

Java中线程创建非常昂贵, 需要jvm和os配合完成大量的工作
- 内存分配, 单独的栈内存, 至少1M
- 需要进行系统调用, 以便于在os中创建和注册本地线程
线程池解决问题
- 提升性能, 一次创建线程, 多次复用, 避免和频繁的创建销毁操作带来的性能开销
- 线程的管理, 统一管理, 可以动态的分配线程数量. 使得待处理的任务和存有的线程数保持一个相对均衡的状态.
JUC的线程池架构
- Executor
public interface Executor {
/**
* Executes the given command at some time in the future. The command
* may execute in a new thread, in a pooled thread, or in the calling
* thread, at the discretion of the {@code Executor} implementation.
*
* @param command the runnable task
* @throws RejectedExecutionException if this task cannot be
* accepted for execution
* @throws NullPointerException if command is null
*/
void execute(Runnable command);
}
定义了向线程池中提交任务的方法, 将执行者和提交者进行分离.
- ExecutorService
public interface ExecutorService extends Executor {
...
}
在Executor的基础上进行了扩展, 声明了更多的抽象方法, 用于以不同形式的任务处理接口, 和线程池的一些管理策略.
- AbstractExecutorService
public abstract class AbstractExecutorService implements ExecutorService {
对ExecutorService接口中的抽象方法进行了基本的实现.
- ThreadPoolExecutor
public class ThreadPoolExecutor extends AbstractExecutorService {
真正的线程池实现类.
- ScheduledExecutorService
public interface ScheduledExecutorService extends ExecutorService {
基于ExecutorService进行了进一步扩展, 用于支持延时和周期性任务的调度处理. 类似Timer/TimerTask.
- ScheduledThreadPoolExecutor
public class ScheduledThreadPoolExecutor
extends ThreadPoolExecutor
implements ScheduledExecutorService {
在常规线程池的基础上支撑延时和周期性调度的实现.
- Executors
public class Executors {
jdk封装的静态类, 用于通过各种静态工厂方法返回Executorservice和ScheduledExecutorService等线程池对象. 相当于jdk提供的快捷创建线程池入口. 如果使用者愿意, 也可以自己直接去操作ThreadpoolExecutor, 而不通过系统提供的静态方法.
这些类的关系类图
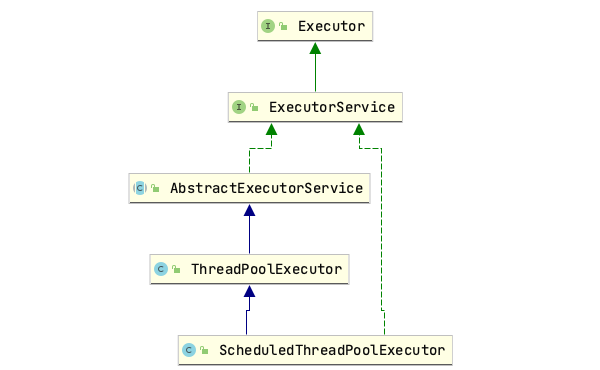
Executors线程池工厂
定义了多种创建线程池的方式
- 单线程化线程池
/**
* 单线程池
*/
private static void singleThreadPool() {
ExecutorService executorService = Executors.newSingleThreadExecutor();
IntStream.rangeClosed(1, 100).forEach(i->{
executorService.execute(()-> {
System.out.println(i);
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
});
executorService.shutdown();
//List<Runnable> runnables = executorService.shutdownNow();
}
- 任务的执行是按照任务的提交顺序执行的
- 线程池中唯一存活的线程是无限存活的
- 当线程正在处理其他任务时, 提交到线程池中的任务会被放入内部的阻塞队列, 且阻塞队列是无界的.
线程池的关闭
当调用线程池的shutdown方法后, 线程池状态变为shutdown, 这时线程池不会再接收新任务, 如果继续添加任务会抛出异常: rejectedExecutionException异常. 此时线程池不会立即退出, 直到线程池中的任务都处理完毕才会退出.
shutdownnow(), 执行后, 线程池变为: stop状态, 并会试图停止正在执行的线程, 且阻塞队列中的线程也不会被处理了, 然后返回未执行的任务列表
- newFixedThreadPool 固定数量的线程池
特点:
- 如果线程数没有到达固定线程数量, 每提交一个任务就会创建一个新线程, 直到线程数达到固定数量.
