张志华 统计机器学习_Leibniz infinity sml的博客-CSDN博客
统计机器学习-张志华-例子-Bayesian Linear Models
Bayesian Linear Models
问题描述:
yi=xiTb+ϵi
yi∈R
xiT∈Rp
D={(x1,y1),(x2,y2),...,(xi,yi),...,(xn,yn)}
假定:ϵi∼N(0,σ2)
这里实际上描述了 p(D∣b,σ2)是个高斯分布 即: p(D∣b,σ2)=∏i=1np(ϵi∣b,σ2)
p(b,σ2)=p(b∣σ2)p(σ2)
给分布:
p(b∣σ2)=N(m,σ2v)
p(σ2)=InverseGamma(a,b)
演算:
p(b,σ2)=(2π)2p∣v∣21Γ(a)baσ2(−a+2p+1)e−((b−m)Tv−1(b−m)+2b)/2v2
p(D∣b,σ2)
应该让p(b,σ2∣D)和p(b∣σ2)有相同的形式,即共轭:
p(b,σ2∣D)=N(m^,v^)InverseGamma(a^,b^) (p(b,σ2∣D)的共轭样子式)
p(b,σ2∣D) 是 Gibbs采样中 提到的 f(b,σ2)
p(b,σ2∣D)=p(D)p(D∣b,σ2)p(b,σ2)
演算:
p(b,σ2∣D)∝p(D∣b,σ2)p(b,σ2)
p(b,σ2∣D)∝(∏i=1np(ϵi∣b,σ2))p(b,σ2) ,把右边凑成 "p(b,σ2∣D)的共轭样子式" 的样子
之后 开始抽样(比如用gibbs采样):
给定σ2, 从f(b∣σ2)中抽b
给定b , 从f(σ2∣b)中抽σ2
遗留问题: 超参数 比如 a、b 应该设置成多少? (?初始化?应该设置成多少?)
说是有些papaer中有说
有说一篇paper , 没听明白名字 : ?rjx? 单元 多元 高斯问题?
统计机器学习-张志华-例子-Bayesian Classsification
yi∈{0,1} (y的下标i是我自己加的)
p(yi∣b)=(μi(b))y(1−μi(b))(1−y) : Bernoulli Distribution (伯努利分布) (y的下标i是我自己加的) (p(yi∣b)式子)
μi(b)=h(xiTb)
p(D∣b)=∏i=1np(yi∣b) 带入"p(yi∣b)式子",得:
p(D∣b)=∏i=1n((μi(b))y(1−μi(b))(1−y)) "p(D∣b)式子"
(xi,yi)是一个样本, 共n个样本 (这句话是我自己加的)
h函数说明:
h函数的作用是将输入映射到区间[0,1]之间,因为上式伯努利分布中的μ(b)需要是在区间[0,1]之间。
h通常有以下两种:
h(η)=1+eηeη 即sigmoid函数
h(η)=Φ(η)=∫−∞η2π1e−2t2dt 积分里的式子是标准高斯分布的cdf
临时插的话:
?probit model? 说的是 Φ(η)?
