

简介
BERT 表示 Bidirectional Encoder Representations from Transformers,是 Google 于 2018 年发布的一种语言表示模型。
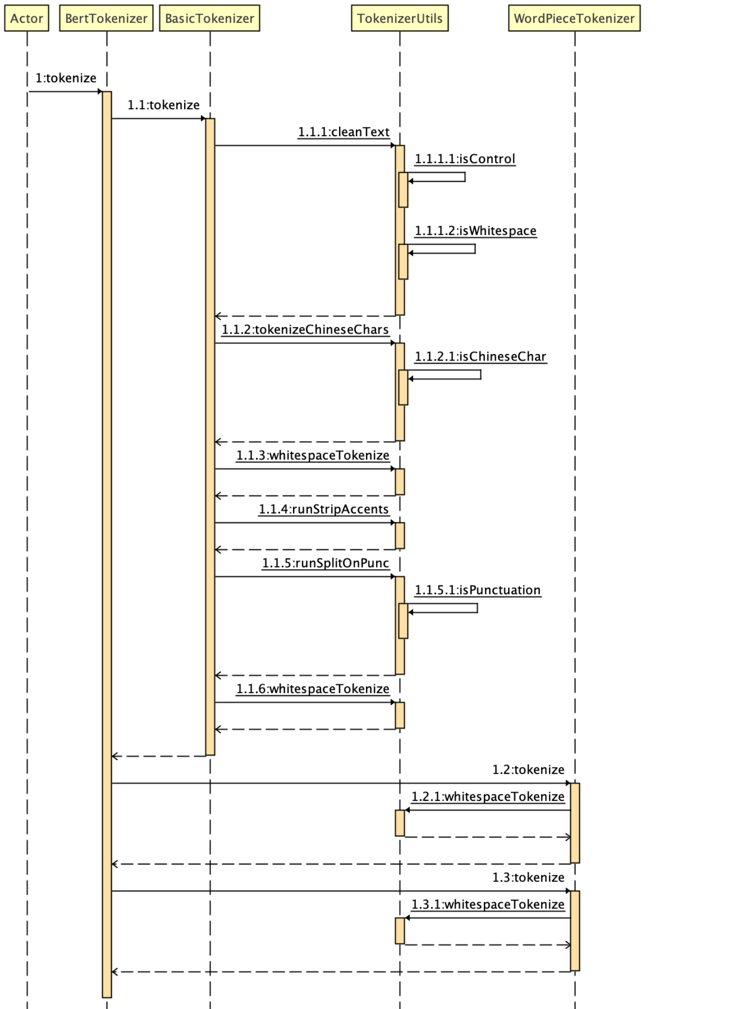
BERT 源码中 tokenization.py 就是预处理进行分词的程序,主要有两个分词器:BasicTokenizer 和 WordpieceTokenizer,另外一个 FullTokenizer 是这两个的结合:先进行 BasicTokenizer 得到一个分得比较粗的 token 列表,然后再对每个 token 进行一次 WordpieceTokenizer,得到最终的分词结果。
BasicTokenizer
BasicTokenizer(以下简称 BT)是一个初步的分词器。对于一个待分词字符串,流程大致就是转成 unicode -> 去除各种奇怪字符 -> 处理中文 -> 空格分词 -> 去除多余字符和标点分词 -> 再次空格分词,结束。
WordpieceTokenizer
WordpieceTokenizer(以下简称 WPT)是在 BT 结果的基础上进行再一次切分,得到子词(subword,以 ## 开头),词汇表就是在此时引入的。该类只有两个方法:一个初始化方法 __init__(self, vocab, unk_token="[UNK]", max_input_chars_per_word=200),一个分词方法 tokenize(self, text)。
tokenize(self, text):该方法就是主要的分词方法了,大致分词思路是 按照从左到右的顺序,将一个词拆分成多个子词,每个子词尽可能长。 按照源码中的说法,该方法称之为 greedy longest-match-first algorithm,贪婪最长优先匹配算法。
-
convert_to_unicode(text)
- 转成 unicode
- 如果是
str类型,直接返回 - 如果是
bytes类型, 用uft-8解码,若报错,采取ignore方案
- 如果是
- 转成 unicode
-
printable_text(text)
- 返回文本解码,用于打印和日志输出
- 如果是
str类型,直接返回 - 如果是
bytes类型, 用uft-8解码,若报错,采取ignore方案
- 如果是
- 返回文本解码,用于打印和日志输出
-
load_vocab(vocab_file)
- 导入
词表- 创建一个有序字典
- 打开文件,按行读取
- 如果读到空则跳出循环
- 去除空格,并将 数据 保存到有序字典。格式:vocab[token] = index,下表是词,值是排序号
- 导入
-
convert_by_vocab(vocab, items)
- 将
items转成词表- 定义output数组
- 遍历items -> item,output.append(vocab[item])
- return output
- 将
-
convert_tokens_to_ids(vocab, tokens)
- 将
tokens转成ids - return convert_by_vocab(vocab, tokens)
- 将
-
convert_ids_to_tokens(inv_vocab, ids)
- 将
ids转成tokens - return convert_by_vocab(inv_vocab, ids)
- 将
-
whitespace_tokenize(text)
- 返回去除前后空格的文本
- 如果text去除空格后为空,返回空数组
- 否则返回 tokens = text.split()
- 返回去除前后空格的文本
class FullTokenizer(object)
返回 端到端 的tokeniziation(标识化)
-
init(self, vocab_file, do_lower_case=True)
-
vocab_file:词表文件
-
do_lower_case:输入是否小写
- 词表 self.vocab
- 源词表 self.inv_vocab = {v: k for k, v in self.vocab.items()}
- 基础分词器 self.basic_tokenizer
- 词块分词器 self.wordpiece_tokenizer
-
-
tokenize(self, text):
- 一层循环 : for token in self.basic_tokenizer.tokenize(text):
- 二层循环: for sub_token in self.wordpiece_tokenizer.tokenize(token):
-
convert_tokens_to_ids(self, tokens): return convert_by_vocab(self.vocab, tokens)
-
convert_ids_to_tokens(self, ids): return convert_by_vocab(self.inv_vocab, ids)
BasicTokenizer
按空格切分,返回单个词的 tokenization
-
init(self, do_lower_case=True)
- self.do_lower_case = do_lower_case
-
tokenize(self, text)
- 标记一段文本
- text 转成 unicode
- text 调用 self._clean_text() 函数,清理文本中
无效字符和空格 - text 调用 self._tokenize_chinese_chars(),在
中文字符前后添加空格 - 将text
去除前后空格后的文本 赋值给变量orig_tokens - 定义
split_tokens数组 - 遍历
orig_tokens- 如果初始化时,设置了小写,则将文本转成小写