- 线程数量到达固定数量后, 就不会在发生变化, 如果线程因为异常结束, 线程池会立即补充一个新线程.
- 如果所有的线程都在执行中, 提交的新任务会被放在阻塞队列中, 无界队列
适用场景: cpu密集型.
缺点: 无界队列, 有耗尽服务器资源风险.
private static void fixedThreadPool() {
ExecutorService executorService = Executors.newFixedThreadPool(10);
IntStream.rangeClosed(1, 100).forEach(i->{
executorService.execute(()-> {
System.out.println(Thread.currentThread().getName()+"___________"+i);
});
});
}
- newCachedThreadPool创建"可缓存线程池"
private static void cachedThreadPool() {
ExecutorService executorService = Executors.newCachedThreadPool();
IntStream.rangeClosed(1, 100).forEach(i -> {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
executorService.execute(() -> {
System.out.println(Thread.currentThread().getName() + "___________" + i);
});
});
executorService.shutdown();
}
特点
- 在接收新任务时, 如果线程池中的所有线程都在繁忙, 就会创建新线程来处理新任务.
- 次线程池的大小没有限制, 有耗尽资源的风险.
- 如果线程空闲一定的时间, 且没有任务可执行, 就会被回收掉.
适用于处理突发任务, 但是需要考虑耗尽资源的风险.
-
newScheduledThreadPool 可调度线程池
4.1 创建仅有一个线程的可调度线程池
private static void scheduledSingleThreadPool() { ScheduledExecutorService executorService = Executors.newSingleThreadScheduledExecutor(); IntStream.rangeClosed(1, 100).forEach(i -> { try { Thread.sleep(10); } catch (InterruptedException e) { e.printStackTrace(); } executorService.execute(() -> { System.out.println(Thread.currentThread().getName() + "___________" + i); }); }); executorService.shutdown(); }线程会每隔10s钟, 执行一次1-100的输出, 由1个线程来完成
4.2 创建含有多个线程的可调度线程池
private static void scheduledThreadPool() { ScheduledExecutorService executorService = Executors.newScheduledThreadPool(10); IntStream.rangeClosed(1, 100).forEach(i -> { executorService.scheduleAtFixedRate(() -> { System.out.println(Thread.currentThread().getName() + "___________" + i); }, 0, 10000, TimeUnit.MILLISECONDS); }); }线程会每隔10s钟, 执行一次1-100的输出, 由10个线程来完成
延时任务同上.
Executors类中提供的静态方法非常好用, 但是在很多大厂中是被禁止的, 例如无界队列就很危险, 可能导致服务oom异常.
线程池的标准创建方式
Executors中的静态工厂方法创建线程池, 会在很多大厂规范中被禁止, 推荐的是使用标准构造器构造线程池, Executors的本质也是通过调用ThreadPoolExecutor的构造器来创建线程池. 多个重载版本中参数最全的一个有7个参数, 其他的构造器均建立在该构造器基础上.
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
- corePoolSieze, 核心线程数
- maximumPoolSize 最大线程数量
- keepAliveTime 核心线程数之外空闲线程最大存活时间
- unit 存活时间单位
- workQueue 阻塞队列, 在没哟空闲线程处理新任务时, 新任务放入阻塞队列
- threadFactory 线程创建工厂, 约束创建线程的方式, 以及属性
- handler 饱和策略, 线程池达到最大线程数, 且没有空余线程, 工作队列满时, 再提交任务, 线程池会拒绝该任务, 可以配置不同的拒绝策略
向线程池中提交任务的两种方式
- execute()
- submit()
比较:
- execute只能接收runnable参数. submit可以接收runnable, 和callable,
- callable类型的任务可以返回执行结果.且可以抛出异常. runnable不能有返回值, 且不能抛出异常.
