首先来思考一下,一个简单的DNN中,梯度与哪些因素有关?
先来一个简单的3层神经网络
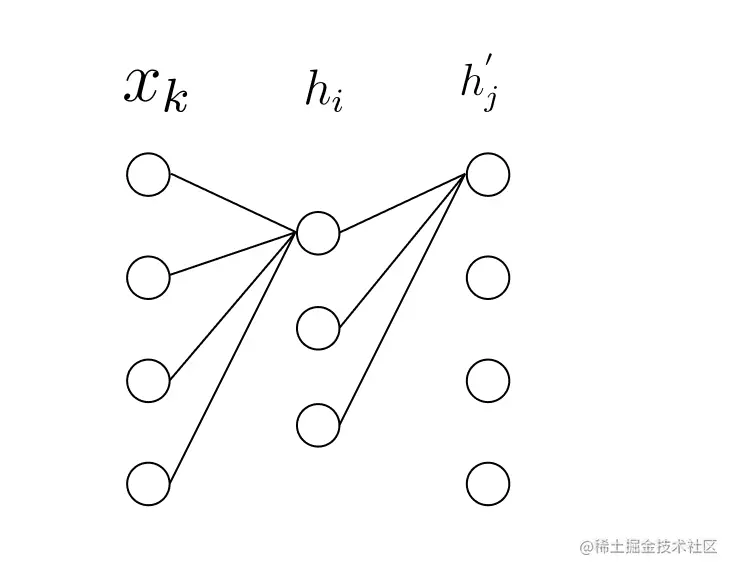
第一层的输出为
hi=σ(ui)=σ(k=1∑Kwkixk+bi)
第二层的输出为
hj′=σ(uj′)=σ(i=1∑Iwij′hi+bj)
损失函数为
E=CE(yj;hj′)=yjlog(hj′)+(1−yj)log(1−hj′)
求导:
对第二层求导
δwij′δE=δhj′δEδuj′δhj′δwij′δuj′
一共三个部分,一个部分一个部分来
交叉熵求导
δhj′δE=hj′(yj)(1−hj′)(yj)=hj′(1−hj′)yj−hj′
激活函数求导(假设是sigmoid)
δuj′δhj′=hj′(1−hj′)
最后对权重求导
δwij′δuj′=hi
三个部分合并到一起即为第二层的权重
δwij′δE=(yj−hj′)hi
可以看到该层的权重与输入值hi、输出值hj′还有标签yj有关。
对第一层求导
过程类似,结果为
δwkiδE=(yj−hj′)wij′hi(1−hi)xki
可以看到,某一层的梯度与
- 后一层的输出值
- 标签
- 后一层权重
- 激活函数求导(hi(1−hi)其实就是sigmoid的导数)
- 输入值
相关
这里可以引申出为什么会梯度爆炸/梯度消失
爆炸:
- 权重初始化不合理,反向传播过程中后一层的权重会影响本层的梯度,权重均值大于1就会爆炸
消失:
- 激活函数的导数值,例如sigmoid,在0附近的导数最大,但也仅有0.25,层层传递下去就🈚️了


