Multi-Modal Distance Metric Learning
简介
随着社交媒体的快速发展,多模态数据正在急剧增加,本文提出了一种有效的、可扩展的多模态距离度量学习框架。该方法基于multi-wing harmonium 模型,提供了一种原则性的方法,可以将任意形态的数据嵌入到一个单一的潜在空间中,在适当的监督下,可以得到一个最优的距离矩阵,即最优距离矩阵(即最小化相似对之间的距离,最大化不相似对间的距离)。
Multi-Modal Distance Metric Learning
Multi-Wing Harmonium 模型
dual-wing harmonium 模型(DWH)如图1所示,它由两种输入单元模态组成:X={xi},Z={zj},H={hk}为一组隐藏单元。在这种无向图模型中,两种输入模式之间不存在联系。每个输入单元的模态和隐藏单元形成一个完全二分图,其中同一组中的单元没有连接,而另一组中单元完全连接。
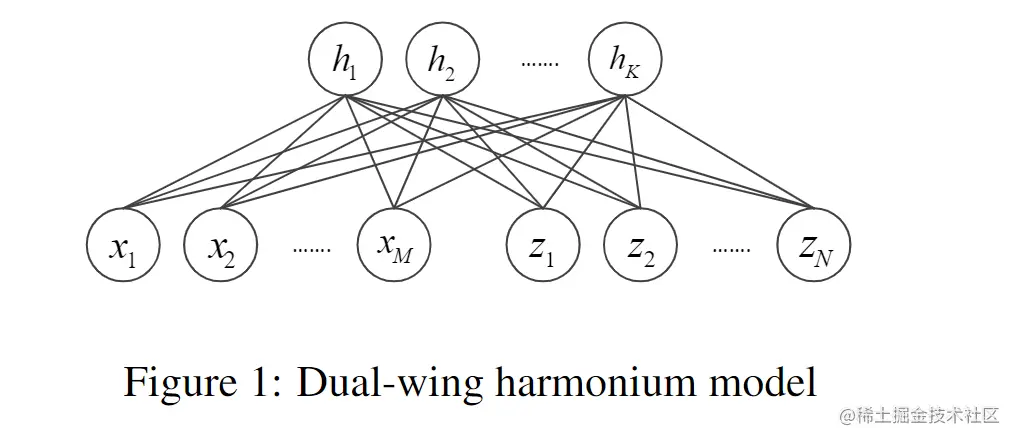
这种拓扑结构引出了3个条件独立假设:
- 给定潜在变量H时,两个模态X,Z是相互独立的:p(X,Z∣H)=p(X∣H)p(Z∣H)
- 给定X,Z时,H中的每个单元是互相独立的:p(K∣X,Z)=∏kp(hk∣X,Z)
- 给定H,每种模态的单位都是独立的:p(X∣H)=∏ip(xi∣H),p(Z∣H)=∏j(zj∣H)
考虑所有观察到的和隐藏的变量都来自于指数族(exponential family)的情况,可以得到:
p(xi)=eθiTϕ(xi)−A(θi),p(zj)=eηjTφ(zj)−B(ηj),p(hK)=eλkTψ(hk)−C(λk)