继续
b∼N(m,v)
概率图
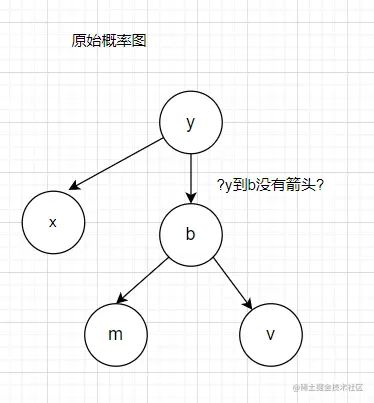
直接带入得不到共轭形式: (所以需要 用auxiliary variable method)
p(b∣D)=p(D)p(D∣b)p(b) 去掉?常数项p(D)?,得:
p(b∣D)∝p(D∣b)p(b) ,带入 "p(D∣b)式子"得:
p(b∣D)∝(∏i=1n((μi(b))y(1−μi(b))(1−y)))p(b) 注意,这个式子由于 "y在指数中: ∗y, ∗1−y " 导致这个式子不可能和 "p(b):高斯分布" 的形式一致, 即这个式子不会和"p(b):高斯分布"共轭,因此不能这么写(得想其他办法)
("? 还是由于b的指数是y? ")
(题外话)data augmentation (DA) (数据增强) : 实质是 ?增加中间变量? , 比如以下方法:
auxiliary variable method (辅助变量法)
EM算法 (expectation maximization algorithm)
latent (隐变量)
auxiliary variable method (辅助变量法)
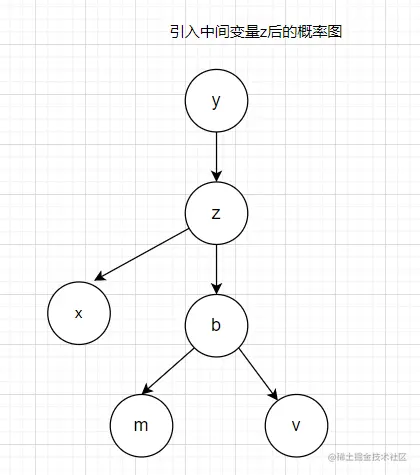
增加变量z
引入变量z后的概率图
引入中间变量z前后的概率图对比
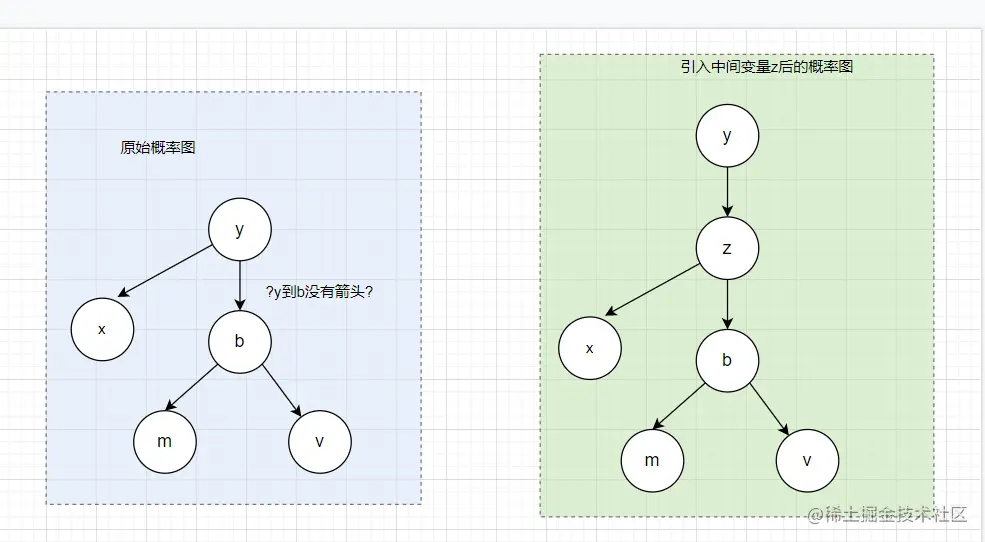
auxiliary variable method (辅助变量法) 继续:
z=xTb+ϵ , 而 ϵ∼N(0,1), 这里的 xT就是η,得:
z=η+ϵ
auxiliary variable method (辅助变量法) 继续:
接着 给出y和z之间的关系:
p(y=1∣z,b)=1;如果z>0
p(y=1∣z,b)=0;otherwise
并且: p(y=0∣z,b)=1−p(y=1∣z,b)
(从概率图上可以看出:z给定时,y与b无关。 所以这个式子中也是这样反映的)
从上式子可以看出:
p(y=1∣z>0,b)=1, p(y=1∣z≤0,b)=0 (p(y=1|z **, b)式子)
auxiliary variable method (辅助变量法) 继续:
求 p(y=1∣b)
p(y=1∣b)=p(y=1∣z>0,b)p(z>0∣b)+p(y=1∣z≤0,b)p(z≤0∣b),代入 "p(y=1|z **, b)式子" ,得:
p(y=1∣b)=1∗p(z>0∣b)+0∗p(z≤0∣b),即,得:
p(y=1∣b)=p(z>0∣b)

废纸箱或垃圾箱:
以下这两个式子是没有下标i的,是张志华老师在[Bayes classifycation]
(www.bilibili.com/video/BV1rW…
