大小为5×5的卷积核,卷积的步长s=1
-
padding的大小
padding=2size_filter−1带入size_filter=5得:padding=2∴C2层padding大小为2+2
-
卷积特征映射输出计算
∵nout=⌊snin+2p−f+1⌋带入nin=27,padding大小p=2,卷积核大小f=5,移动步长s=1得:nout=⌊127+2×2−5+1⌋nout=27∴特征映射为27×27的矩阵∵C2层一共有128个卷积核∴C2层输出大小为27×27×128
-
重叠池化
C2层使用大小为3×3,步长为2的重叠池化核.则池化操作后的输出为:
∵nout=snin+2p−f+1带入nin=27,p=0,f=3,s=2得:nout=227−3+1=13∴每个池化核输出大小为13×13的矩阵∵一共有128个通道∴池化后的输出大小为13×13×128
-
局部响应归一化LRN
4. C3层
不再分GPU来进行训练,而是对进行交叉,实现特征融合


