

我们都曾经是垃圾邮件的收件人。垃圾邮件,或称垃圾邮件,是一种在同一时间发送给大量用户的电子邮件,经常包含神秘的信息、诈骗,或最危险的钓鱼内容。
虽然垃圾邮件有时是由人类手动发送的,但大多数情况下,它们是使用机器人发送的。大多数流行的电子邮件平台,如Gmail和微软Outlook,通过筛选可识别的短语和模式自动过滤垃圾邮件。一些常见的垃圾邮件包括虚假广告、连锁邮件和冒名顶替的企图。虽然这些内置的垃圾邮件检测器通常相当有效,但有时,一封伪装得特别好的垃圾邮件可能会从缝隙中漏掉,落入你的收件箱,而不是你的垃圾邮件文件夹。
点击垃圾邮件可能是危险的,会使你的电脑和个人信息暴露在不同类型的恶意软件面前。因此,实施额外的安全措施来保护你的设备是很重要的,特别是当它处理敏感信息如用户数据时。
在本教程中,我们将使用Python构建一个电子邮件垃圾邮件检测器。然后,我们将使用机器学习来训练我们的垃圾邮件检测器,以识别并将电子邮件分类为垃圾邮件和非垃圾邮件。让我们开始吧!
前提条件
首先,我们要导入必要的依赖项。Pandas是一个主要由数据科学家用于数据清理和分析的库。
Scikit-learn,也叫Sklearn,是一个强大的Python机器学习库。它为机器学习和统计建模提供了一系列高效的工具,包括分类、回归、聚类和通过一致的界面进行降维。
运行下面的命令来导入必要的依赖项。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn import svm
开始使用
要开始使用,首先,运行下面的代码。
spam = pd.read_csv('spam.csv')
在上面的代码中,我们创建了一个spam.csv 文件,我们将把它变成一个数据框架,并保存到我们的文件夹spam。数据框架是一种结构,它将数据以表格的方式排列成行和列,就像下面的图片中看到的那样。
继续从GitHub下载样本.csv文件。它模仿了一个典型的电子邮件收件箱的布局,包括5000多个例子,我们将用它来训练我们的模型。它应该看起来像下面的图片。

