阅读本文需要的背景知识点:正态分布、线性判别分析、一丢丢编程知识
一、引言
前面一节介绍了基本的线性判别分析算法,最后留下了一个问题,我们在使用sklearn得到的结果与上一节中自己实现的结果不同,这一节就来看看sklearn中通过概率分布的角度是如何实现线性判别分析的。
二、模型介绍
一元正态分布
在介绍模型之前先来回顾一下一个在统计学中特别常见的分布——正态分布1(Normal distribution),同时也被称为高斯分布(Gaussian distribution),该分布是下面介绍模型的基础。
f(x;μ;σ)=σ2π1exp(−2σ2(x−μ)2)
上面为一元正态分布的概率密度函数,其中 x 为一元随机变量,μ 为位置参数,σ 为尺度参数。
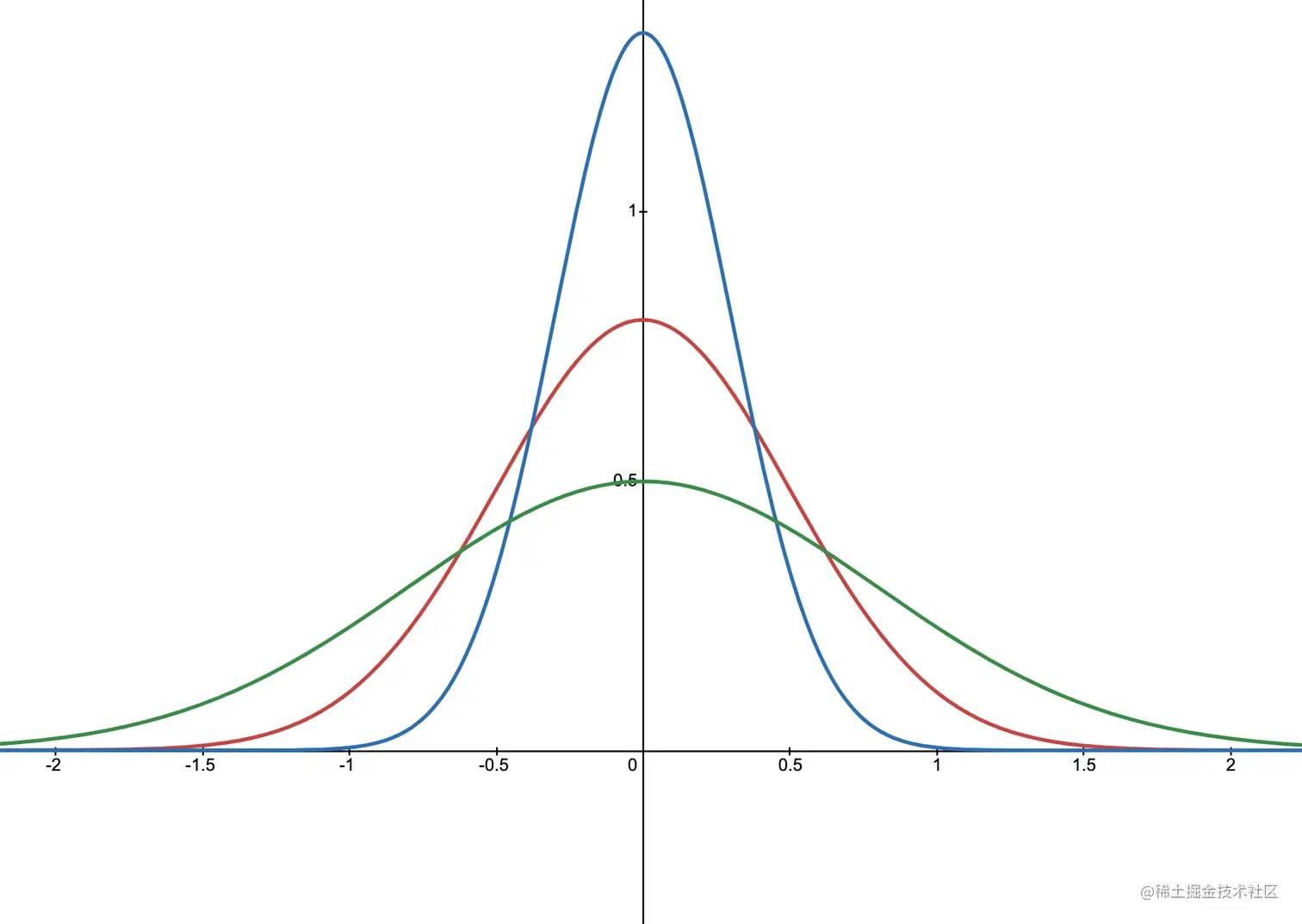
不同尺度参数的正态分布图示
多元正态分布
在机器学习中我们的输入特征一般是多维的,多元正态分布的概率密度函数可以从一元正态分布的概率密度函数得到的。为了简单起见,假设随机变量之间是独立的,即相互之间不存在线性相关性。
(1)随机变量之间相互独立,则联合概率密度函数为每一个随机变量的概率密度函数的乘积,其中x为p维
(2)分别带入各个一元概率密度函数
(3)将e的指数用z的平方来表示
(4)z的平方可以写成向量矩阵的形式
(5)观察中间的对角矩阵,用Σ来表示该对角矩阵的逆矩阵
(6)则z的平方可以简写成该式,x为特征向量,μ为均值向量。该表达式被称为马哈拉诺比斯距离2(Mahalanobis distance),用于表示数据的协方差距离
(7)观察Σ,Σ的行列式为对角线上的元素相乘,开根号后为各σ的乘积,|Σ|表示Σ的行列式
(8)带入回多元正态分布的概率密度函数中,得到最终的形式
f(x)z2Σz2∣Σ∣21f(x)=f(x1)f(x2)…f(xp)=σ1σ2…σp(2π)p1exp(−2σ12(x1−μ1)2−2σ22(x2−μ2)2−⋯−2σp2(xp−μp)2)=σ12(x1−μ1)2+σ22(x2−μ2)2+⋯+σp2(xp−μp)2=⎣⎡x1−μ1x2−μ2⋯xp−μp⎦⎤T⎣⎡σ1210⋮00σ221⋮0⋯⋯⋱⋯00⋮σp21⎦⎤⎣⎡x1−μ1x2−μ2⋯xp−μp⎦⎤=⎣⎡σ120⋮00σ22⋮0⋯⋯⋱⋯00⋮σp2⎦⎤=(x−μ)TΣ−1(x−μ)=σ1σ2…σp=∣Σ∣21(2π)2p1exp(−2(x−μ)TΣ−1(x−μ))(1)(2)(3)(4)(5)(6)(7)(8)
