《INDUCTIVE REPRESENTATION LEARNING ON TEMPORAL GRAPHS》
1、问题和任务描述
问题:离散型DGNN的方法将全图划分为n个snapshot,这样可能会损失一些时间演化信息(信息丢失);此外,离散型的DGNN无法进行inductive learning。
任务:不切分子图,使用基于time encoding的连续DGNN方法进行动态图的链接预测任务。
2、TGAT
2.1 time encoding
时间函数用来编码src节点和dst节点之间的相对时间差:
ϕ(t,ti)=(cos(w1(t−ti)+b1),cos(w2(t−ti)+b2),...,cos(wd(t−ti)+bd))∈Rd
| 问题 | 解释 |
|---|
| 为什么可以用相对时间差来编码? | 1)直觉上来说,相对时间要比绝对时间更重要;2)时间差具有平移不变性,便于发现周期性的规律3)本质上是要学习核函数K(t1,t2)=<Φ(t1),Φ(t2)>=ϕ(t1−t2) |
| 为什么要使用cos函数来进行编码? | cos函数具有周期性,可以反映时间差的周期性变化;不同w代表不同的频率,d维特征可以提取不同的频率 |
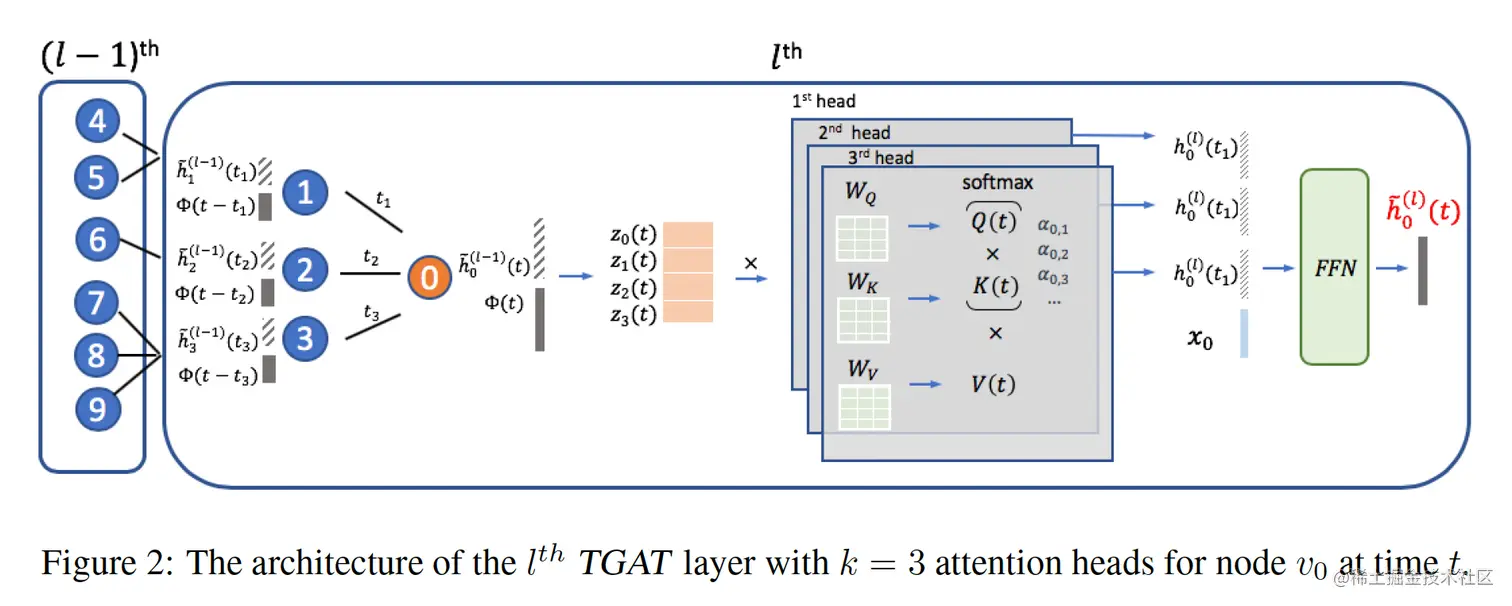
2.2 TGAT layer
已知src节点和dst节点的timestamp,可以写成以下self-attention的形式:(包含节点特征,边特征和时间编码)
(把position encoding换成了time encoding)
Z(t)=[h0(t)∣∣e0,0∣∣ϕ(0),h1(t)∣∣e0,1∣∣ϕ(t−t1),...,hn(t)∣∣e0,n∣∣ϕ(t−tn)]
0代表src,1..n代表dst,
Q=(h0(t)∣∣e0,0∣∣ϕ(0))∗WqK=(h1(t1)∣∣e0,1∣∣ϕ(t−t1),...,hn(tn)∣∣e0,n∣∣ϕ(t−tn))∗WkV=(h1(t1)∣∣e0,1∣∣ϕ(t−t1),...,hn(tn)∣∣e0,n∣∣ϕ(t−tn))∗Wv