p(y∣b)=(μ(b))y(1−μ(b))(1−y) : Bernoulli Distribution (伯努利分布)
μ(b)=h(xTb)
需要回答的问题:
为什么要共轭?这个问题估计要继续看完 统计机器学习-张志华 这门课 才有可能有答案
统计机器学习-张志华-教学材料
统计机器学习-张志华
正确的播放顺序:
4.高斯分布
6.连续分布
5.例子
8.scale mixture pisribarin
7.jeffrey prior
9.statistic interence
40.Markov Chain Monte carlo1
39.Bayesian Classification
(40, 39, 特别是39中的例子, 可以使得把mcmc搞明白)
不用看 "41.Markov Chain Monte carlo2", 因为41和40后半部分一模一样
可能会有些用处: 朗道理论物理教程-统计物理学I.pdf
这本书中有一些类似应用题一样的例子,或许可以看看:随机过程(Sheldon M.Ross 著).pdf
知乎这个人列出来不少统计专业的书籍,或许可以看看: 统计专业书籍推荐
非参数统计 by 陈希孺.pdf
非参数统计 by 陈希孺.pdf zh.u1lib.org
据说有案例?:非参数统计:基于R语言案例分析
机器学习导论-张志华
应用数学基础 张志华
强化学习基础 张志华
实验例子
Deep Learning 中文翻译
张志华 课表

概率分布
GaussionDistribution
Bernoulli Distribution
BernoulliDistribution

练习
试着 将 bayes inference 框架: pyro, 例子 与 理论课 联系起来
试着例子联系理论
例子
理论
 例子 联系 理论
例子 联系 理论
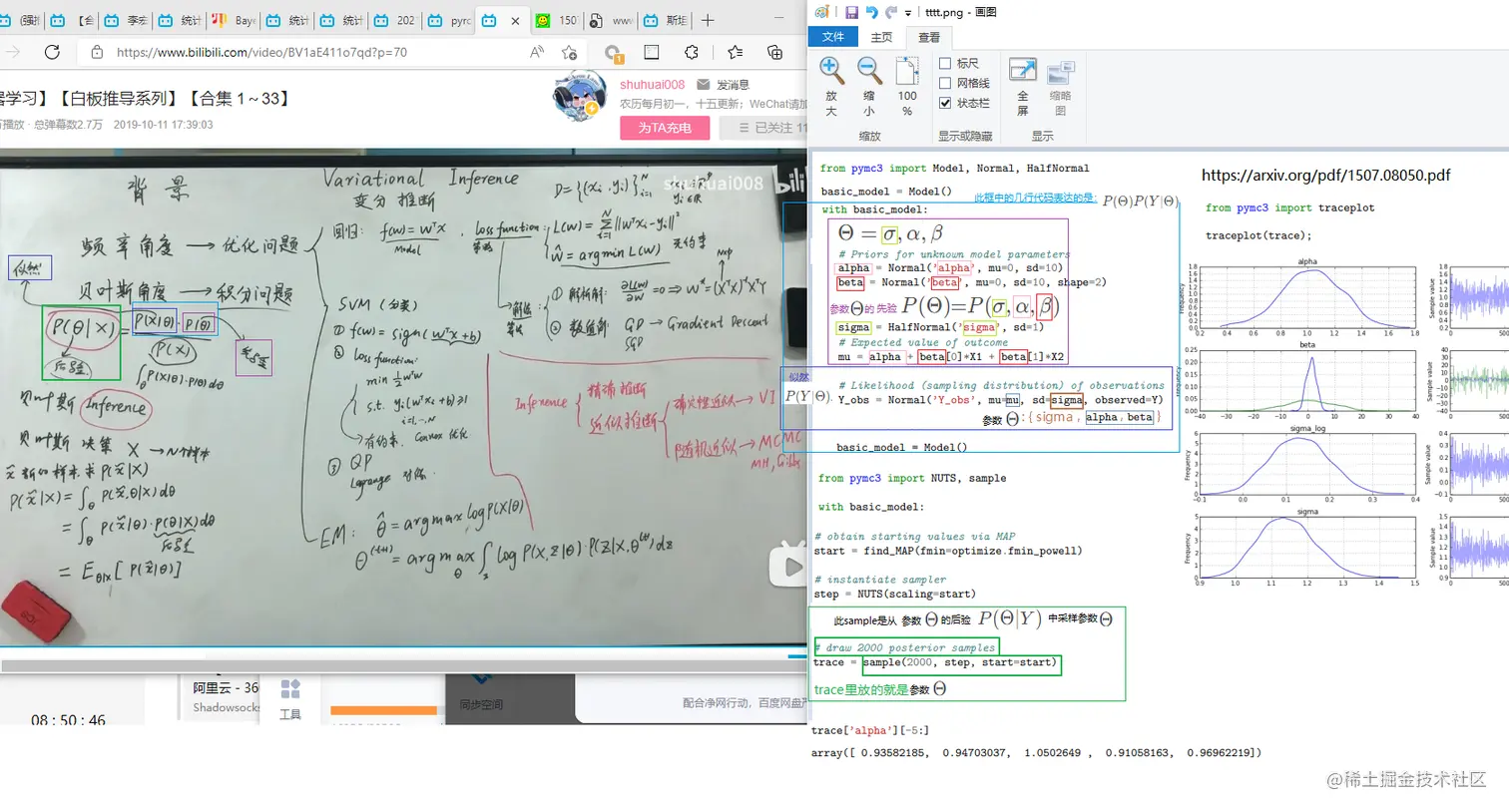
概率图 实例 候选
google search :
mcmc github
mcmc julia
julia mcmc : Mamba
paperswithcode : variational-inference
 Gaussian Progress by pytorch :gppytorch
Gaussian Progress by pytorch :gppytorch
julia mcmc : doobwa/MCMC.jl
mcmc js demo 采样过程ui展示
gibbs sampling python 简单例子 直接是main方法运行
MCMCChains julia: 运行出图?不太确定啥用处
julia turing.ml 09-variational-inference
草稿或垃圾桶
P(Θ∣Y)=P(X)P(Θ)P(Y∣Θ)
Θ=σ,α,β
P(Θ)=P(σ,α,β)
其他资源
西瓜书 李航统计学习方法 实践部分
代码 资料


