

Kinesis Stream to S3全面指南

你想把你的数据流到Amazon S3吗?你是否发现将你的数据加载到Amazon S3桶中是一个挑战?如果是,那么你就来对地方了!这篇文章将回答你所有的疑问和问题。这篇文章将回答你所有的疑问,并减轻你的压力,找到一个真正有效的解决方案。按照我们简单的分步指南,帮助你掌握无缝设置Kinesis流到S3的技巧,从你选择的来源实时引入你的数据。
它将帮助你在不影响效率的情况下,以一种无忧无虑的方式负责。本文旨在使数据流过程尽可能地顺利。
通过对内容的完整了解,你将能够无缝地将你的数据传输到Amazon S3,以便进行实时的富有成效的分析。它将进一步帮助你为你的组织建立一个定制的ETL管道。通过这篇文章,你将深入了解这些工具和技术,因此,它将帮助你进一步磨练你的技能。
目录
亚马逊S3简介

图片来源: dashsdk.com/
亚马逊S3是最流行、最强大的基于对象的存储服务之一,允许用户轻松地存储各种类型的大量数据,如博客、应用文件、代码、文档等。它是亚马逊简单存储服务的缩写,它支持确保数据的高可用性和99.999999999%的耐久性。
它拥有强大的集成支持,允许用户将其与众多ETL工具集成,以轻松地管理他们的数据需求。用户可以进一步利用亚马逊S3控制台或CLI,在他们的亚马逊S3桶中无缝添加、修改、查看和操作数据。它拥有对各种编程语言的支持,如Python、Java、Scala等,以及众多的API,从而使用户能够安全地管理、备份和发布他们的数据。
关于Amazon S3的进一步信息,你可以在这里查看官方网站。
亚马逊Kinesis简介

亚马逊Kinesis是一个由亚马逊提供的完全管理的服务,它允许用户处理来自不同来源的数据,并将其实时流向各个目的地。它支持将数据流转到以下存储目的地。
亚马逊Kinesis封装了以下一组实体,帮助实时流式数据。