θi,ηj,λk为自然参数,ϕ(),φ(),ψ()为充分统计量,A(),B(),C()为对数配分函数。(关于指数族分布的基础知识)
通过引入一个附件项耦合对数域上的随机变量,得到联合分布形式:
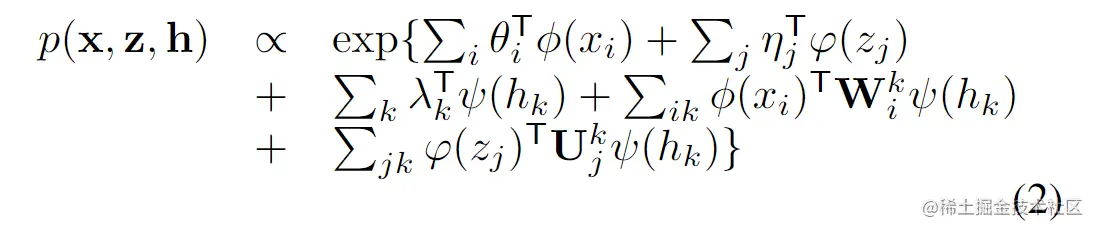
使用Θ来表示所有的参数(θ,η,λ,W,U)。根据联合分布得到条件分布:
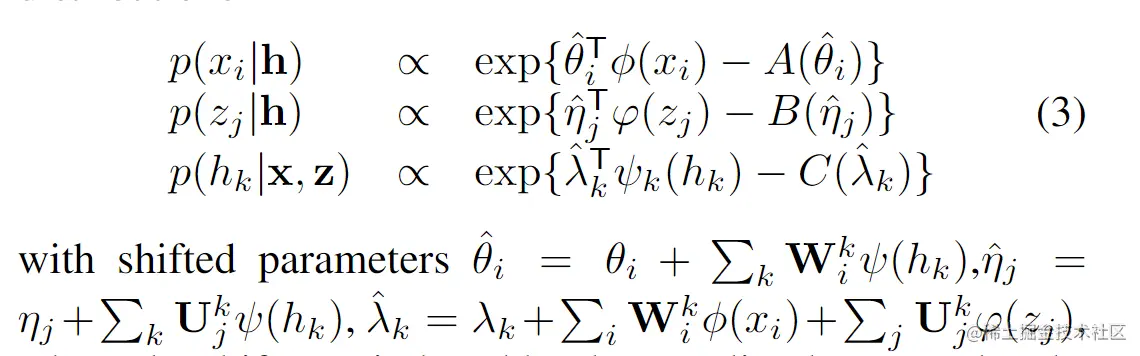
此处的shifts是基于观察到的和隐藏单元间的耦合关系确定。
根据具体的应用可以首先指定公式(3)中的本地条件分布,然后还计算公式(2)中的联合分布,这就是所谓的自下而上的dual-wing harmonium 模型,这个模型也很容易可以扩展成multi-wing harmonium (MWH)。
Multi-Modal Distance Metric Learning
本节中,介绍如何使用 MWH 模型来学习多模态距离测量。给定数据点y=(x,z)有两种模态x,z。在DWH框架中,可以将y嵌入到公共潜在空间中,并得到其潜在表示t:
t=Ep(h∣x,z;Θ)[H]
显然t是一个关于Θ的函数,E表示数学期望。从语义上介绍,演出单元H可以看做是一组隐藏主题,而不同源的观察值反映的是来自不同专题的中心主题,并由共享主题生成。
给定一组标记为相似或不相似的数据对,在潜在空间中强制相似对彼此接近,而不同对彼此远离。文章简单的使用欧氏距离作为距离度量来度量潜在空间中的嵌入点。令S={y(i),y(j)}表示相似数据对,D={y(i),y(j)}表示不相似数据对。得到下面的优化问题:
Θmin(y(i),y(j))∈S∑∣∣t(i)−t(j)∣∣2 s.t. ∀(y(i),y(j))∈D,∣∣t(i)−t(j)∣∣2≥1
t(i)为y(i)的潜在空间,该函数的目标是在保持不相似点间在潜在空间的距离为1的情况下尽可能减小相似点间的距离,需要学习的参数是Θ。
用Y表示S或D中的所有数据示例,无监督DWH模型通过最大化数据观察Y的似然值来学习参数Θ。有监督DWH模型结合距离度量学习和最大似然学习通过联合最大函数似然值来学习Θ。具体的,将优化问题定义为:
Θmin∣Y∣1L(Y;Θ)+λ∣S∣1(y(i),y(j))∈S∑∣∣t(i)−t(j)∣∣2 s.t. ∀(y(i),y(j))∈D,∣∣t(i)−t(j)∣∣2≥1(6)
L(Y;Θ)是一个关于数据Y的负对数似然,λ为权衡参数。
优化
本节提出了公式(6)的一个有效解法,使用hinge loss来消除公式(6)中的约束,得到:
Θmin∣Y∣1L(Y;Θ)+λ1∣S∣1(y(i),y(j))∈S∑∣∣t(i)−t(j)∣∣2+λ2∣D∣1(y(i),y(j))∈D∑max(0,1−∣∣t(i)−t(j)∣∣2) (7)
\
公式(7)为公式(6)的松弛版本,当公式(6)中的约束满足要求时,公式(7)中的hinge loss为0。不满足要求是, hinge loss不为0,并最小化强制满足约束。
使用contrastive divergence方法来近似Θ关于∣Y∣1L(Y;Θ)(负对数似然)的梯度,总之,参数的次梯度与方程(7)中定义的目标函数可以计算如下:
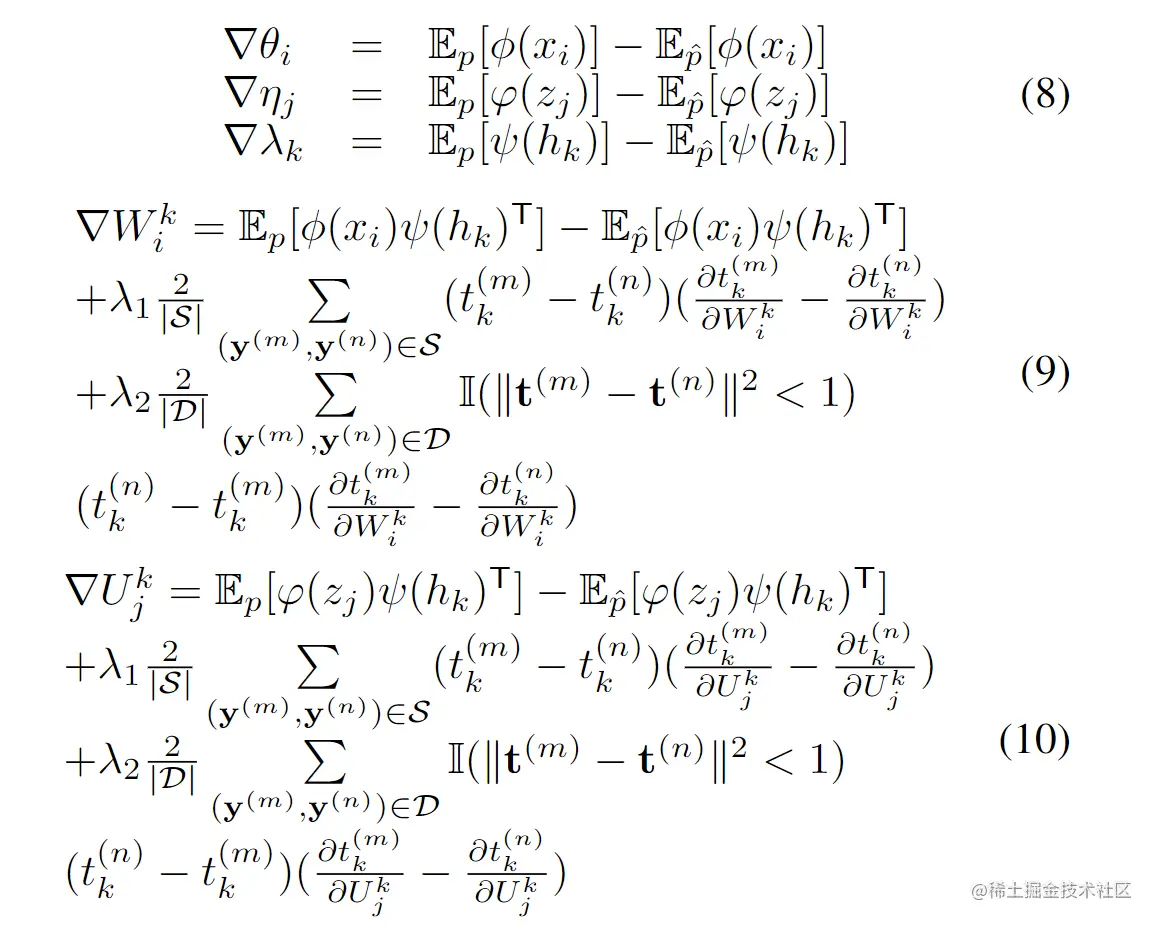
其中Ep[]表示真实分布的期望,Ep^[]表示经验分布的期望。精确计算Ep[]是非常困难的,因此通过从Ep^[]中运行一些Gibbs 采样来估算Ep[],采样可以按以下方式迭代完成:
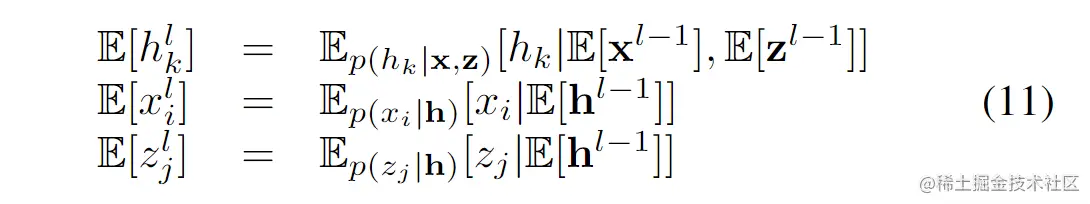
l为迭代的索引号。


