最小可用版本(MVP)技术方案:
MVP实现:
建模:
互关功能比较简单,一般来说,除了用户主表,只需要一张中间表来存储用户之间的关系即可:
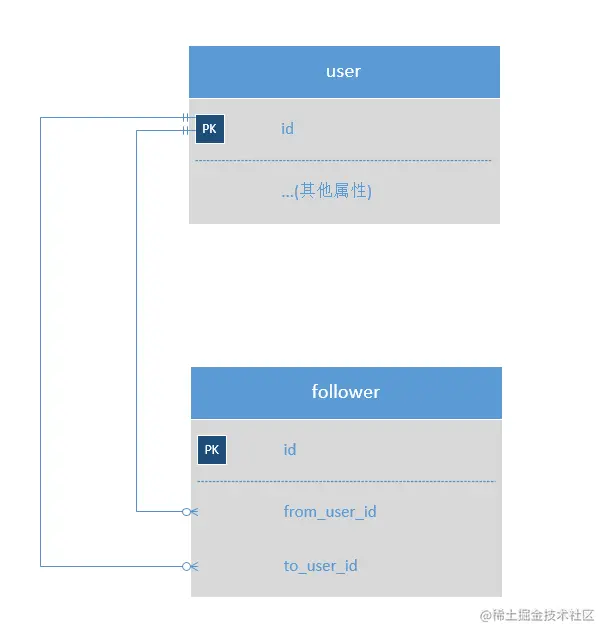
接口逻辑:
1、关注某人:
在follower中添加一条from_user_id为当前登录用户,to_user_id为被关注者id。
2、取关某人:
将follower中from_user_id为当前登录用户,并且to_user_id为某人Id的数据删除,或者逻辑删除
3、关注当前用户的人列表(粉丝):
查询to_user_id为当前登录用户Id的所有用户Id,然后去user表查询用户缩略信息,比如头像,昵称等,
为了展示是否互关,还需要再查询from_user_id为当前登录用户的所有用户id,然后进行一一匹配,
可以匹配上的,可以认为是已经互关,在Vo层展示的时候可以加一个是否互关字段,用于展示是否互关。
4、关注某用户的人列表(某用户的粉丝):
查询to_user_id为某用户Id的所有用户Id,然后去user表查询用户缩略信息,比如头像,昵称等,
此接口与3类似,只是不需要查互关,也可将此接口和3接口合并。
5、当前登录用户关注的人(我的关注):
查询from_user_id为当前登录用户的所有用户id,然后去user表查询用户缩略信息,比如头像,昵称等,
同理,为了展示是否互关,还需要再查询to_user_id为当前登录用户的所有用户id,然后进行一一匹配,
可以匹配上的,可以认为是已经互关,在Vo层展示的时候可以加一个是否互关字段,用于展示是否互关。
6、某用户关注的人(某用户的关注):