- submit方便处理异常.
1. 通过submit返回的future对象获取结果
private static void futureTest() throws ExecutionException, InterruptedException {
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(1);
Future<Integer> future = scheduledExecutorService.submit(() -> 123);
System.out.println(future.get());
scheduledExecutorService.shutdown();
}
2. 通过submit提交任务, 通过future获取线程执行的异常信息
private static void futureExceptionTest() {
ExecutorService executorService = Executors.newCachedThreadPool();
Future exceptionFuture = executorService.submit(() -> {
throw new Exception("主动抛出异常");
});
try {
exceptionFuture.get();
} catch (InterruptedException e) {
System.out.println("获取到线程内异常信息1");
e.printStackTrace();
} catch (ExecutionException e) {
System.out.println("获取到线程内异常信息2");
e.printStackTrace();
}
executorService.shutdown();
}
## 输出
获取到线程内异常信息2
java.util.concurrent.ExecutionException: java.lang.Exception: 主动抛出异常
at java.base/java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.base/java.util.concurrent.FutureTask.get(FutureTask.java:191)
at main.java.com.lee.pool.SubmitTask.futureExceptionTest(SubmitTask.java:33)
at main.java.com.lee.pool.SubmitTask.main(SubmitTask.java:14)
Caused by: java.lang.Exception: 主动抛出异常
at main.java.com.lee.pool.SubmitTask.lambda$futureExceptionTest$1(SubmitTask.java:29)
at java.base/java.util.concurrent.FutureTask.run$$$capture(FutureTask.java:264)
at java.base/java.util.concurrent.FutureTask.run(FutureTask.java)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)
at java.base/java.lang.Thread.run(Thread.java:834)
线程池的任务调度流程
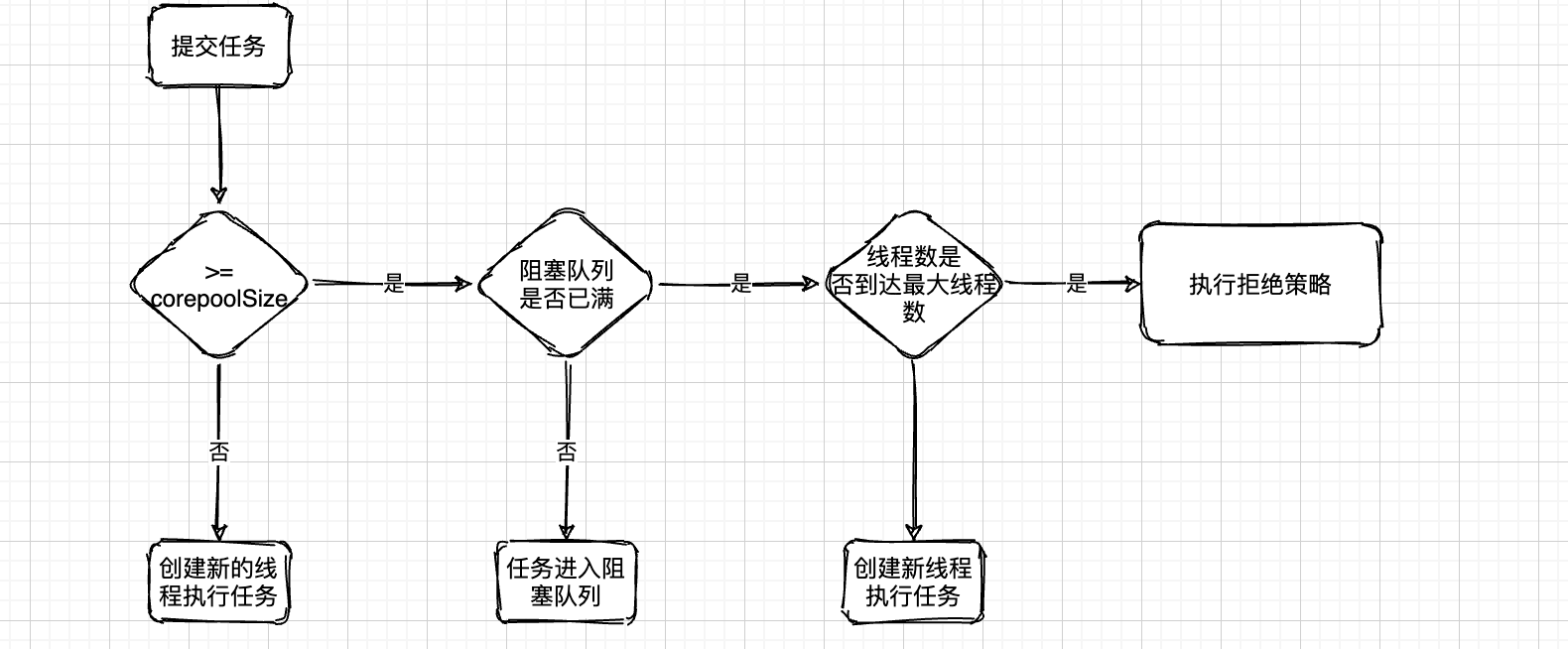
- 提交任务到线程池, 首先判断线程数是否到达核心线程数, 如果未到达则直接创建新线程执行任务, 如果已到达有空闲线程, 直接使用空闲线程执行, 如果没有空闲线程进入阻塞队列.
