2022年了,不会还不懂Raft协议吧
本文已参与「新人创作礼」活动,一起开启掘金创作之路。
前言
为什么会学习到这个东西😩,原因很简单,在学习其他技术时,发现它出现在别的技术中不止一次,经过查阅很多资料,都说这个好用,那么究其根本,只能先把这个协议先弄懂!才能方便学习其他技术比如Etcd,Consul等
raft协议是什么
保证分布式一致性问题的瑞士军刀!
raft是一致性协议,是用来保障servers上副本一致性的一种算法。哈哈😄很简单吧!
raft协议的原理
以下是对该raft翻译后的论文进行重点摘录:
开胃菜
Raft是一个管理replicated log的算法
Raft首先会选举出一台机器作为Leader,然后让系统所有的决定都由Leader来处理,Raft通过投票和随机超时来选举Leader,选举保证Leader存有所有必要的信息,因此数据只能从Leader流向其他节点。相比于其他基于Leader的算法,这使得行为流程更简单。一旦Leader被选举出来,就由它来管理复制日志。
raft基础理论
Replicated State Machine:即多个机器拥有状态的多份copy,并能在一些机器故障时不中断的提供服务
replicated state machine用于解决分布式系统中的各种容错问题
raft主要包含Leader选举、日志复制、和安全三部分
- Leader Election:当集群启动或者leader失效时必须选出一个新的leader。
- Log Replication:leader必须接收客户端提交的日志,并将其复制到集群中的其他节点,强制其他节点的日志与leader一样。
- Safety:如果任何一个server已经在它的状态机apply了一条日志,其他的server不可能在相同的index处apply其他不同的日志条目。
Leader、Candidate、Follower三种状态
在任何时候每个server都会处于Leader、Candidate、Follower三种状态中的一种。在正常情况下会只有一个leader,其他节点都是follower,follower是消极的,他们不会主动发出请求而仅仅对来自leader和candidate的请求作出回应。leader处理所有来自客户端的请求(如果客户端访问follower,会把请求重定向到leader)
Candidate状态用来选举出一个leader
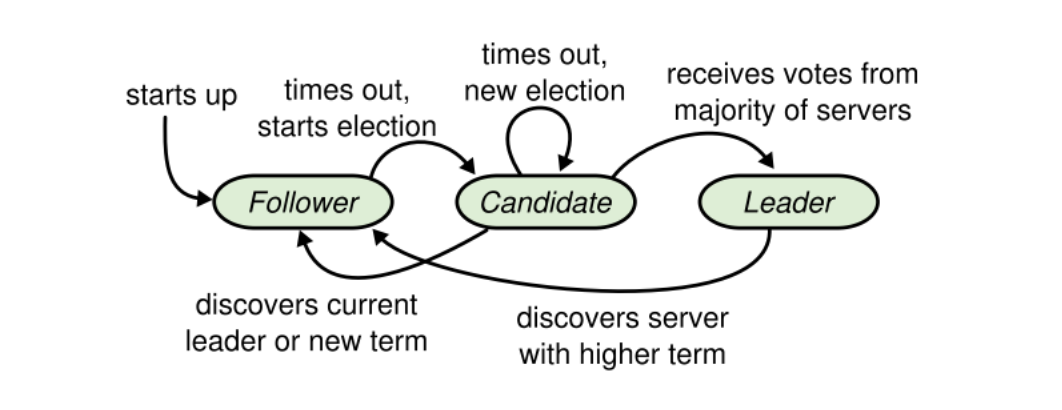
如何进行选举的
Raft将时间划分为任意长度的term,用连续整数编号。每一个term都从选举开始,一个或多个candidate想要成为leader,如果一个candidate赢得选举,它将会在剩余的term中作为leader。在一些情况下选票可能会被瓜分,导致没有leader产生,这个term将会以没有leader结束,一个新的term将会很快产生。😏Raft确保每个term至多有一个leader。Term在Raft中起到了逻辑时钟的作用,它可以帮助server检测过期信息比如过期的leader。每一个server都存储有current term字段,会自动随时间增加。当server间通信的时候,会交换current term,如果一个节点的current term比另一个小,它会自动将其更新为较大者。如果candidate或者leader发现了自己的term过期了,它会立刻转为follower状态。 如果一个节点收到了一个含有过期的term的请求,它会拒绝该请求。
选举完无非就三种结果:
- 赢得选举,成为leader: 如果它在一个term内收到了大多数的选票,将会在接下的剩余term时间内称为leader,然后就可以通过发送心跳确立自己的地位。(每一个server在一个term内只能投一张选票,并且按照先到先得的原则投出)
- 其他server成为leader: 在等待投票时,可能会收到其他server发出AppendEntries RPC心跳信号,说明其他leader已经产生了。这时通过比较自己的term编号和RPC过来的term编号,如果比对方大,说明leader的term过期了,就会拒绝该RPC,并继续保持候选人身份; 如果对方编号不比自己小,则承认对方的地位,转为follower.
