

引言
今年提倡原地过年,相信很多朋友都没有回家过年,像我就被迫留在深圳过年了,无聊之余只能去看看电影爬爬山。今天给大家带来一个打发无聊时光的案例,用Python爬取不羞涩网图片素材,并保存到本地。

准备工作
- 首先进入不羞涩网官网(www.buxiuse.com/),选“有颜”版块,可…
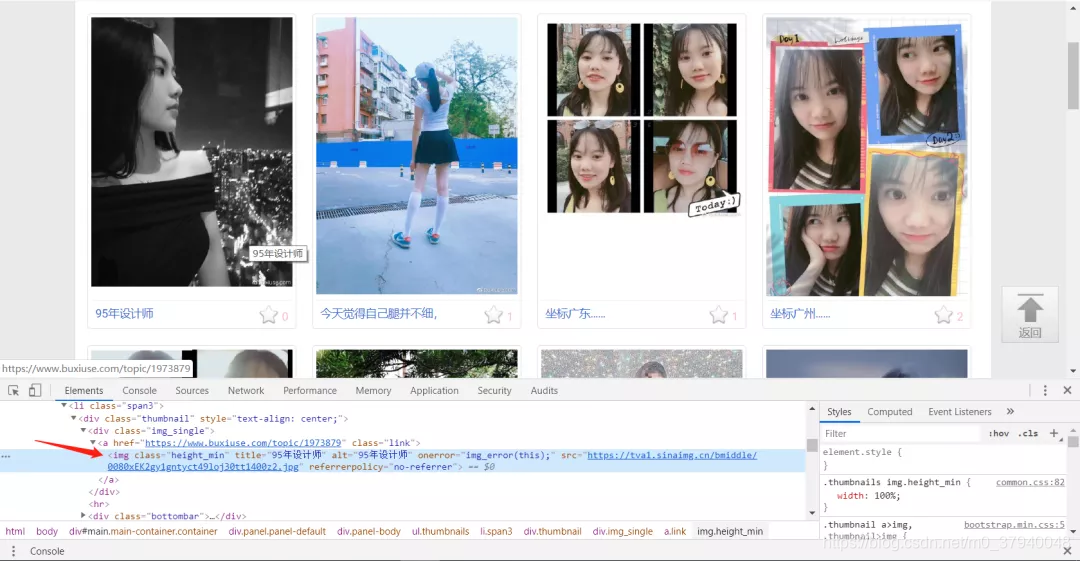
- 右键检查网页源代码,随意选中一张图片,可以看到,图片位于
标签下,并且是一一对应匹配标签。
- 点击第2页,可以看到网址栏的网址变成了(www.buxiuse.com/?cid=4&page…
代码实现
- 先导入要用到的库,定义主模块,调用main()函数。
import requests
import random
import time
import urllib.request
from bs4 import BeautifulSoup
if __name__ == '__main__':
main()
- 在main模块上方定义main函数,并设置请求头,用列表推导式生成要爬取的URL列表,我这里为了演示,就爬取前三页的图片了。
def main():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
url_list = ['https://www.buxiuse.com/?cid=4&page={}'.format(page) for page in range(1, 4)]
- 在函数中遍历URL列表,并用request.get方法获取响应内容,用BeautifulSoup解析网页,并获取所有的<img>标签,保存到srcs列表中。
i = 0
for url in url_list:
response = requests.get(url, headers=headers).text
# print(response)
soup = BeautifulSoup(response, 'lxml')
srcs = soup.find_all('img')
- 遍历srcs列表,获取其中的'src'属性和'alt'属性(分别储存了图片的链接和图片名称)。用urllib.request.urlretrieve方法下载图片到本地(或者用with open方法),设置随机停顿,防止被识别为爬虫禁用。用print打印程序执行过程,方便查看进度。
for img in srcs:
src = img.get('src')
name = img.get('alt')
urllib.request.urlretrieve(src, 'images/{}-img.jpg'.format(name))
# with open('images/{}-img.jpg'.format(name), 'wb') as f:
# f.write(requests.get(src, headers=headers).content)
time.sleep(random.random())
print('正在下载-{}.jpg'.format(name))
- 执行程序,如下图所示。

- 查看本地文件夹,大功告成。
 So,你学会了吗?
So,你学会了吗?

欢迎关注微信公众号“爬取你的深度神经网络”获取源代码和更多精彩文章。