Pythontrain_test_split()
我们将使用训练-测试分割方法来训练我们的电子邮件垃圾邮件检测器,以识别和分类垃圾邮件。训练-测试分割是一种评估机器学习算法性能的技术。我们可以将其用于任何监督下的学习算法的分类或回归。
该程序涉及采取一个数据集并将其分为两个独立的数据集。第一个数据集被用来拟合模型,被称为训练数据集。对于第二个数据集,即测试数据集,我们向模型提供输入元素。最后,我们进行预测,将其与实际输出进行比较。
- 训练数据集:用于拟合机器学习模型
- 测试数据集:用于评估机器学习模型的拟合程度
在实践中,我们会在已知输入和输出的可用数据上拟合模型。然后,我们会根据我们没有预期输出或目标值的新例子来进行预测。我们将从我们的样本.csv 文件中获取数据,该文件包含预先分类为垃圾邮件和非垃圾邮件的例子,分别使用标签spam 和ham 。
为了将数据分成两个数据集,我们将使用scikit-learn的train_test_split() 方法。在我们的例子中,测试数据集将是加载数据的33%。
假设我们在加载的数据集中有100条记录。如果我们指定测试数据集为30%,我们将把70条记录拆开用于训练,并将剩余的30条记录用于测试。
运行下面的命令。
z = spam['EmailText']
y = spam["Label"]
z_train, z_test,y_train, y_test = train_test_split(z,y,test_size = 0.2)
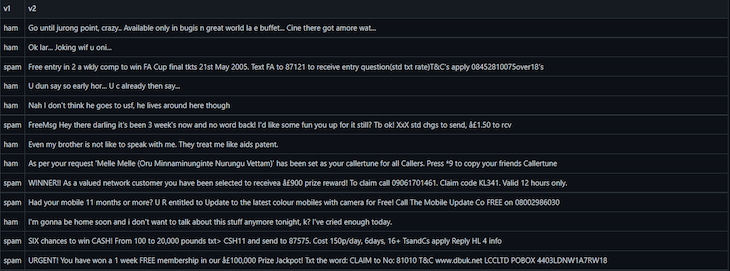
z = spam['EmailText'] 将垃圾邮件中的列EmailText 分配给z 。它包含了我们将通过模型运行的数据。y = spam["Label"] ,将垃圾邮件中的Label 列分配给y ,告诉模型要修正答案。你可以看到下面的原始数据集的截图。
函数z_train, z_test,y_train, y_test = train_test_split(z,y,test_size = 0.2) 将列z 和y 分成z_train 用于训练输入,y_train 用于训练标签,z_test 用于测试输入,y_test 用于测试标签。
test_size=0.2 将测试集设置为z 和y 的 20% 。你可以在下面的截图中看到一个例子,其中ham 标签表示非垃圾邮件,而spam 代表已知的垃圾邮件。
提取特征
接下来,我们将运行下面的代码。
cv = CountVectorizer()
features = cv.fit_transform(z_train)
在cv= CountVectorizer() ,CountVectorizer() ,在一个称为标记化的过程中,随机给每个词分配一个数字。然后,它计算单词的出现次数并将其保存到cv 。在这一点上,我们只给cv 分配了一个方法。
features = cv.fit_transform(z_train) 为每个词随机分配一个数字。它计算每个词的出现次数,然后将其保存到cv. 在下面的图片中,0 代表电子邮件的索引。中间一列的数字序列代表我们的函数所识别的一个词,右边的数字表示该词被计算的次数。
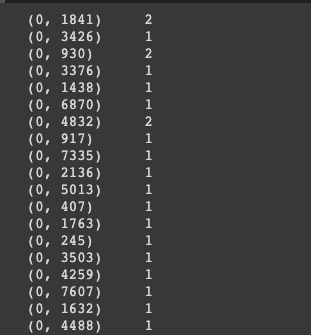
例如,在上面的图片中,对应于1841 的单词在编号为0 的邮件中使用了两次。
现在,我们的机器学习模型将能够根据垃圾邮件中常见的某些词的出现次数来预测垃圾邮件。
建立模型
SVM,支持向量机算法,是一种用于分类和回归的线性模型。SVM的想法很简单,该算法创建一条线,或一个超平面,将数据分成不同的类别。SVM可以解决线性和非线性问题。
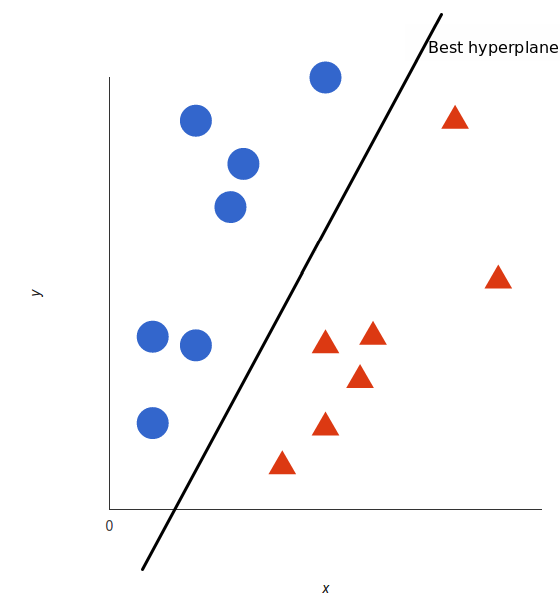
让我们用下面的代码创建一个SVM模型。
model = svm.SVC()
model.fit(features,y_train)
model = svm.SVC() 将svm.SVC() 分配给模型。在model.fit(features,y_train) 函数中,model.fit 用features 和y_train 训练模型。然后,它对照y_train 标签检查预测结果,并调整其参数,直到达到尽可能高的准确性。
测试我们的电子邮件垃圾邮件检测器
现在,为了确保准确性,让我们测试一下我们的应用程序。运行下面的代码。
features_test = cv.transform(z_test)
print("Accuracy: {}".format(model.score(features_test,y_test)))
features_test = cv.transform(z_test) 函数从z_test 进行预测,这些预测将经过计数矢量化。它将结果保存到features_test 文件中。
在print(model.score(features_test,y_test)) 函数中,mode.score() 将features_test 的预测与y_test 中的实际标签进行评分。

在上面的图片中,你会看到我们能够以97%的准确率对垃圾邮件进行分类。
这个项目的完整脚本在下面。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn import svm
spam = pd.read_csv('C:\\Users\\nethm\\Downloads\\spam.csv')
z = spam['EmailText']
y = spam["Label"]
z_train, z_test,y_train, y_test = train_test_split(z,y,test_size = 0.2)
cv = CountVectorizer()
features = cv.fit_transform(z_train)
model = svm.SVC()
model.fit(features,y_train)
features_test = cv.transform(z_test)
print(model.score(features_test,y_test))
总结
在本教程中,我们学习了如何建立和运行我们的模型,将我们的预测与实际输出进行比较。最后,我们用计数矢量法测试了我们的模型。
我们只是触及了机器学习为我们的垃圾邮件检测器所能实现的表面。我们还可以增加一些修改,如自动生成CSV文件或提供语音助手。
希望这篇文章能让你对Python中一些流行的机器学习算法有更深入的了解。
