

前言
在上一节中已经部署了Selenium+chromedriver的开发环境,在真正的开发之前,还需要学会利用浏览器来查找网页元素。
因为Selenium是通过程序来自动操控网页的控件元素,比如单击某个按钮、输入文本框内容等,若网页中有多个同类型的元素,好比有多个按钮,想要Selenium精准地单击目标元素,需要将目标元素的具体信息告知Selenium,让它根据这些信息在网页上找到该元素并进行操控。
浏览器开发者工具部分讲解
网页的元素信息是通过浏览器的开发者工具来获取。以Google Chrome为例,在浏览器上访问
然后按快捷键F12打开Chrome的开发者工具(部分电脑要用 fn +12 ),如下图
从上图可以看到,开发者工具的界面共有9个标签页,分别是Elements、Console、Sources、Network、Performance、Memory、Application、Security和Audits。
开发者工具以Web开发调试为主,如果只是获取网页元素信息,只需熟练掌握Elements标签页即可。Elements标签页允许从浏览器的角度查看页面,也就是说,可以看到Chrome渲染页面所需要的HTML、CSS和DOM(Document Object Model)对象,此外,还可以编辑内容更改页面显示效果,它一共分为两部分,左边是当前网页的HTML内容,右边是某个元素的CSS布局内容;查找元素信息以左边的HTML内容为主。
HTML相关知识讲解
在查找控件信息之前,首先了解HTML的相关知识。HTML是超文本标记语言,这是标准通用标记语言下的一个应用。“超文本”就是指页面内可以包含图片、链接,甚至音乐、程序等非文字元素。超文本标记语言的结构包括“头”部分(Head)和“主体”部分(Body),其中“头”部分提供关于网页的信息,“主体”部分提供网页的具体内容。通过一个简单HTML来进一步了解:
# 司马弈博客:chengf.cc
# 声明为HTML5标准的文档
<!DOTYPE html>
# 元素是html也没的根元素
<html>
# 包含了文档部分的元(meta)数据
<head>
#提供主要页面的元信息,主要是描述和关键词
<meta charset="utf-8">
#元素描述了文档的标题
<title>司马弈博客 chengf.cc</title>
</head>
#元素包含了可见的页面内容
<body>
#定义一个一级(h1)标题
<h1>我的一级标题</h1>
#定义一个段落(p标签)
<p>我的第一个段落</p>
</body>
</html>
一个完整的网页必定以为开头和结尾。
整个HTML可分为两部分:
(1)是对网页的描述、图片和JavaScript的引用。元素包含所有的头部标签元素。在元素中可以插入脚本(scripts)、样式文件(CSS)及各种meta信息。该区域可添加的元素标签有、、、、、和。
(2)是网页信息的主要载体。该标签下还可以包含很多类别的标签,不同的标签有不同的作用。每个标签都是以<>开头,以</>结尾,<>和</>之间的内容是标签的值和属性,每个标签之间可以是相互独立的,也可以是嵌套、层层递进的关系。根据这两个组成部分就能很容易地分析整个网页的布局。其中,是整个HTML的重点部分。
“主体”部分(Body)的使用方式,我们进行详细分析,说明如下:
(1)
、和是互不相关的标签,三个标签之间是相互独立的。
(2)
标签和里面的标签是嵌套关系,
的上一级标签是
。
(3)
和