- 任务进入阻塞队列之前, 先判断阻塞队列是否已满, 如果没满, 直接进入阻塞队列等待有线程执行即可, 如果阻塞队列已满, 则判断当前线程总数是否到达最大线程数.
- 如果没有到达最大线程数, 则直接创建新的临时线程执行任务, 否则执行线程池的饱和策略
- 执行饱和策略
核心线程数和最大线程数如果配置不合理, 可能会导致任务得不到预期的并发执行效果, 造成严重的排队现象.
线程池创建额外的线程的前提是核心线程已满, 且阻塞队列已满.
ThreadFactory
在线程池中创建线程, 默认使用的是Executors.*defaultThreadFactory*() 默认工厂, 内容比较简单, 归属于统一的线程池, 都是非守护线程, 优先级都为5.
可以通过实现接口自定义线程池
public class MyThreadFactory implements ThreadFactory {
static AtomicInteger threadNo = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
String threadName = "my_thread_" + threadNo.incrementAndGet();
Thread thread = new Thread(r, threadName);
thread.setDaemon(false);
return thread;
}
}
在自定义线程工厂时, 可以自定义设置线程的优先级, 线程名称, 线程组, 守护进程等信息.
测试自定义线程工厂的使用
public class ThreadPoolWithDiyThreadFactory {
public static void main(String[] args) {
threadFactoryTest();
}
private static void threadFactoryTest() {
ExecutorService executorService = Executors.newFixedThreadPool(10, new MyThreadFactory());
IntStream.rangeClosed(1, 10).forEach(i->{
executorService.submit(() -> {System.out.println(Thread.currentThread().getName()+"__: "+i);});
});
executorService.shutdown();
}
}
## 输出
my_thread_5__: 4
my_thread_8__: 7
my_thread_7__: 6
my_thread_9__: 8
my_thread_6__: 5
my_thread_10__: 9
my_thread_11__: 10
my_thread_3__: 2
my_thread_4__: 3
my_thread_2__: 1
可以看到线程名称都是自定义的规则.
任务阻塞队列
在线程池中当待处理任务的数量超过核心线程数量时, 就会把待处理任务放入阻塞队列中, 等待有空闲线程时自动从阻塞队里中读取待处理任务.
Java阻塞队列在队列为空时, 会阻塞获取任务的线程, 直到队列中有任务, 即可唤醒读取任务线程, 整个过程不需要使用者参与.
BlockingQueue是JUC包中的一个超级接口, 比较常用的实现类:
-
ArrayBlockingQueue: 基于数组实现的FIFO的有界队列.
-
LinkedBlockingQueue: 基于链表实现的FIFO可有界/无界队列. 吞吐量高于ArrayBlockingQueue. 在构造队列时可指定容量, 即有界队列, 如果不指定容量, 默认容量为: integet.maxValue, 即理解为无界队列, 存在OOM风险.