- 数据生产者。 生产者负责生成数据并将其无缝传输到Amazon Kinesis。例如,移动应用程序、产生日志文件的系统、点击流等。
- 记录。 它代表了Amazon Kinesis Firehose交付系统从数据生产者那里收到的数据。
- 缓冲区大小和流。 这些由各种基于配置的设置组成,有助于提升性能和优化数据交付过程。
关于Amazon Kinesis的进一步信息,你可以在这里查看官方网站。
了解流数据
流数据是指一个应用程序或一个源实时产生的数据。这种数据的数量完全取决于帮助产生这种数据的数据源。因此,它的变化很大;例如,它可以高达每秒20000多条记录,也可以低至每秒一条记录。市场上有各种各样的工具,如Amazon Kinesis、Apache Kafka、Apache Spark等,有助于实时捕获和流式传输这些数据。
流媒体数据的一些例子如下。
- 由网络应用程序产生的网络点击/流。
- 应用程序产生的日志文件。
- 股票市场数据。
- 物联网设备数据(传感器、性能监视器等)。
用Hevo的无代码数据管道简化数据流
Hevo数据,一个无代码的数据管道,帮助你从100多个来源的数据流到Amazon S3,并让你在一个BI工具中可视化。Hevo是完全管理的,完全自动化的过程,不仅从你想要的来源加载数据,而且还丰富了数据,并将其转化为可分析的形式,而无需编写一行代码。它的容错架构确保以安全、一致的方式处理数据,实现零数据损失。
它提供了一个一致和可靠的解决方案来实时管理数据,并始终在你所期望的目的地拥有可供分析的数据。它允许你专注于关键的业务需求,并使用各种BI工具,如Power BI、Tableau等,进行有洞察力的分析。
看看是什么让Hevo如此神奇。
- 安全。Hevo有一个容错的架构,确保以安全、一致的方式处理数据,实现零数据丢失。
- 模式管理。H evo消除了繁琐的模式管理任务,自动检测传入数据的模式并将其映射到目标模式。
- **最少的学习。**Hevo,其简单和互动的用户界面,对新客户来说是非常简单的工作和执行操作。