计算attention和output,
h0(t)=softmax(dkQKT)V
然后和原始src的特征拼接过一个FFN,得到l+1层的输出, (多头机制)
h0(l+1)(t)=FFN(h0head−1(t)∣∣h0head−2(t)∣∣...∣∣h0head−k(t)∣∣x0)
| 问题 | 解释 |
|---|
| 为什么不用GAT+Time encoding而是self-attention? | 实验来说,self-attention效果更好 |
2.3 loss
链接预测任务,基于负采样的二元交叉熵损失:
Loss=j∈N(i)∑−log(−σ(FFN(hi(tij)∣∣hj(tij)))−wnk∈Pn(i)∑log(σ(FFN(hi(tij)∣∣hk(tij)))
3、实验
TGAT实验记录
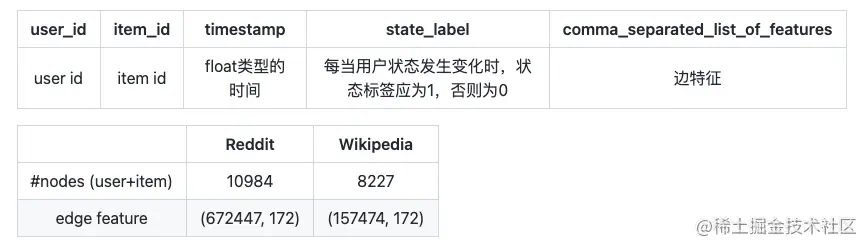
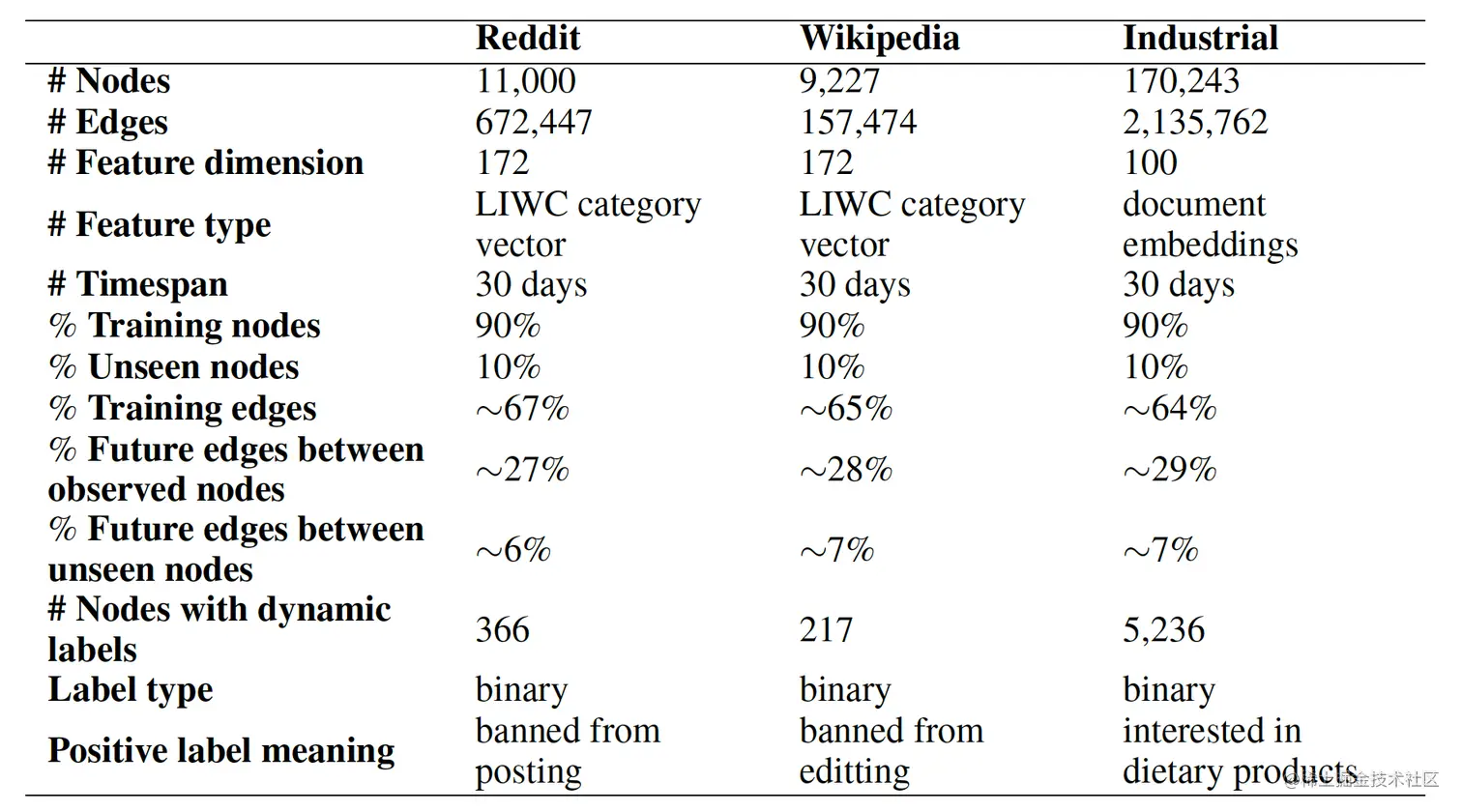