- 选票被瓜分,选举失败: 如果没有candidate获取大多数选票, 则没有leader产生, candidate们等待超时后发起另一轮选举. 为了防止下一次选票还被瓜分,必须采取一些额外的措施, raft采用随机election timeout的机制防止选票被持续瓜分。通过将timeout随机设为一段区间上的某个值, 因此很大概率会有某个candidate率先超时然后赢得大部分选票.
如何进行日志复制的
一旦一个leader被选举出来,它开始为客户端请求服务。每一个客户端请求都包含着一个待状态机执行的命令,leader会将这个命令作为新的一条日志追加到自己的日志中,然后并行向其他server发出AppendEntries RPC来复制日志。当日志被安全的复制之后,leader可以将日志apply到自己的状态机,并将执行结果返回给客户端。如果follower宕机或运行很慢,甚至丢包,leader会无限的重试RPC(即使已经将结果报告给了客户端),直到所有的follower最终都存储了相同的日志。
在Raft中,leader通过强制follower复制自己的日志来解决这种不一致的情况,意味着follower和leader产生冲突的部分日志会以leader为准进行重写。
如何在宕机时还能保证安全
那肯定是持久化了,宕机了啥都玩完了,就剩硬盘了!
Raft server必须将一些必要的数据持久化以便重启后数据不丢失。首先需要持久化它当前的term和投出的选票,这可以防止节点在一个term内投出两次选票。每一个server也需要在commit前持久化最新的日志,可以防止committed日志丢失。
Leader主动下线引起的转移
为了转移领导权🥸,当前leader会把自己的日志发送给目标节点,然后目标节点提前触发一轮选举。当前leader确保了目标节点拥有全部committed日志。下面是详细步骤:
- 当前leader停止接收客户端请求
- 当前leader通过复制日志将目标节点的日志更新为和自己完全一样
- 当前leader发送一个TimeoutNow请求给目标节点。这个请求会使得目标节点立刻触发超时并开启新一轮选举。它有极大可能在其他节点超时之前赢得选举,它的下一条消息将会包含新的term编号,导致leader自动下线。leader转移完成。
这不就是拍屁股走人之前,先交接和交代一下再走人嘛😤!
关于新配置的节点
Raft在配置更新之前引入了一个额外的阶段,期间新加入的节点不占有投票权,leader会将日志复制给它,但是选举或者commit时统计多数选票都不会计入它。一旦新节点的日志追上来,配置便可以开始更新了,
有一个不可用时间,超过的话则停止更新在下一轮再更新!
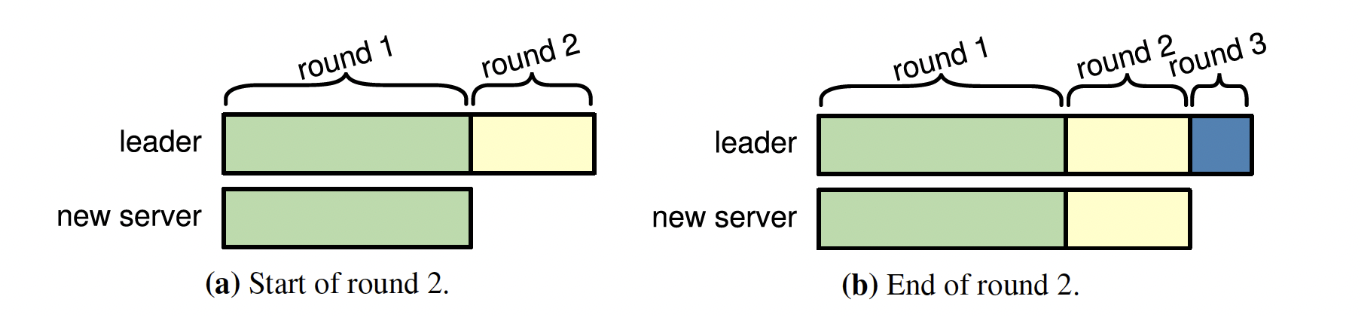
什么是下一轮?实际新节点更新日志是有一个算法的!什么什么算法来让大家瞧瞧:
将对新节点的复制日志过程划分为几轮,如图4.5,每一轮复制从开始到现在的所有日志给新节点,由于在复制日志的过程中,leader会继续接收新的日志,这些新加的日志会在下一轮进行复制,随着不断的进行,每一轮次复制的持续时间会不断缩短,当算法等待几个轮次(比如10)的复制之后,如果最后一轮的持续时间短于election timeout,leader就可以将新节点正式加入集群,否则leader就会中断配置更新并返回错误,调用者之后可以进行重试(下次重新更有可能成功,因为该节点的日志已经部分赶了上来)。