以上为相互独立的随机变量的多元正态分布的概率密度函数,对于任意的随机变量,该式亦成立,只是Σ表示随机变量的协方差矩阵。
贝叶斯定理
再来回顾一下概率论中的一个重要定理——贝叶斯定理3,在B事件发生时,A事件发生的概率等于在A事件发生时,B事件发生的概率乘以A事件发生的概率除以B事件发生的概率,用公式表示如下:
P(A∣B)=P(B)P(B∣A)P(A)
线性判别分析
前面铺垫了这么多前置知识,下面来介绍以概率的角度来实现线性判别分析的方法。首先我们需要假设样本点是服从正态分布,并且每一类样本的协方差矩阵相同,满足上面两点我们就可以开始推导线性判别分析的实现过程。
(1)我们先来看下在输入为x的情况下分类为k的概率,根据前面介绍的贝叶斯定理可得到下面的(1)式
(2)样本点服从正态分布,在分类为k的情况下,输入为x的概率可以用多元正态分布的概率密度函数表示
P(k∣x)=P(x)P(x∣k)P(k)=P(x)fk(x)P(k)(1)(2)
(1)我们的目的就是求在输入为x的情况下分类为k的概率最大的分类,所以我们可以写出假设函数如下图(1)式,该方法被称为最大后验概率估计4(maximum a posteriori probability (MAP) estimate)
(2)对其概率取对数,不影响函数的最后结果
(3)带入上面的P(k|x)的表达式,由于P(x)对最后结果也没有影响,也可以直接去掉
(4)带入多元正态分布的概率密度函数表达式
(5)将(4)式中的对数化简得到
(6)观察(5)式第二项,由于每一类样本的协方差矩阵相同,不影响最后的结果,可以直接去掉
h(x)=kargmaxP(k∣x)=kargmaxlnP(k∣x)=kargmaxlnfk(x)+lnP(k)=kargmaxln⎝⎛∣Σk∣21(2π)2pe−2(x−μk)TΣk−1(x−μk)⎠⎞+lnP(k)=kargmax−21(x−μk)TΣk−1(x−μk)−ln(∣Σk∣21(2π)2p)+lnP(k)=kargmax−21(x−μk)TΣk−1(x−μk)+lnP(k)(1)(2)(3)(4)(5)(6)
(1)我们再来看下上面(6)式中的第一项,将其展开
(2)观察第三项,可以合并成整体的转置的形式,注意协方差矩阵Σ为对称矩阵,其转置等于其本身
(3)上面第二三项互为转置,结果又是一个实数,所以其结果相等,可以直接合并为一项
(x−μk)TΣ−1(x−μk)=xTΣ−1x−xTΣ−1μk−μkTΣ−1x+μkTΣ−1μk=xTΣ−1x−xTΣ−1μk−(xTΣ−1μk)T+μkTΣ−1μk=xTΣ−1x−2xTΣ−1μk+μkTΣ−1μk(1)(2)(3)