- **Hevo是为扩展而建。**随着来源的数量和你的数据量的增长,Hevo可以横向扩展,每分钟处理数百万条记录,而且延迟很小。
- **增量数据加载:**Hevo允许实时传输已修改的数据。这确保了两端带宽的有效利用。
- **实时支持。**Hevo团队全天候通过聊天,电子邮件和支持电话向客户提供特殊支持。
- 实时监控。Hevo允许你监控数据流,并检查你的数据在某个特定时间点的位置。
前提条件
- 对Amazon S3的工作知识。
- 对Amazon Kinesis的工作知识。
- 一个Amazon S3账户。
设置Kinesis流到S3的步骤
亚马逊Kinesis允许用户利用其Firehose功能,从他们选择的数据生产者开始实时地将数据流到亚马逊S3。
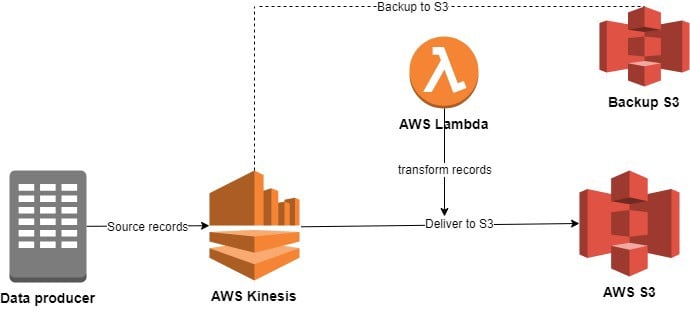
你可以通过以下步骤来设置Kinesis Stream to S3,开始将数据流转到Amazon S3桶。
第1步:登录到亚马逊Kinesis的AWS控制台
要开始设置Kinesis流到S3,你首先需要登录到AWS Kinesis的控制台。要做到这一点,请到AWS控制台的 官方网站,用你的凭证,如用户名和密码登录。
一旦你登录了,如果你是第一次使用AWS Kinesis,下面的页面将在你的屏幕上打开。点击 "开始 "选项,开始设置过程。
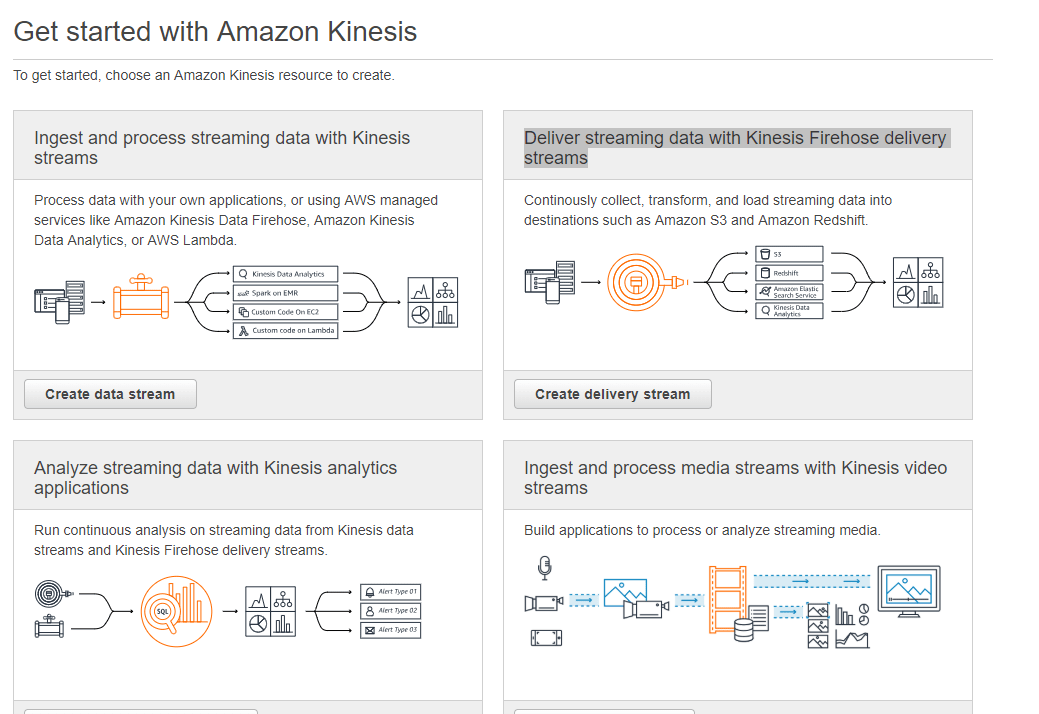
一旦你点击了它,你现在就能在屏幕上看到四个不同的选项来创建AWS Kinesis流,你需要点击并选择 "用Kinesis Firehose交付流数据 "选项。
第二步:配置交付流
有了所需的选项,你可以开始配置数据交付流,首先为它提供一个独特的名字,然后选择 "直接PUT或来源 "作为数据源选项。
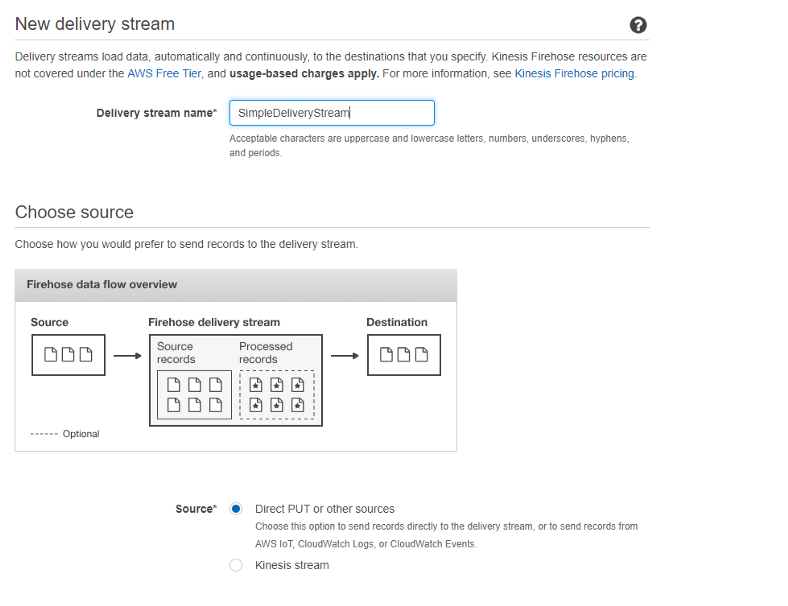