3.1 数据集
用的JODIE的两个开源数据集和一个沃尔玛的私有工业数据集。
3.2 baseline
不包含time encoding:
包含time encoding:
3.3 评价指标
动态链接预测任务:
- AP:average precision
- Accuracy:转换为二分类任务的准确率
动态节点分类任务:
3.4 实验结果
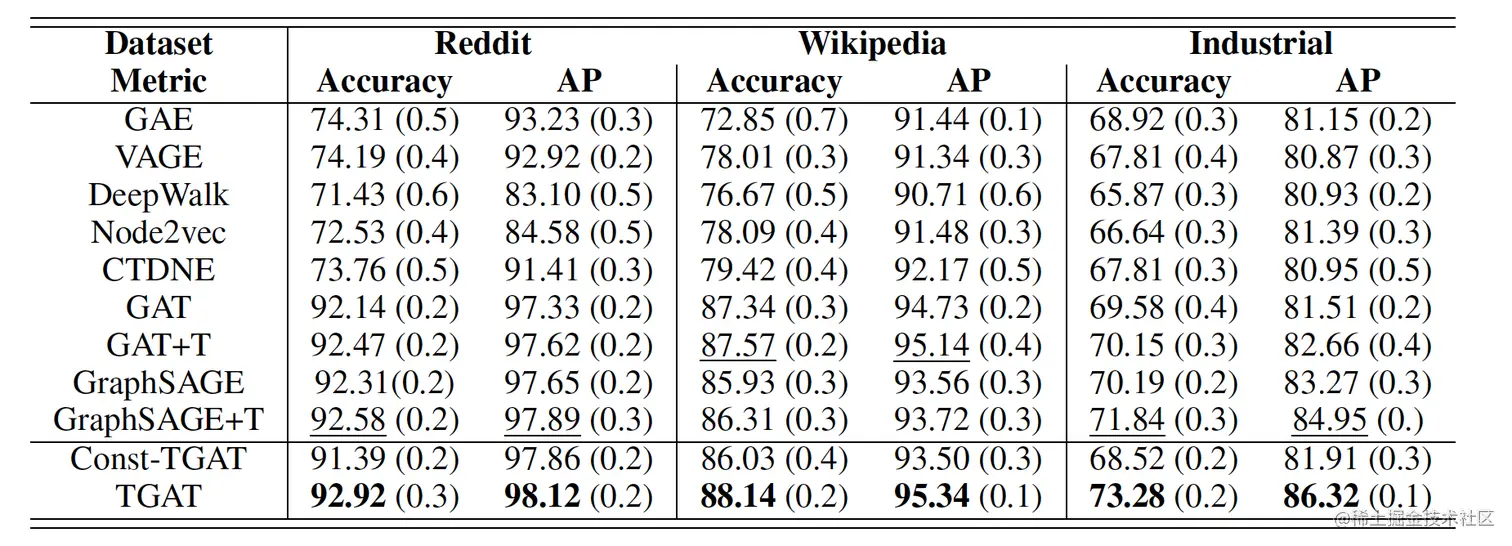
动态链接预测任务:
transductive:
- const-TGAT代表attention的值都是一样的(mean)
inductive:
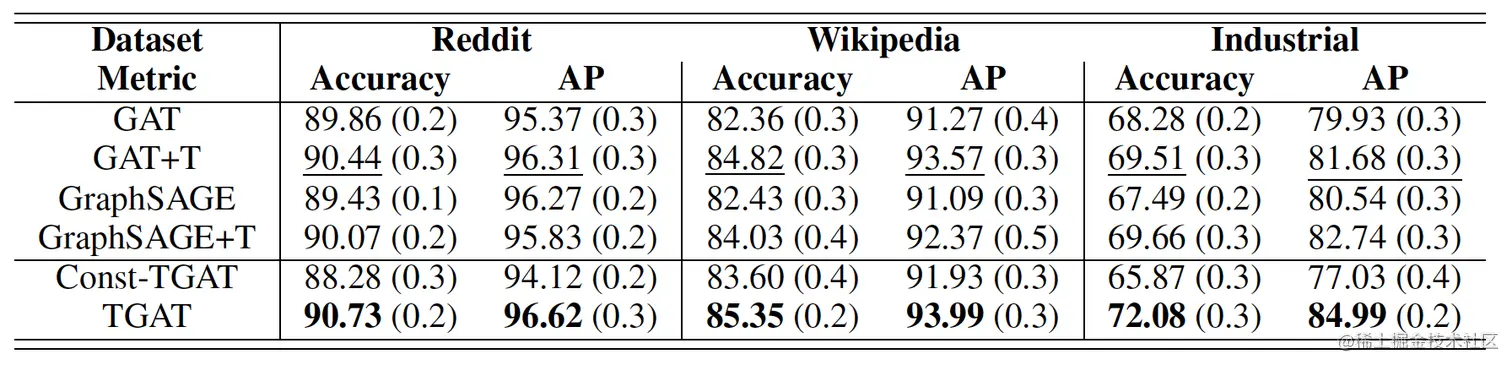
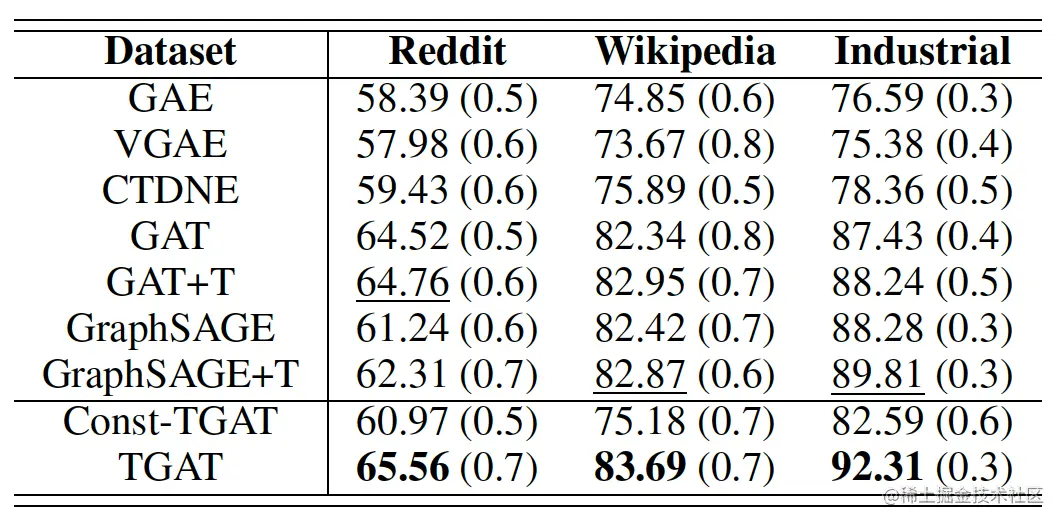
此外,还有动态节点分类任务:
- 根据上游学到的node embedding进行下游任务的预测
 消融实验:
消融实验:



