DynGEM: Deep Embedding Method for Dynamic Graphs
1、问题描述
问题:以前的动态图方法直接把单个图嵌入方法直接用于每个snapshot,这样的方法缺少稳定性和灵活性,不适用于节点集快速变化的情况。
解决:使用深度自编码器,并配合初始化和网络调整策略,使训练更加稳定和灵活。
2、DyGEM
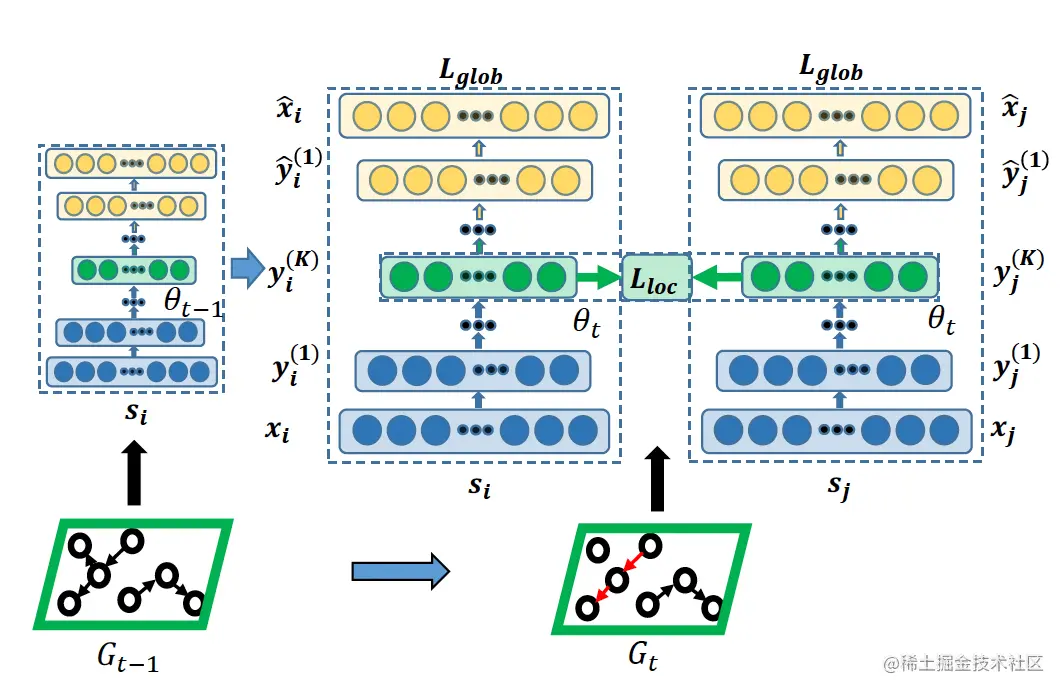

2.0 自编码器框架
带权重的邻接矩阵S的一行si表示了此节点i和邻居的连接信息。因此自编码器先对此信息xi=si进行编码,得到嵌入表示yi;然后对嵌入表示yi进行解码,得到重构后的邻居连接信息xi。
2.1 根据t-1时刻的模型初始化t时刻的模型
根据t-1时刻的模型初始化t时刻的模型的参数(包括编码参数和解码参数),
Wt(k)=Wt−1(k),Wt(k)=Wt−1(k),k=1,2,...l
| 问题 | 解释 |
|---|
| 为什么要用t-1时刻的参数初始化t时刻? | 1)有利于模型在两个相邻时刻的平滑过渡2)加快了t时刻模型的稳定性和收敛速度 |
2.2 模型PropSize
如果t时刻有新增节点,则需要调整网络的隐藏层维度。
我们希望,网络中相邻两层之间的隐藏层维数满足以下的条件(以编码器为例,解码器刚好反过来,整体上呈现出一个漏斗形网络结构):
dim(l(k))≥ρ×dim(l(k+1))
其中ρ是一个(0, 1)之间的超参数,根据这个规则,先初始化模型参数,然后扩充每一层的维数(必要时可以增加一层)。
| 问题 | 解释 |
|---|
| 为什么要动态调整隐藏层的维数? | 1)因为输入为xi=si,假设原来si∈Rd,那么新增1个节点后,si∈Rd+1,输入层的维度增加了。2)隐藏层维数变宽,有利于模型的性能 |