是两个毫无关系的标签。
(4)
标签包含一个
标签,
标签再包含一个标签,一个标签可以嵌套多个标签。
除上述示例的标签之外,大部分标签都可以在中使用,常用的标签如下表:
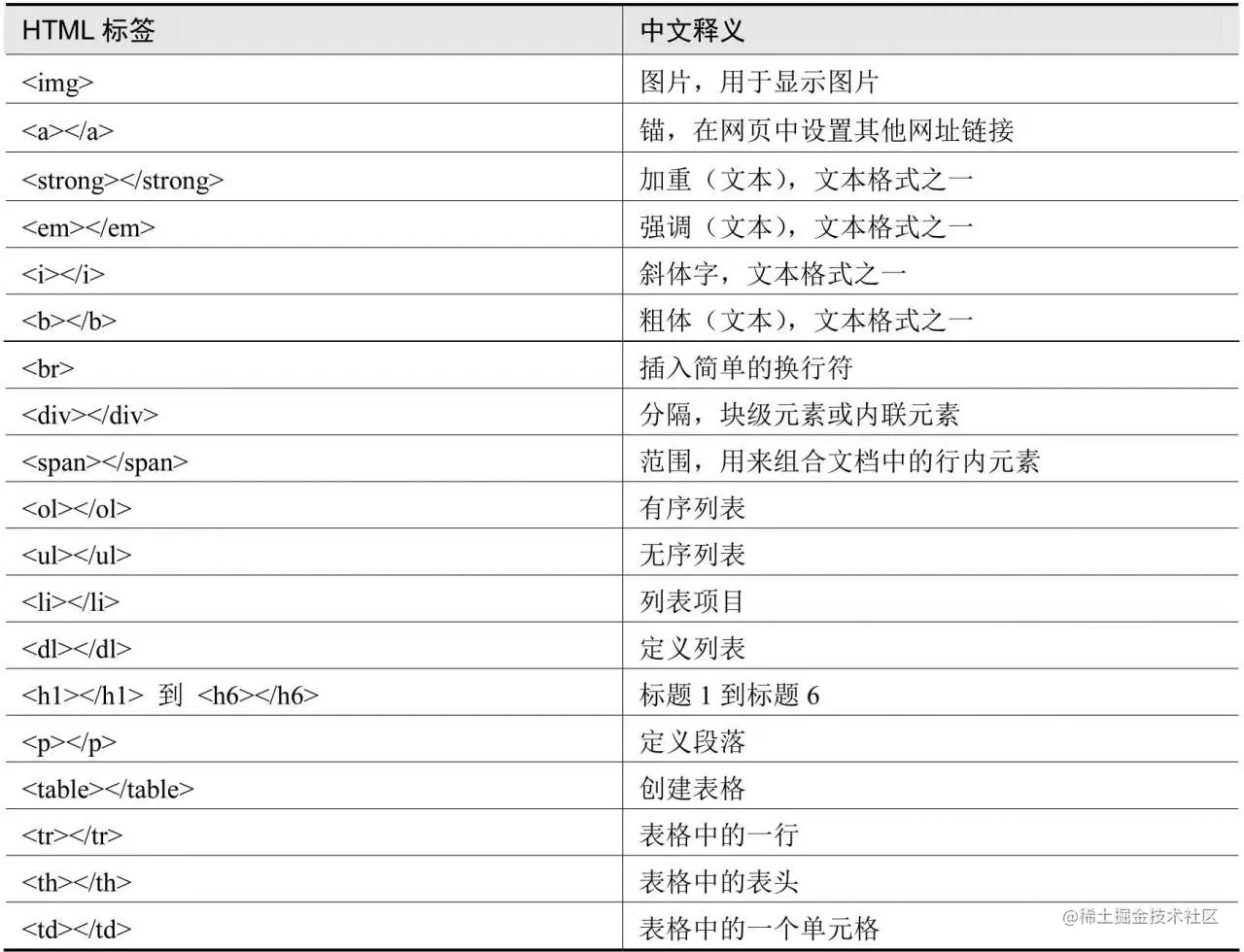
使用浏览器查找元素
大致了解了HTML的结构组成,接下来使用开发者工具来查找网页元素。比如查找腾讯网的搜索框在HTML里所在的位置,我们可以单击开发者工具的“小箭头按钮”按钮,然后将鼠标移到网页上的搜索框并单击,最后在Elements标签页里自动显示搜索框在HTML里的元素信息,具体操作如图:
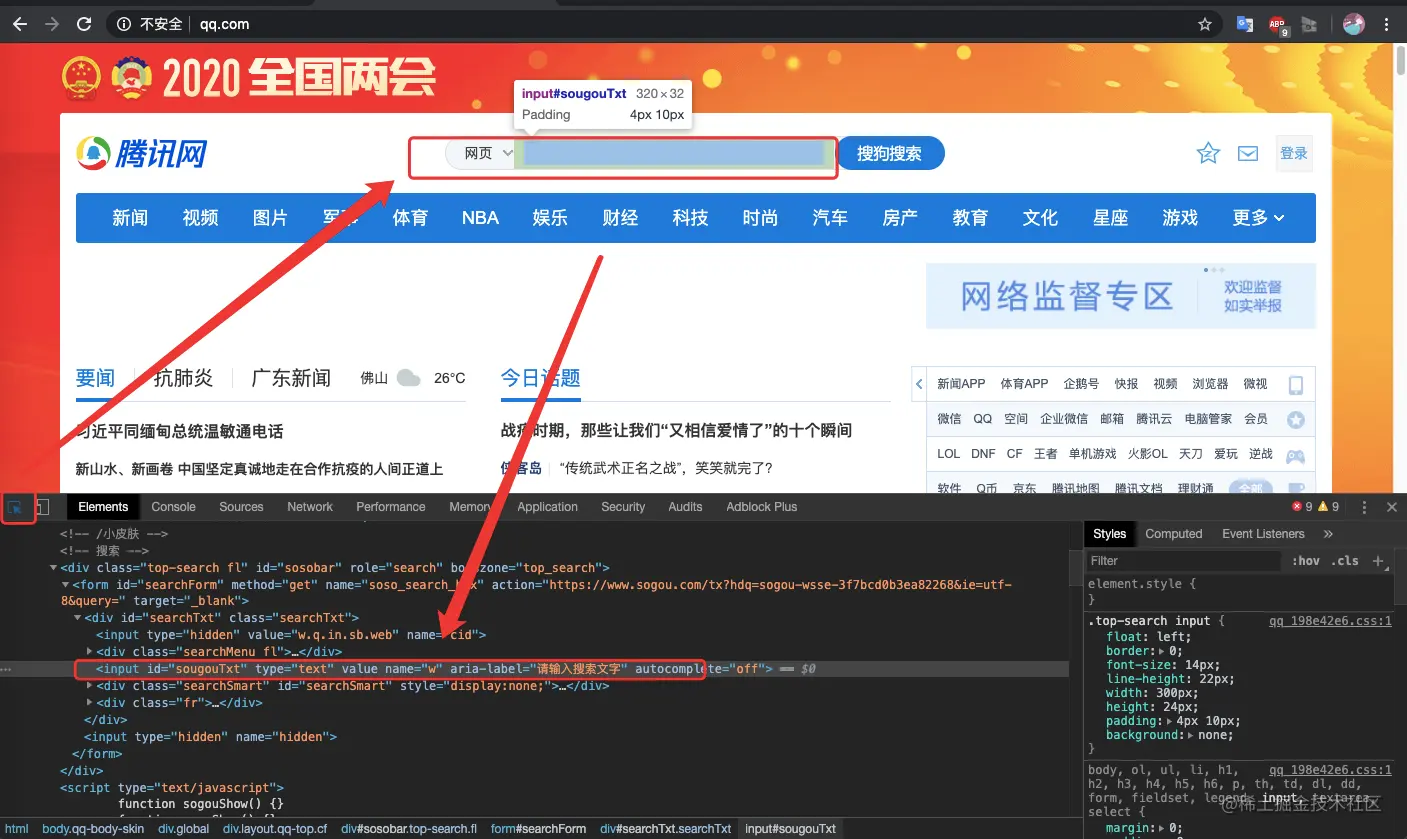
从图上可以看到,网页中的搜索框是由标签生成的,该标签的上一级标签是
。标签有属性id、name、size和maxlength等,这些属性值是这个标签特有的,我们可以通过这些属性值来告诉Selenium,让它根据这些属性值去操控这个搜索框。
是互不相关的标签,三个标签之间是相互独立的。
(2)
标签是嵌套关系,
的上一级标签是
(3)
和
是两个毫无关系的标签。
(4)
标签包含一个
标签,
标签再包含一个标签,一个标签可以嵌套多个标签。
除上述示例的标签之外,大部分标签都可以在中使用,常用的标签如下表:
使用浏览器查找元素
大致了解了HTML的结构组成,接下来使用开发者工具来查找网页元素。比如查找腾讯网的搜索框在HTML里所在的位置,我们可以单击开发者工具的“小箭头按钮”按钮,然后将鼠标移到网页上的搜索框并单击,最后在Elements标签页里自动显示搜索框在HTML里的元素信息,具体操作如图:
从图上可以看到,网页中的搜索框是由标签生成的,该标签的上一级标签是