- 调用 self._run_strip_accents() 函数,去除 音标,如:ê-》转换为e和组合字符^
- 在
split_tokens列表尾端追加self._run_split_on_punc(token)
- 标记一段文本
-
_run_strip_accents(self, text):
- 格式化文本,去除 音标,如:ê-》转换为e和组合字符^
-
调用 unicodedata.normalize() 为整个字符串实现 Unicode 规范化算法。D 是一个规范化: D 将字符分解为组件,因此ê转换为e和组合字符^。
-
遍历格式化后文本
- 使用unicodedata.category(char),如果为 "Mn",continue
[Mn] Mark, Nonspacing
-
- 格式化文本,去除 音标,如:ê-》转换为e和组合字符^
-
_run_split_on_punc(self, text)
- 根据标点符号切分文本
- 将文本转为
List:chars = list(text) - start_new_word = True
- 遍历 List(text)
- 判断是否为标点字符
if _is_punctuation(char): output.append([char]) start_new_word = True else: if start_new_word: output.append([]) start_new_word = False output[-1].append(char)
- 将文本转为
- 根据标点符号切分文本
-
_clean_text(self, text):
- 清理文本中无效字符和空格
- 创建 output 数组: output.append(" ")
- 遍历
text的字符- 通过函数 ord()-》返回表示指定字符的 unicode 代码的数字
- 如果
unicode 为 0OR0xfffd(空字符串)OR_is_control(char),continue - 如果 _is_whitespace(char) , output数组添加空字符串:output.append(" ");否则output添加该字符:output.append(char)
将output数组转成字符串后返回:return "".join(output)
- 清理文本中无效字符和空格
_tokenize_chinese_chars(self, text):
- 在中文字符 前后添加 空格
output = []
for char in text:
cp = ord(char)
if self._is_chinese_char(cp):
output.append(" ")
output.append(char)
output.append(" ")
else:
output.append(char)
return "".join(output)
_is_chinese_char(self, cp):
- 通过
ord 函数的unicode 找出中文
if ((cp >= 0x4E00 and cp <= 0x9FFF) or #
(cp >= 0x3400 and cp <= 0x4DBF) or #
(cp >= 0x20000 and cp <= 0x2A6DF) or #
(cp >= 0x2A700 and cp <= 0x2B73F) or #
(cp >= 0x2B740 and cp <= 0x2B81F) or #
(cp >= 0x2B820 and cp <= 0x2CEAF) or
(cp >= 0xF900 and cp <= 0xFAFF) or #
(cp >= 0x2F800 and cp <= 0x2FA1F)): #
return True
return False
-
_is_control(char)
- 检查' chars '是否为控制字符
- unicodedata.category():把一个字符返回它在UNICODE里分类的类型。
- Cc Other, Control
- Cf Other, Format
- unicodedata.category():把一个字符返回它在UNICODE里分类的类型。
if char == "\t" or char == "\n" or char == "\r": return False cat = unicodedata.category(char) if cat in ("Cc", "Cf"): return True return False - 检查' chars '是否为控制字符
-
_is_whitespace(char)
- 检查' chars '是否为空格符
- unicodedata.category():把一个字符返回它在UNICODE里分类的类型。
- Zs Separator, Space
- unicodedata.category():把一个字符返回它在UNICODE里分类的类型。
if char == " " or char == "\t" or char == "\n" or char == "\r": return True cat = unicodedata.category(char) if cat == "Zs": return True return False - 检查' chars '是否为空格符
-
_is_punctuation(char)
- 检查
char是否为标点字符
if ((cp >= 33 and cp <= 47) or (cp >= 58 and cp <= 64) or (cp >= 91 and cp <= 96) or (cp >= 123 and cp <= 126)): return True cat = unicodedata.category(char) if cat.startswith("P"): return True return False - 检查
