这是我参与2022首次更文挑战的第15天,活动详情查看:2022首次更文挑战
更多可以看这里:草履虫都能看懂的 白话解析《动手学深度学习》专栏(juejin.cn)
还在更新中…………
前面已经说过了循环神经网络、gru、Lstm。深度循环神经网络。这些要说的是双向RNN。
双向循环神经网络是在 Bidirectional Recurrent Neural Networks文章中提出的,关于各种结构的详细讨论可以看这篇文章:Framewise phoneme classification with bidirectional LSTM and other neural network architectures | Request PDF (researchgate.net)。
让我们来看一个例子:
I am _______ .
I am _______ happy.
I am _______ happy , because I lost my notebooks.
只看第一句我们可以写 “I am sad.”,当然也可以写“I am happy.”
第二句最后是个“happy”,所以我们前边可以写成“I am very happy.”也可以写成“I am not happy.”
最后一句后半句式“I lost my notebook”,讲道理,正常人丢东西了肯定是不高兴(除非小学生丢了寒假作业本),所以前边应该写不高兴,也就是:“I am not happy, because I lost my notebook.”
那在普通的句子完形填空中,我们怎么才能既做到填补空缺内容又能考虑到后边内容的影响呢?
之前我们讲过RNN,讲过GRU,讲过LSTM。但是他们的共同点是能将前边的内容传递到后边部分。
转换思路,是不是把他们倒过来训练就可以将后边内容的影响传播到前边了呢。
知道了前边怎传后边,知道了后边怎么传前边,那把二者结合起来,岂不就是将前后的影响都能考虑进来了。
现在以双向RNN为例子来看一下如何计算。
一张双向RNN的示例图如下:
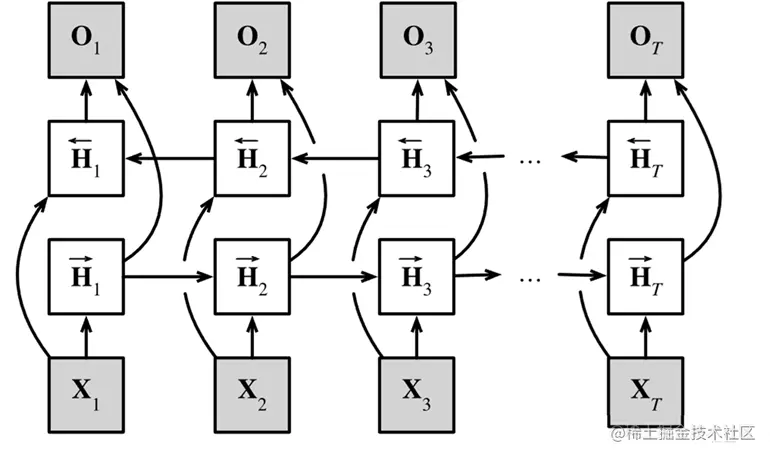
由以下几部分组成:
- 一个前向RNN隐层
- 一个方向RNN隐层
- 合并两个隐状态得到输出
计算公式如下:
HtHtHtOt=ϕ(XtWxh(f)+Ht−1Whh(f)+bh(f))=ϕ(XtWxh(b)+Ht+1Whh(b)+bh(b))=[Ht,Ht]=HtWho+bo
解析:
对于任意时间步 t,给定一个小批量的输入数据 Xt∈Rn×d其中样本数量为n,每个样本的长度为d。
我们分别令前向的隐状态为Ht∈Rn×h 反向隐状态为Ht∈Rn×h,其中 h 是隐藏单元的数目。
前向和反向隐藏状态的更新如下:
-
Ht=ϕ(XtWxh(f)+Ht−1Whh(f)+bh(f))
-
Ht=ϕ(XtWxh(b)+Ht+1Whh(b)+bh(b))
-
其中 ϕ 是隐状态使用的激活函数。
-
权重 Wxh(f)∈Rd×h,Whh(f)∈Rh×h,Wxh(b)∈Rd×h,Whh(b)∈Rh×h
-
偏置 bh(f)∈R1×h,bh(b)∈R1×h
接下来,将前向隐藏状态 Ht 和反向隐藏状态 Ht 做一个concat。这时候得到整个时间步的隐状态Ht∈Rn×2h。
-
Ht=[Ht,Ht]
-
有的书或者视频是横着拼接,有的是竖着,其实就是不用的计算方法,只要维度对得上就行了。
最后,输出层使用Ht计算得到的输出为 Ot∈Rn×o,o 是输出单元的数目:
-
Ot=HtWho+bo.
-
权重矩阵 Who∈R2h×o
-
偏置 bo∈R1×o
-
注意:正反两个方向可以拥有不同数量的隐藏单元。