(1)前面所得的假设函数
(2)用上面展开的结果替换第一项
(3)在(2)式中第一项的结果不影响最后的结果,也可以直接去掉,得到最后的假设函数
h(x)=kargmax−21(x−μk)TΣ−1(x−μk)+lnP(k)=kargmax−21xTΣ−1x+xTΣ−1μk−21μkTΣ−1μk+lnP(k)=kargmaxxTΣ−1μk−21μkTΣ−1μk+lnP(k)(1)(2)(3)
(1)将假设函数的函数部分写成新的一个函数L(x)
(2)将其中两类做差,当结果等于零时,即此时既可以将其分为i类,也可以分为j类。其本质为分类i与分类j的决策边界
(3)可以看到该决策边界是一个关于x的线性函数
Lk(x)Li(x)−Lj(x)=xTΣ−1μk−21μkTΣ−1μk+lnP(k)=xTΣ−1(μi−μj)−21(μiTΣ−1μi−μjTΣ−1μj)+lnP(i)−lnP(j)=xTw+b(1)(2)(3)
(1)、(2)根据上面的决策边界的线性函数形式,可以得到对应的w和b
(3)P(k) 表示k分类的先验概率,即k分类的样本数除以总样本数
(4)μ 表示均值向量
(5)Σ 为协方差矩阵的估计,因为需要使得每一个分类的协方差矩阵相同,这里将每一个分类的协方差矩阵相加后使用N-K来做归一化处理
wbP(k)μkΣ=Σ−1(μi−μj)=−21(μiTΣ−1μi−μjTΣ−1μj)+lnP(i)−lnP(j)=NNk=Nk1i=1∑Nkx=N−K1i=1∑K(x−μi)(x−μi)T(1)(2)(3)(4)(5)
当需要判断新样本点的分类时只需将样本点带入该线性函数中,对于二分类来说,最后的结果大于零,则分类为i,反之则分类为j。
两种角度下的线性判别分析的关系
两种角度下的线性判别分析的权重系数的公式如下:
w=Sw−1(μ1−μ2)w=Σ−1(μ1−μ2)(1)(2)
当每一个分类的协方差矩阵相同的时候,会有S_w 等于 2Σ,说明其权重系数的方向是相同的,当样本服从正态分布时且分类的协方差矩阵相同时,两种角度下线性判别分析的结果是相同的。
三、代码实现
使用 Python 实现线性判别分析(LDA):
def ldaBayes(X, y):
"""
线性判别分析(LDA)
args:
X - 训练数据集
y - 目标标签值
return:
W - 权重系数
b - 偏移量
"""
y_classes = np.unique(y)