这就是你如何在AWS控制台为AWS Kinesis配置交付流。
第三步:使用Lambda函数转换记录
在配置了数据源和交付流之后,你现在需要转换传入的数据记录。要做到这一点,Amazon Kinesis允许用户利用其lambda函数将数据转化为他们所需的格式,然后将其交付给他们选择的目的地,如Amazon S3。
在转换记录的时候,确保它包含以下一组参数。
- RecordID: 它是AWS Kinesis在执行过程中传递给lambda函数的唯一标识符。
- 结果。 它代表了新转换的数据的状态。
- **数据。**它包含了转换后的数据。
要开始转化你的数据,你首先需要选择在转化源记录部分找到的 "已启用 "选项。
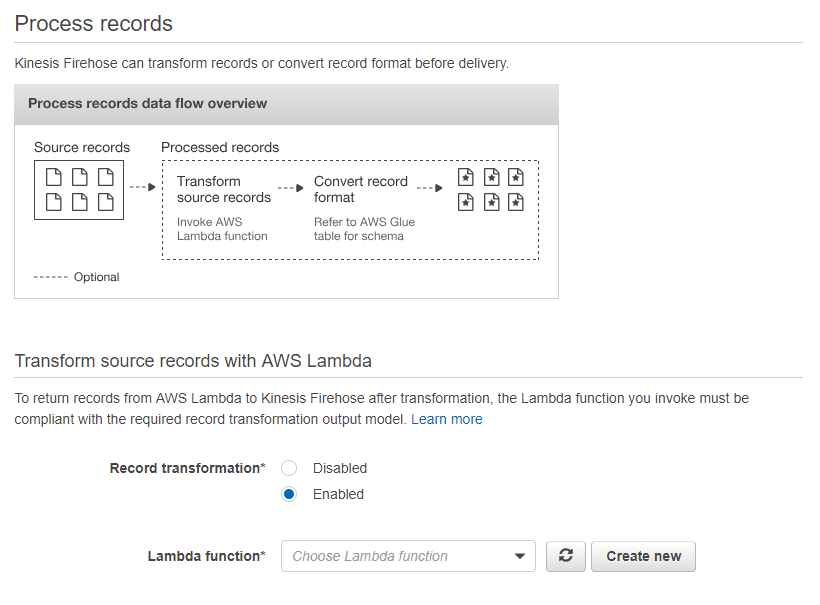
一旦你启用了它,你现在可以利用任何现有的lambda函数,存在于众多lambda蓝图的列表中,或者通过编写任何自定义lambda函数来利用它。在这里,你需要选择 "General Firehose Processing "作为你的lambda蓝图。
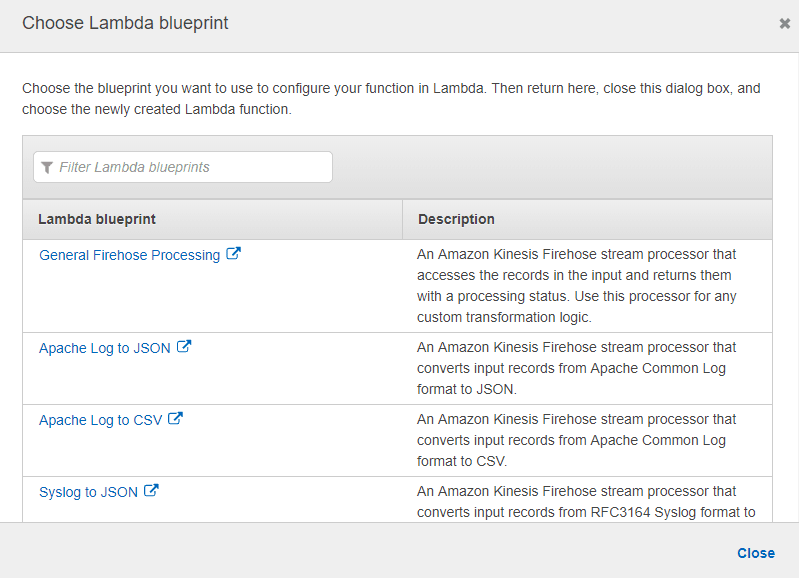
一旦你选择了它,你现在需要为你的lambda函数提供一个独特的名字,并选择IAM角色,这将有助于以必要的权限访问AWS S3和Firehose。
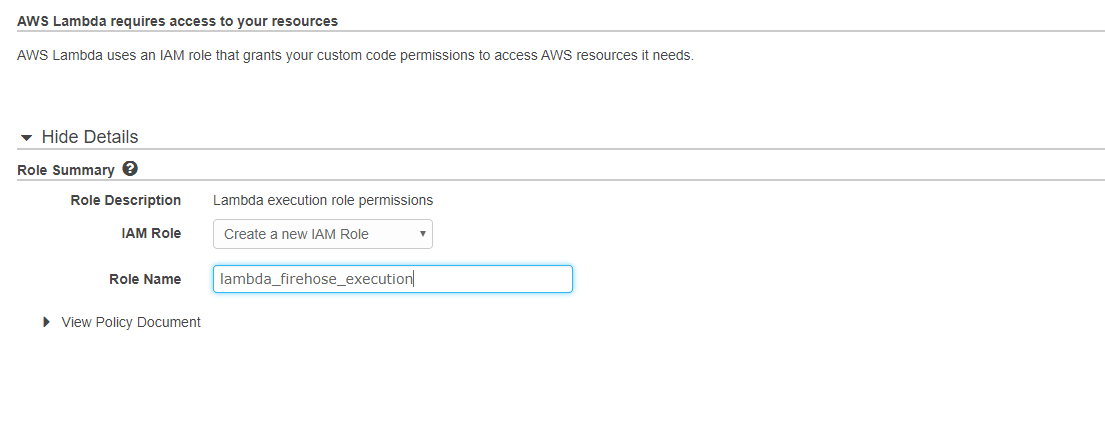
现在,点击查看策略选项按钮,点击编辑选项并在策略中添加以下几行代码,然后编辑AWS-region、AWS-account-id、stream-name,如下所示。
{
"Effect": "Allow",
"Action": [
"firehose:PutRecordBatch"
],
"Resource": [
"arn:aws:firehose:your-region:your-aws-account-id:deliverystream/your-stream-name"
]
}
现在你将能够看到以下格式的流数据。
{"TICKER_SYMBOL":"ABC","SECTOR":"AUTOMOBILE","CHANGE":-0.15,"PRICE":44.89}
你现在需要修改这段代码,执行一个简单的转换,这将有助于在流数据时忽略变化属性。要做到这一点,请复制以下几行代码并将其粘贴到lambda函数中。
use strict';
console.log('Loading function');
exports.handler = (event, context, callback) => {
/* Process the list of records and transform them */
const output = event.records.map((record) => {
console.log(record.recordId);
const payload =JSON.parse((Buffer.from(record.data, 'base64').toString()))
const resultPayLoad = {
ticker_symbol : payload.ticker_symbol,
sector : payload.sector,
price : payload.price,
};
return{
recordId: record.recordId,
result: 'Ok',
data: (Buffer.from(JSON.stringify(resultPayLoad))).toString('base64'),
};
});
console.log(`Processing completed. Successful records ${output.length}.`);
callback(null, { records: output });
};
一旦你做了必要的修改并保存,你现在就可以在交付流页面看到一个新的lambda函数。
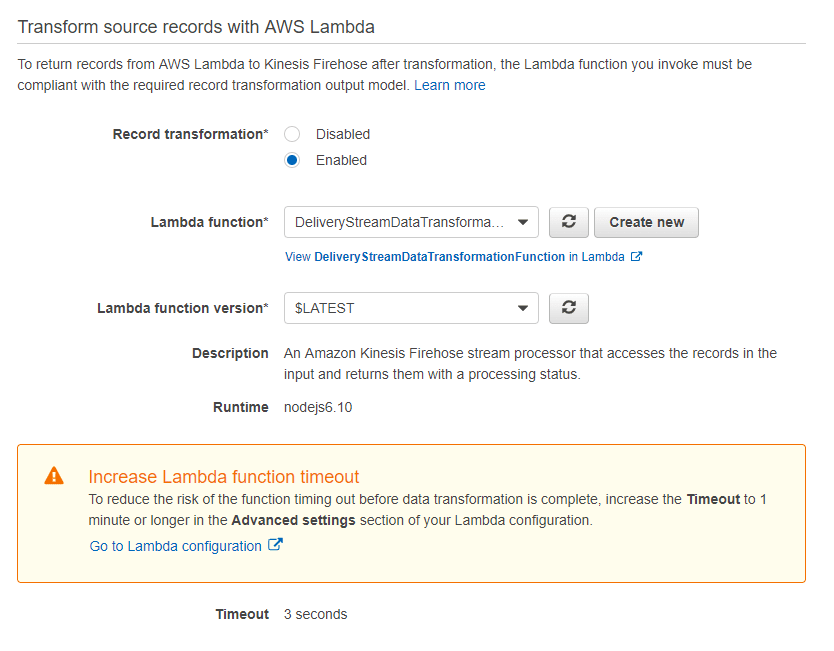
这就是你如何使用lambda函数转换你的记录,并进一步设置Kinesis流到S3。
第4步:配置亚马逊S3目标到启用Kinesis流到S3
有了lambda函数,你现在需要选择所需的目的地来保存你的数据记录,在Amazon S3、Redshift、Elasticsearch和Splunk中选择。这里你需要选择Amazon S3作为所需的目的地。

一旦你选择Amazon S3作为你的目的地,你现在需要提供你想要的Amazon S3桶的名称。如果你想为你的数据创建一个备份,你可以点击启用按钮并给出所需的路径。

现在选择了你的目的地,配置页面现在将在你的屏幕上打开,这将有助于你配置缓冲区大小、缓冲区间隔、加密、S3压缩和错误记录。在这里,你需要选择所有这些的默认值,然后选择一个IAM角色,允许AWS Kinesis访问你的Amazon S3桶。

随着你的交付流的建立,你现在可以用演示数据节点打开一个测试来测试这个流。
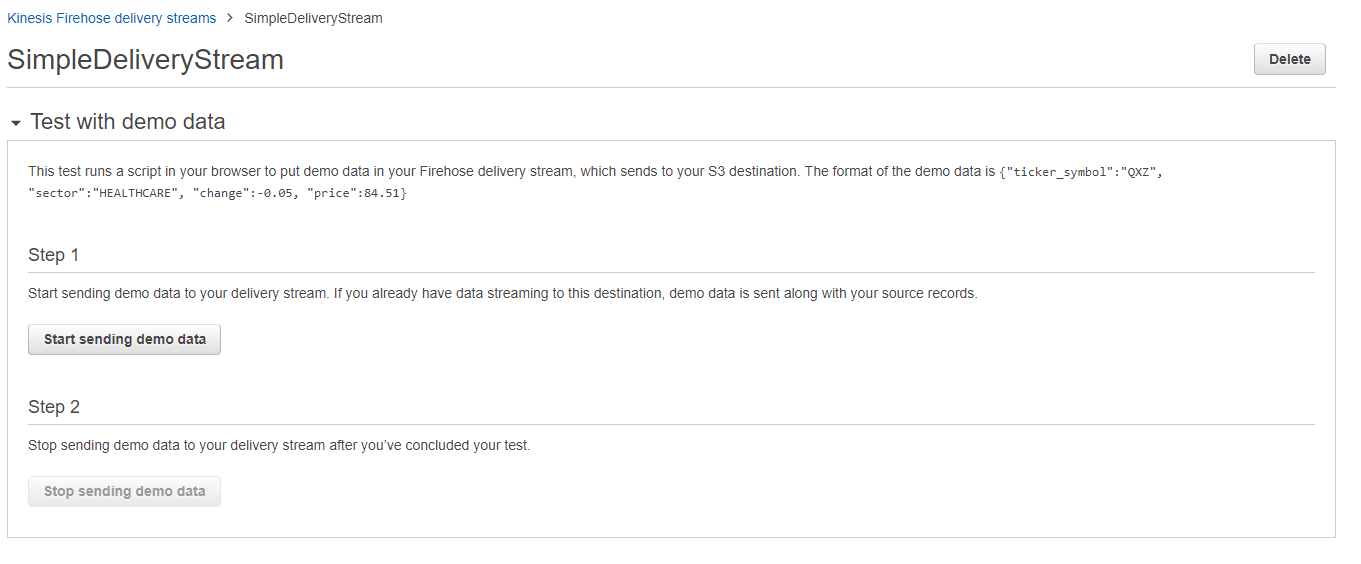
一旦你打开了数据节点,点击开始按钮,开始将数据传输到你的kinesis交付流。如果你想停止这个过程,你可以点击停止按钮。现在你可以通过在你的Amazon S3桶中打开一个文件并检查流式数据是否包含变化属性来验证数据流的过程。
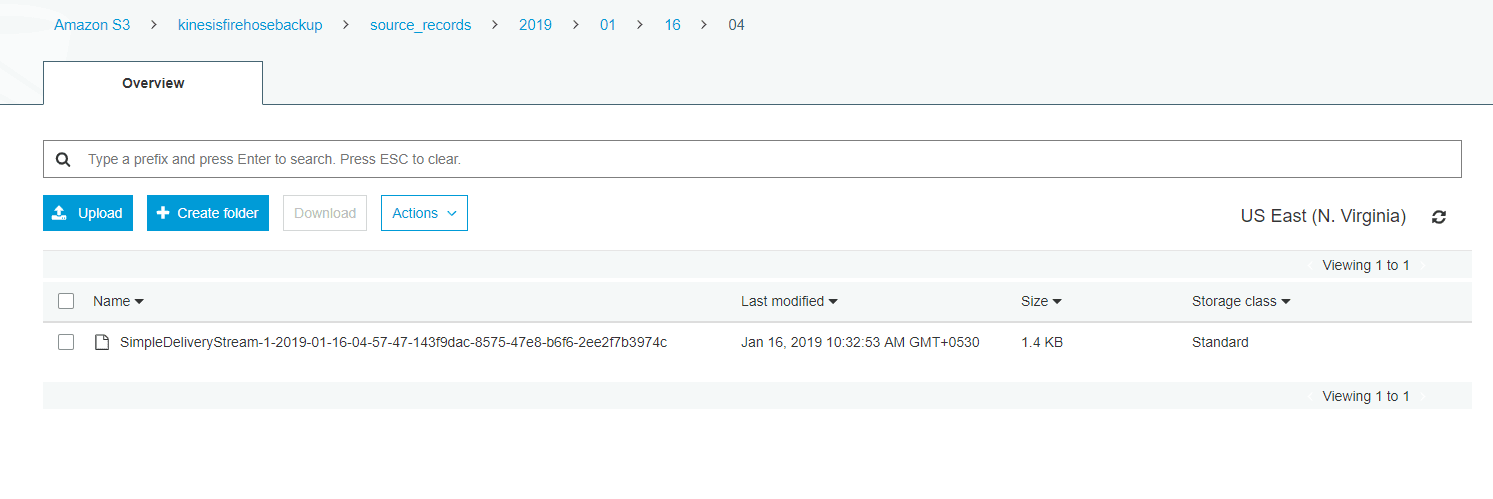
这就是你如何通过设置Kinesis Stream to S3来实时流化你的数据。
总结
这篇文章教你如何轻松地设置Kinesis流到S3。它对每一个步骤背后的概念进行了深入的了解,以帮助你理解并有效地实施它们。然而,这些方法可能具有挑战性,特别是对初学者来说,这就是Hevo拯救的地方。
