符号约定
别名
a:=b=f(x) : b的定义是f(x), a是b的别名
sigmoid
sigmoid简写为 σ, 其原始定义为: σ(x)=e0+exex
σ化简为: σ(x)=e−x+11
层
输入层为X,输入层为第0层
第0层X经过第1层权重W(1)的线性变换 ,得到 第1层线性变换输出O(1) ,O(1)经过第1层非线性函数sigmoid挤压输出第1层激活值A(1)
softmax
向量x,对向量x的第i个分量做softmax的定义:
softmax(x,xi)=k∑exkexi : 此结果是单个实数(标量)
向量x,对向量x做softmax定义为 对向量x的每个分量做softmax:
softmax(x)=[softmax(x,x1),softmax(x,x2),...,softmax(x,xN)]
cross_entropy
两个离散概率分布y、ŷ的交叉熵定义如下:
cross_entropy(y,ŷ) = y1log(y^1)+y2log(y^2)+...+ynlog(y^C)
两个离散分布的交叉熵 衡量 这两个分布的相似度,类似于 这两个分布的距离 ,
但是交叉熵很明显不满足距离三公理中的对称性的。
从交叉熵的式子看,其定义式应该是从以下原始定义式子简化而来,原始定义式如下:
ce(y,ŷ) = y^1y1y^2y2...y^nyC
对 ce(y,ŷ) 取对数,即可得到 cross_entropy(y,ŷ)
nn举例
训练集:X, Y
输入层: X:=A(0)
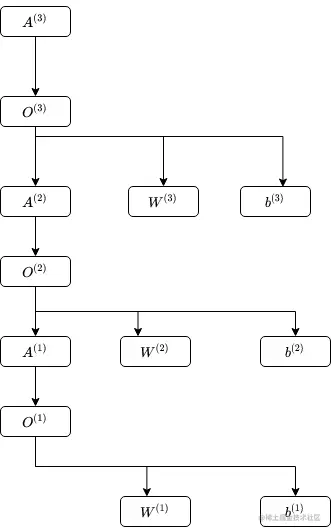
layer1: O(1)=XW(1)+b(1) , A(1)=σ(O(1))
layer2: O(2)=A(1)W(2)+b(2) , A(2)=σ(O(2))
layer3: O(3)=A(2)W(3)+b(3) , Y^:=A(3)=softmax(O(3))
损失: J:=Loss=cross_entropy(Y, Ŷ)
注意 损失J 是单个实数(是标量),而非向量
尺寸
训练集中样本数为B (隐含意思是一个批次大小为B)
假设 B=2, 即训练集中只有2个样本:
X = [x(1),x(2)],Y=[y(1),y(2)]
单个样本x(i)的维度为N:
x(i)=[x1(i),x2(i),...,xN(i)]
y为one-hot编码,类别个数为C,假设C=10,即共10个类别:
y(i)=[y1(i),y2(i),...,y10(i)]
偏导 ∂W∂J , ∂b∂J
J -> w1(1) , 此路径如下:
J -> A(3) -> O(3) -> A(2),W(3),b(3)
A(2) -> O(2) -> A(1),W(2),b(2)
A(1) -> O(1) -> W(1),b(1)