c1 = X[y==y_classes[0]][:]
c2 = X[y==y_classes[1]][:]
mu1 = np.mean(c1, axis=0)
mu2 = np.mean(c2, axis=0)
sigma1 = c1 - mu1
sigma1 = sigma1.T.dot(sigma1)
sigma2 = c2 - mu2
sigma2 = sigma2.T.dot(sigma2)
sigma = (sigma1 + sigma2) / (X.shape[0] - len(y_classes))
sigman = np.linalg.pinv(sigma)
w = sigman.dot(mu2 - mu1)
b = -0.5 *(mu2.reshape(-1, 1).T.dot(sigman).dot(mu2) - mu1.reshape(-1, 1).T.dot(sigman).dot(mu1)) + np.log(len(c2) / len(c1))
return w, b
def discriminantBayes(X, w, b):
"""
判别新样本点
args:
X - 数据集
w - 权重系数
b - 偏移量
return:
分类结果
"""
r = X.dot(w) + b
r[r > 0] = 1
r[r <= 0] = 0
return r
四、第三方库实现
scikit-learn5 实现线性判别分析:
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
lda = LinearDiscriminantAnalysis()
lda.fit(X, y)
w = lda.coef_
b = lda.intercept_
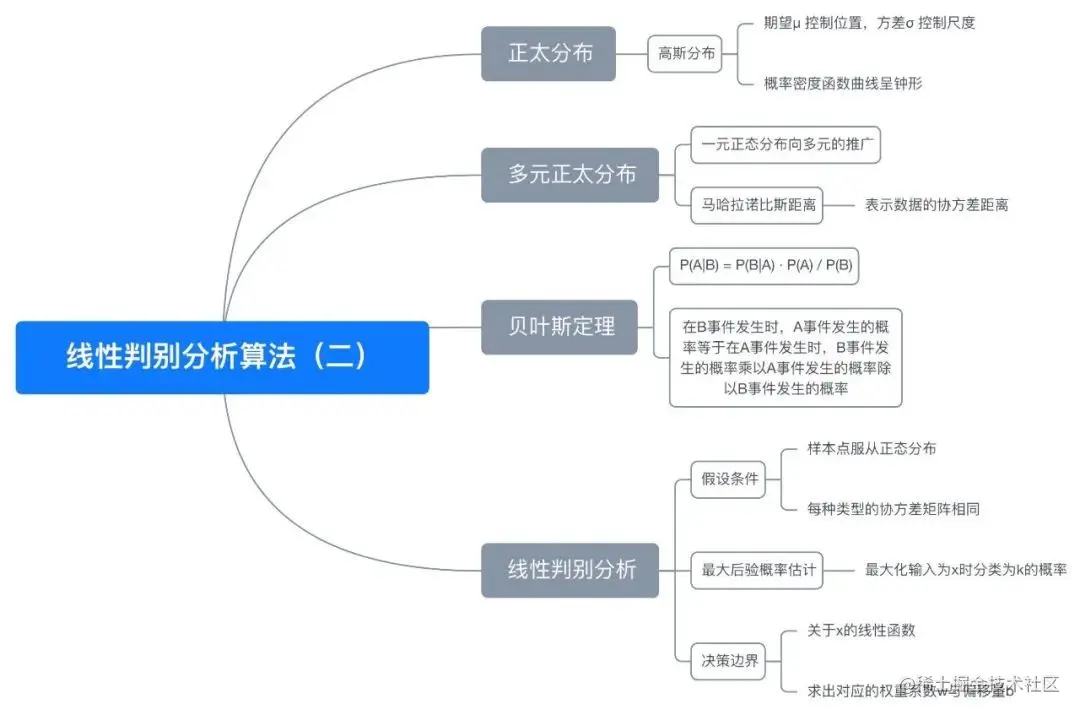
五、思维导图
六、参考文献
- en.wikipedia.org/wiki/Normal…
- en.wikipedia.org/wiki/Mahala…
- en.wikipedia.org/wiki/Bayes%…
- en.wikipedia.org/wiki/Maximu…
- scikit-learn.org/stable/modu…
完整演示请点击这里
注:本文力求准确并通俗易懂,但由于笔者也是初学者,水平有限,如文中存在错误或遗漏之处,恳请读者通过留言的方式批评指正
本文首发于——AI导图,欢迎关注