此接口与5类似,只是不需要查互关,也可将此接口和5接口合并。
7、获取我的关注数量和粉丝数量:
分别查询from_user_id等于当前登录用户的数量和from_user_id等于当前登录用户的数量。
部署方案:
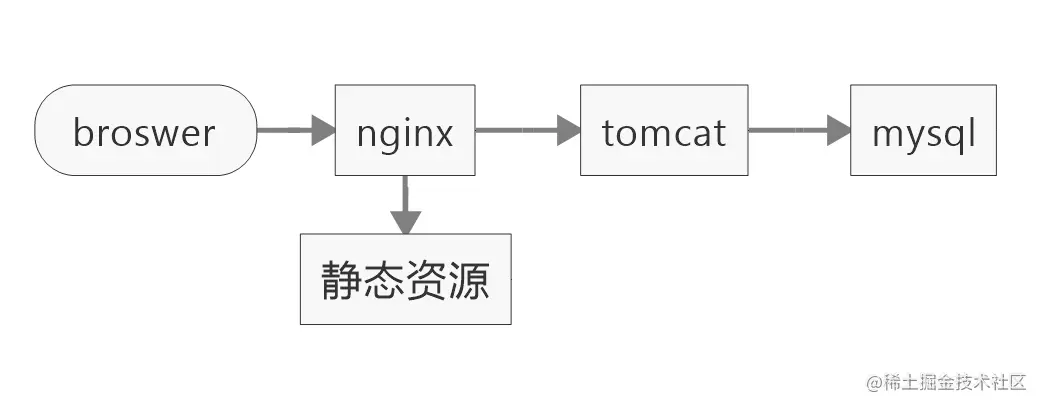
MVP部署方案,旨在首先将功能跑通,然后再在此基础上进行部署架构的优化。
依赖组件:
nginx:代理页面静态资源,和api
tomcat:部署应用
mysql:持久化数据
总结:
OK,MVP版本已经有了,并且,从可行性,和逻辑上面来看,应该是可以的,
但是~~,这个版本有什么不足呢?接下来咱们总结一下MVP的不足
不足:
1、主键使用的数据库自带的id,这个无法应对分库分表的场景。
2、查询互关的时候,需要查两遍库,增加IO次数,并且需要匹配,也会降低接口性能。
3、获取用户粉丝数和关注数时,使用count的方法,在数据量级上来之后,还是会导致性能问题。
4、follower表的数据是基本成指数级增长,
比如,如果系统有1W的用户量,最糟糕的情况下,可能会产生小2亿的数据(不过一般达不到),
但随着用户量的增加,这个表数据量会非常惊人。
5、MVP版本部署,首先系统的吞吐量会比较低,其次,服务是处于一个无法容灾的状态,完全没有高可用。
所以,我们要对这个版本进行一些改进。
改进
V2:
根据MVP中的不足,我们首先对建模进行优化。
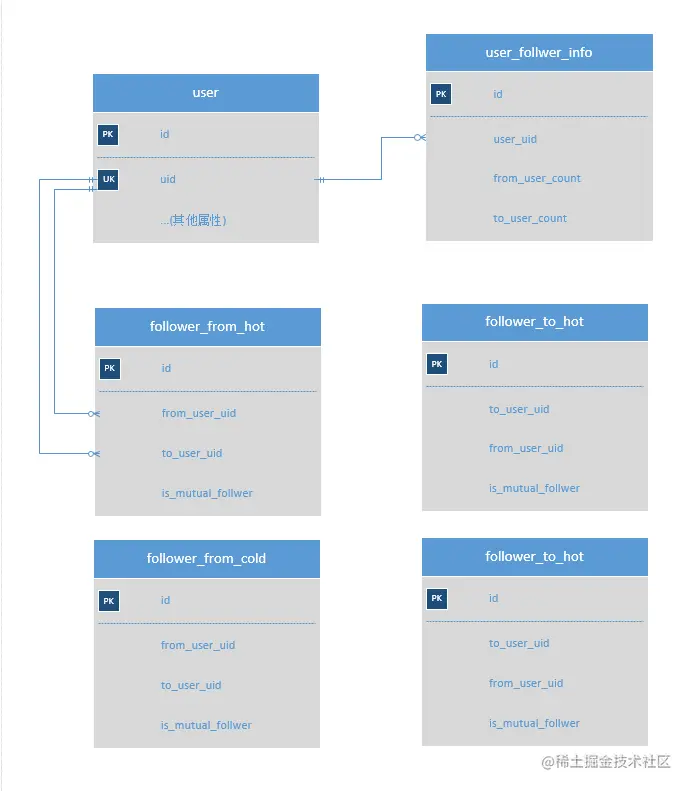
本方案针对MVP版本的不足进行了一一优化:
1、增加uid,作为业务主键,方便后续分库分表。
2、在follower表中增加is_mutual_follwer标识是否互关,
在关注接口获取,取关接口对此值进行修改,可以提升查询时的速度。
因为正常情况下都是读多写少。
3、增加user_follower_info用来保存用户的关注数和粉丝数,避免使用count(*)导致性能问题。
4、对follower表进行拆分,拆成follwer_from表和follower_to表,
分别表示用户关注和用户粉丝,方便后续对表水平拆分。
另外,为了进一步对表进行拆分,减少对大表的检索,
将follwer_from表和follower_to表,分别拆分为follwer_from_hot表、follwer_from_cold表、
follower_to_hot表和follwer_to_cold表,用来存储热点数据,
按关注的先后顺序区分热点数据,
在follwer_from_hot表,只保存每个人用户前100百(或者业务自己定)的数据,
当新关注其他人时,先检查数量是否大于100,
然后如果大于则将最旧挪到follwer_from_cold表,然后再将新数据插入此表。
follwer_to_hot同理。
此优化主要针对,大部分情况下,用户都是只看前面关注数,不会深度查询,这样可以增加较快的查询效率,
尤其针对一些大V账号,动不动都是百万甚至千万级别的粉丝,效果尤其显著。
5、部署优化:
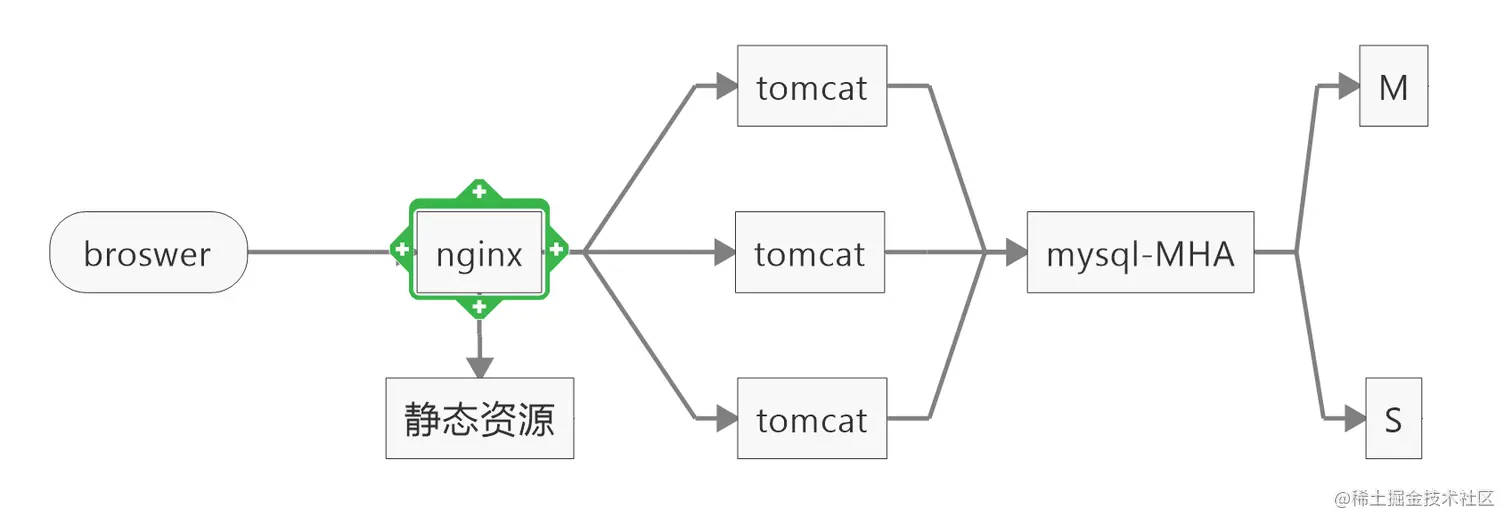
这个部署架构,比MVP版本已经具有了一定的可用性,应用服务可以有负载均衡,数据库有MHA。
继续总结:
我们再看看V2版本还有哪些不足?
从模型上面来看,咱们的优化似乎已经没有再优化的余地了,但是数据量还在持续增加,so,怎么办呢?
想必大家心中已有答案,对,没错,上缓存。
一般来说,缓存可以选择redis,memcache,
咱们以redis为例,可以将用户的基本信息,比如用户昵称,头像,uid等信息缓存至redis,
用户的follwer_from_hot和follwer_to_hot缓存至redis,
用户的关注数和粉丝数也缓存至redis,
这样,又可以大大增加系统的吞吐量,
为了保证缓存和数据库的一致性问题,我们可以在中间加一层rocketMQ,用rocketMQ的半事务消息来保证。
所以,架构进一步升级。
继续改进:
V3:
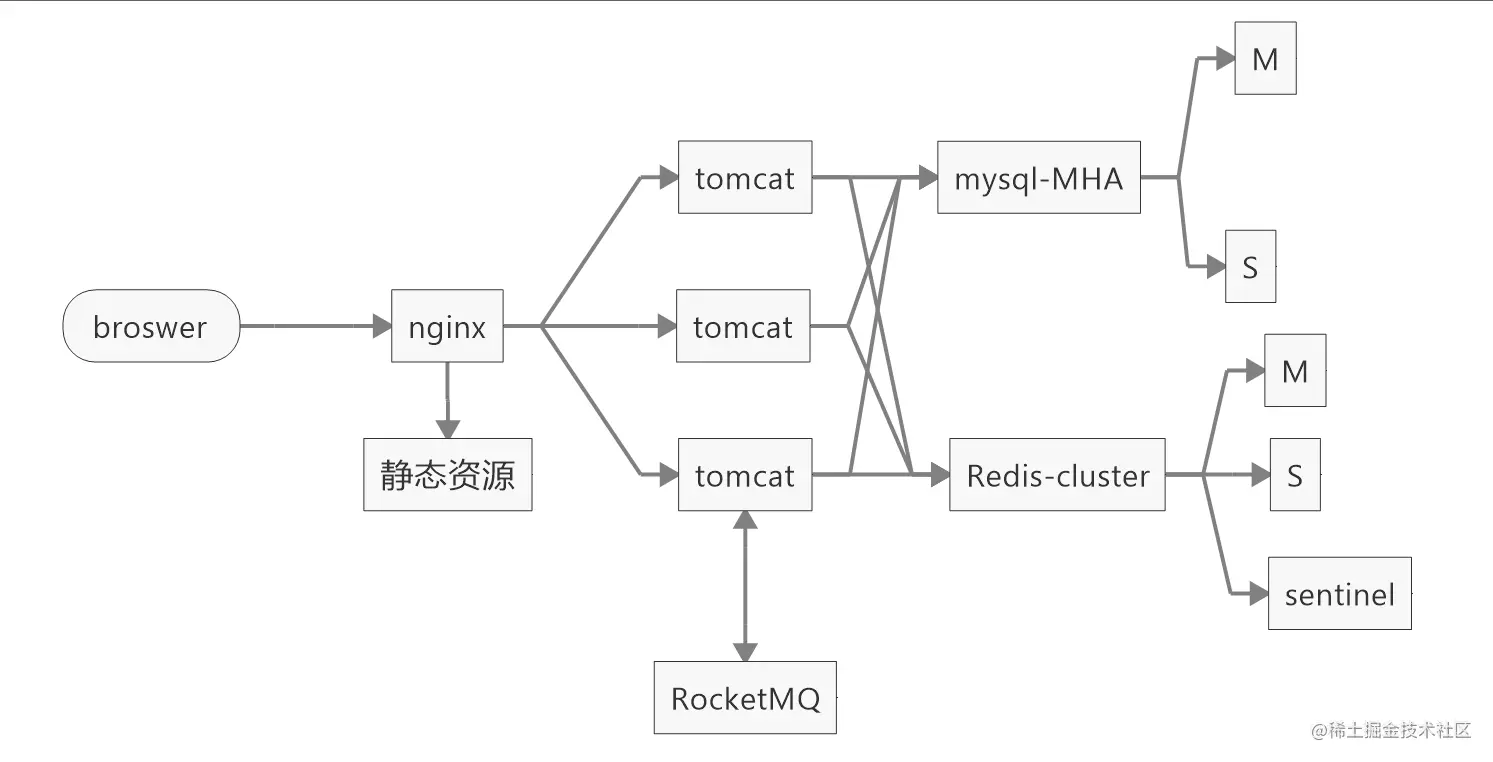
继续总结
此部署架构,基本就是一个可以应对较高并发的架构了,但是像微博这样的并发量,此架构显然无法承载,
因为,仅考虑国内用户的话,基本就分为了三大区域,
华南、华中、华北,而这三大区域的网络运营商是不一样的,
所以,如果服务器部署在华北,很有可能造成华中和华南用户的体验不如华北,
所以就需要多机房部署,应对不同地区的用户,
当然,上面的nginx还是一台,这个显然也是无法满足的,所以,上SLB也是势在必行。
因此,我们进一步优化。
继续改进
V4
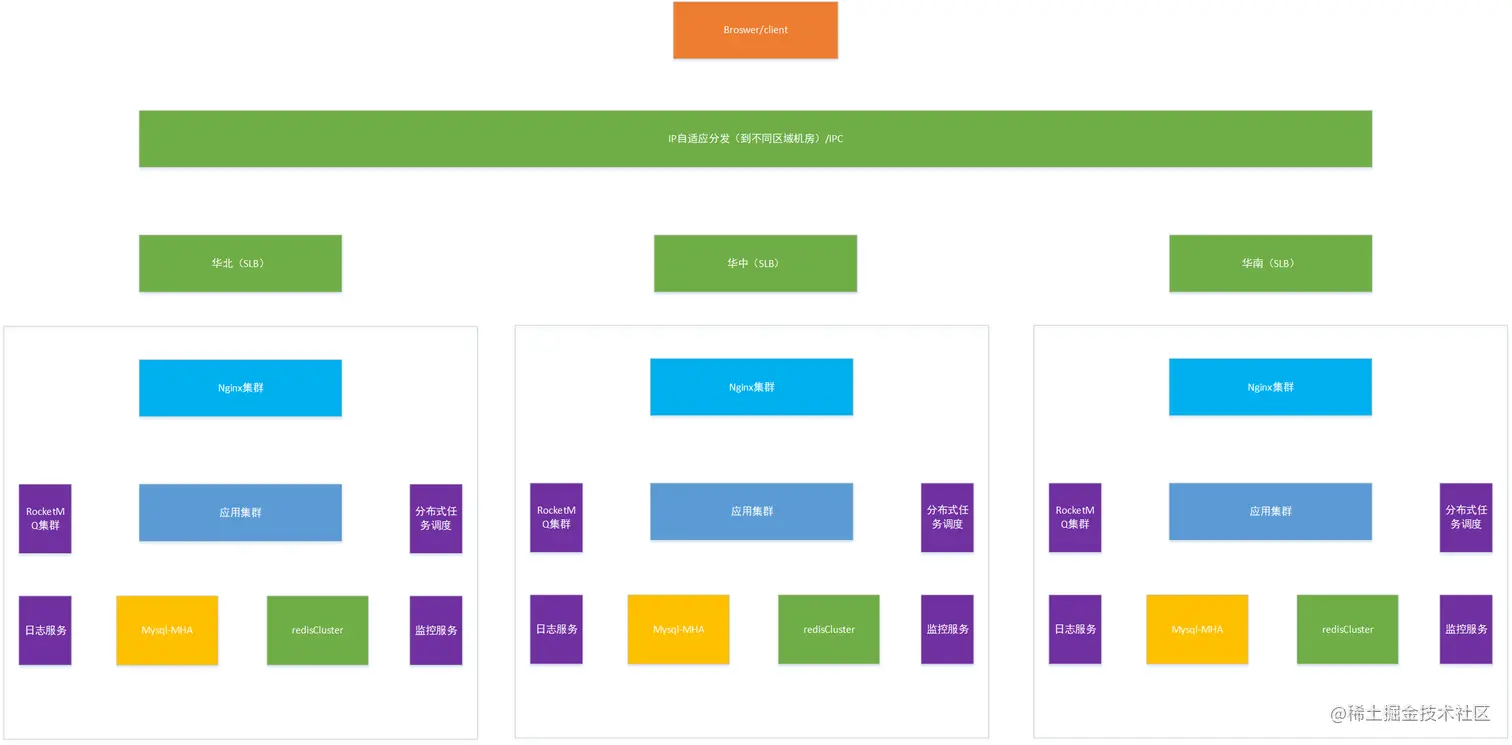
至此,基本已经可以应对高并发了,
如果数据量不断增加的话,可以通过使用Mycat或者sharding JDBC进行分库分表。
增加分布式任务调度是为了保证缓存和数据库的一致性,
因为不能单纯靠rocketmq去保证一致性,
增加日志服务为了后续审计数据,
增加监控服务,快速感知应用服务和中间件等服务的状态。
当然,代码层面依然有优化的空间,
比如,
可以使用WebFlux和complatablefeture进行编程,将有所有方法改成异步,
这样可以进一步提升系统的吞吐量。
并且可以增加一级缓存,继续提升系统性能,采用mq进行一级缓存和redis直接数据同步。