2.3 前向传播并进行重构
根据自编码器进行前向传播。
编码器:
yt(0)=xi(t)yt(k)=Wt(k−1)yt(k−1)+bt(k−1)yt(K)
解码器:
yt(K)=yt(K)yt(k−1)=Wt(k)yt(k)+bt(k)xi(t)=yt(0)
2.4 无监督训练/loss
无监督loss包含了一阶近似性,二阶近似性和正则化项,
Loss=i∑j∑sij∣∣yi−yj∣∣2+i∑∣∣(xi−xi)⊙bi∣∣2+v1∣∣W∣∣1+v2∣∣W∣∣2bij=1ifsij=0elsebij>1
其中b为惩罚项,原来没有边但是重构了的惩罚 < 原来有边但是没重构的惩罚。
3、实验
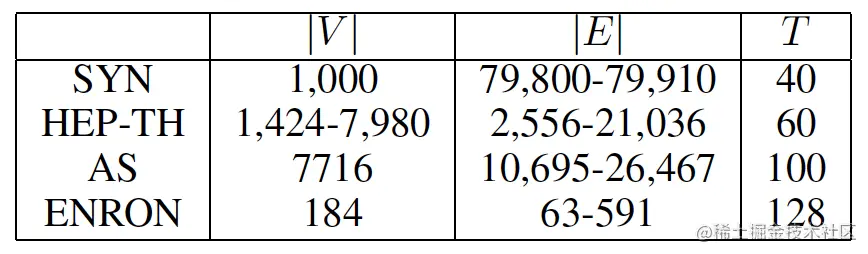
3.1 数据集
离散型动态图数据集:
3.2 baseline
- SDNE
- SDNE/GF
- GF( Graph Factorization)
- DynGEM
3.3 评价指标
图重构:
- MAP(mean average precision)
动态链接预测:
3.4 实验结果
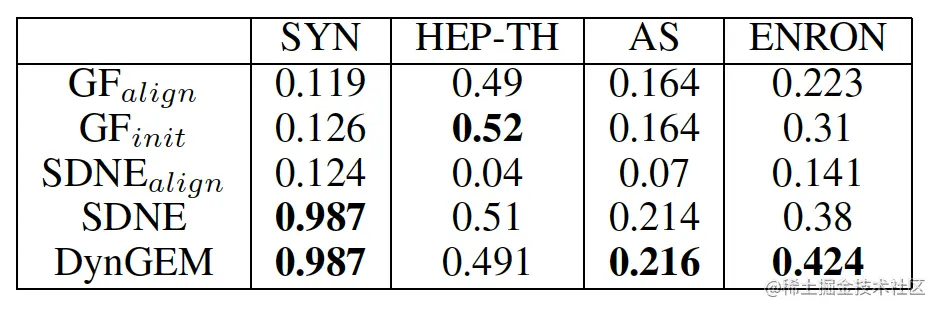
和baseline的比较:
图重构:
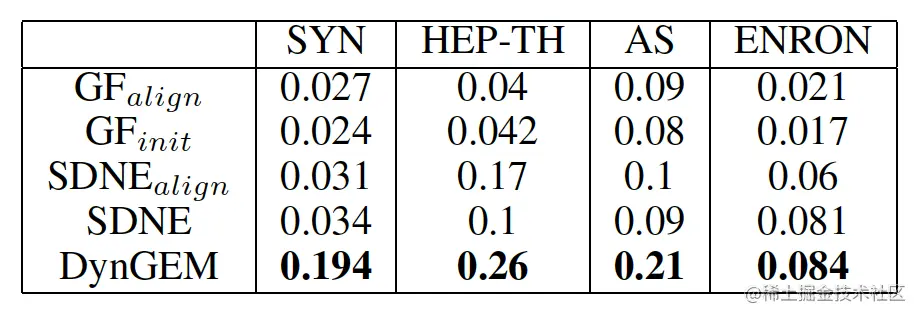
链接预测:
稳定性分析:
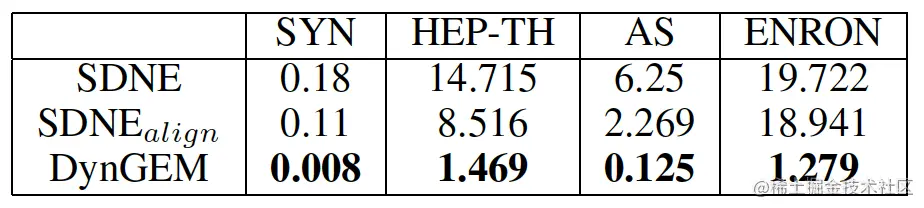
Srel(F;t)=∣∣Ft(Vt)∣∣F∣∣Ft+1(Vt)−Ft(Vt)∣∣f/∣∣St(Vt)∣∣F∣∣St+1(Vt)−St(Vt)∣∣fKS(F)=maxt,t′∣Srel(F;t)−Srel(F;t′)∣
DyGEM稳定性常数最低,稳定性最好。


