

前言:
百度文库现在的文档都是复制都不行,必须要vip才能够下载,得到你所要的文档。
但是是不是可以通过Python爬虫把文字爬取下来呢?
显然是可以的,通常有两条方案:
正文:
-
数据抓包,通过刷新 页面找到network中的数据包,简单直接;
-
selenium自动抓取(需要登录),绕过反爬,可能需要登录验证
其实各有利弊,比如方案一,我们知道一篇文章很长,所以需要拆分成为多个部分,多个部分对应多个url(储存不同的文字信息),如下图所示:
左边的一个json数据对应了一篇文章的部分信息(一篇文拆分成多个部分),其中一个json数据只存储了460个文字,更何况一篇文章有很多页,所以可能有好几个甚至十几个json数据包中的文字才能组成一篇文章。
如果使用方案一,我们可以把json数据对应的url放在一个列表中,然后遍历做数据解析即可;很明显是简单但是比较繁琐(在操作上),所以这里使用方案二,selenium自动抓取数据,只不过需要手动登录,因为在页面下滑的时候有一个登录的弹出窗口,如下图所示:
需要手动登录,然后点击加载更多的按钮进行数据提取,这个手动操作需要一定的时间,需要设置
time.sleep(10),方便手动操作,手动操作需要扫码登录,还需要点击加载更多的按钮,因为滑动的话有一个广告弹出,覆盖页面,无法点击。
我们的目的是做一个简单GUI界面,通过输入url(百度文库网站对应文章的链接),然后输出txt文件(因为文字是目标数据,具体保存文件格式可以因情替换),点击输出按钮触发事件,selenium操作浏览器抓取数据的动作。
一、搭建简单图形界面
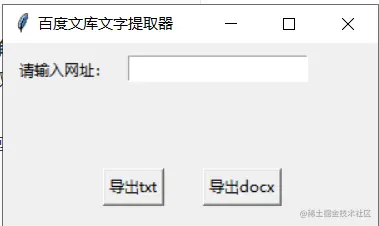
确定了思路之后简单设计一下GUI界面,如下图所示:
-
window:GUI的舞台,通过Tk()创建,然后设置大小即可;
-
label控件:提示信息,提示输入框中要输入的内容;
-
Entry控件:输入目标文章链接;
-
Button控件:绑定事件,抓取并保存数据
代码如下:
from tkinter import *
root = Tk()
root.title('百度文库文字提取器')
root.geometry('300x150') # 设置窗口大小,因为功能比较简单,这里简单设置一下界面
urlEntry = Entry()
text1 = Label(root, text='请输入网址:')
text1.place(x=10,y=10)
inputUrl = Entry(root)
inputUrl.place(x=100,y=10)
txtBtn = Button(root,text='导出txt')
docBtn = Button(root,text='导出docx')
txtBtn.bind("<Button-1>")
txtBtn.place(x=80,y=100)
docBtn.place(x=160,y=100)
root.mainloop()
运行结果如下:
 二、数据抓取
二、数据抓取
分析页面:我们发现文字都存放在p标签下面。
文章的文字被切分的很细,很多的p标签(HTML段落标签),存储大量不同的文字,使用xpath匹配目标文字:
//div[@class="ie-fix"]/p
然后我们定义一个空字符串cont = '',遍历p标签,做字符拼接,得到一个文字长字符串,有的p标签是空字符串需要剔除掉。
代码如下:
from selenium import webdriver
import time
driver = webdriver.Chrome()
url = 'xxx'
driver.get(url)
time.sleep(15)
cont = ''
items = driver.find_elements_by_xpath('//div[@class="ie-fix"]/p')
for i in items:
te = i.text
if te == '':
continue
cont += te
with open('bd.txt','w',encoding='utf-8') as f:
f.write(cont)
不过需要注意,如果文章比较短,一下子就展示完全了,如果较长,就会需要点击加载更多。
那么问题来了,自动点击会遇到登录弹出窗口,登录完成之后是用户,还会弹出广告窗口,按钮在下,无法点击,不如设置等待时间,进行手动点击,只是需要设置等待时间——tiem.sleep(15)。
三、合并
1、导包
from tkinter import *
from selenium import webdriver
import time
import os
2、定义创建桌面文件函数
def text_create(name, content): # name: 保存文件名 content: 写入文件内容
# 自动获取桌面路径
desktop_path = os.path.join(os.path.expanduser('~'), "Desktop/")
full_path = desktop_path + name + '.txt' # 也可以创建一个.doc的word文档
file = open(full_path, 'w')
file.write(content)
file.close()
3、封装数据抓取函数并在桌面创建文件
def getTxt():
global inputUrl,t
driver = webdriver.Chrome()
url = inputUrl.get()
driver.get(url)
time.sleep(20)
cont = ''
items = driver.find_elements_by_xpath('//div[@class="ie-fix"]/p')
for i in items:
te = i.text
if te == '':
continue
cont += te
text_create('ww.txt',cont)
这里我们把抓取数据的函数封装起来,因为这个函数是需要用户点击按钮触发事件才会调用这个函数,然后这个函数是不需要返回值的。
4、结合页面
root.title('百度文库文字提取器')
root.geometry('300x150')
urlEntry = Entry()
text1 = Label(root, text='请输入网址:')
text1.place(x=10,y=10)
inputUrl = Entry(root)
inputUrl.place(x=100,y=10)
txtBtn = Button(root,text='导出txt',command=getTxt) # 绑定数据提取函数
docBtn = Button(root,text='导出docx')
txtBtn.bind("<Button-1>") # 鼠标左键单击触发事件
# 布局
txtBtn.place(x=80,y=100)
docBtn.place(x=160,y=100)
root.mainloop()
5、运行过程和结果如下:
运行结果,桌面生成了一个文本文档。
由于selenium效率慢了点,花了一分钟才把文字抓取完,然后下面是txt文件截图:
这里为了方便查看我进行了换行处理,文字提取完毕。
注:由特殊到普遍规律,重要的是文字信息提取,通过不同的url显示信息,文字在页面的储存规律是一样的,所以具有普适性,但是由于页面不只是有登录弹出窗口还有广告窗口(在下滑过程中),所以加载更多选项还需要手动点击,需要时间time。sleep(15),比较稳妥
四、总结
对于百度文库这样的网站其实处于保护数据的目的,非VIP用户不得下载文档数据,这样的网站其实有很多,但是使用selenium可以避开反爬措施,只是需要手动登录以及动态点击,选择合适的方式获取数据,只是selenium抓取数据效率有点低。
最后 以上就是本文的所有内容了,欢迎点赞支持~大家需要完整的项目源码的可以私信我哟!
👇
祝大家在新的学期中,能够认认真真的学习,开开心心的玩,蟾宫折桂