在Executors线程池工厂中, 创建的newSingleThreadExecutor和newFixedThreadPool两个线程池使用的就是这个无界队列.
-
PriorityBlockingQueue: 具有优先级的无界队列
-
DelayQueue: 无界阻塞延迟队列, 底层是基于PriorityBlockingQueue实现, 队列中的每个元素都有一个过期时间, 当从对列头部获取任务时, 只有已过期的任务才会出队. 队头的元素时最早会过期的任务. 线程池工厂创建的newScheduledThreadPool使用的是该队列
-
SynchronousQueue(同步队列): 这是一个不存储元素的阻塞队列, 每个插入操作都必须等到有一个线程调用出队操作, 否则插入操作会一直处于阻塞状态, 吞吐量高于LinkedBlockingQueue, 工厂方法的newCachedThreadPool所创建的线程池使用的是该阻塞队列, 比较特殊, 不存储元素, 直接创建一个新线程来执行新任务.
调度器的钩子方法
ThreadPoolExecutor 线程池调度器为每个任务执行前后都提供了钩子方法, 提供了三个钩子方法, 默认实现为空, 需要子类来重写实现.
protected void beforeExecute(Thread t, Runnable r) { }
protected void afterExecute(Runnable r, Throwable t) { }
protected void terminated() { }
beforeExecute
在线程池中每个线程执行任务之前调用, 由工作线程调用, 可用于ThreadLocal线程本地变量初始化, 进行日志记录, 对线程执行时间计时, 更新上下文变量.
afterExecute
作用同beforeExecute, 只是执行时机为任务执行完成之后.
terminated
由最后一个工作线程执行完任务之后调用, 前提是必须要调用线程池的shutdown方法.
在Executors终止时调用.
💡 before/after 执行异常都可能造成线程终止, 因为都是由工作线程来调用.private static void testHook() {
ThreadLocal<Long> local = new ThreadLocal<>();
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(4, 5, 10, TimeUnit.SECONDS, new LinkedBlockingQueue<>(100)) {
@Override
protected void beforeExecute(Thread t, Runnable r) {
super.beforeExecute(t, r);
local.set(System.currentTimeMillis());
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
super.afterExecute(r, t);
Long aLong = local.get();
long time = System.currentTimeMillis() - aLong;
System.out.println(Thread.currentThread().getName()+": "+time);
local.remove();
}
@Override
protected void terminated() {
super.terminated();
System.out.println(Thread.currentThread().getName() + "结束");
}
};
IntStream.rangeClosed(1, 3).forEach(i ->
threadPoolExecutor.submit(() -> {
System.out.println(i);
try {
Thread.sleep(i * 1000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}));
threadPoolExecutor.shutdown();
}
## 输出
2
1
3
pool-1-thread-1: 1002
pool-1-thread-2: 2004
pool-1-thread-3: 3004
pool-1-thread-3结束
线程池的拒绝策略
在线程池的缓存队列为有界队列, 且无线程能够处理新任务时, 就会触发线程池的决绝策略, 具体的触发契机:
- 线程池关闭
- 工作队列满, 线程数到达maxPoolSize
在jdk中提供了接口RejectedExecutionHandler 的四种默认拒绝策略
- AbortPolicy: 拒绝, 且抛出异常
- discardPoliicy: 直接抛弃任务
- DiscardoldestPolicy: 抛弃最老任务策略
- CallerRunsPolicy: 调用者执行策略
实现类图

使用者还可以自定义拒绝策略, 通过实现接口: RejectedExecutionHandler
private static void testRejectedPolicy() {
ThreadPoolExecutor executor = new ThreadPoolExecutor(1,
3,
1,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1),
Executors.defaultThreadFactory(),
new MyRejectedExecutionHandler());
IntStream.rangeClosed(1, 10).forEach(i->{
executor.submit(() -> {
try {
Thread.sleep(1000L);
System.out.println(i);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
});
executor.shutdown();
}
## 输出
任务没有空闲资源可以执行: java.util.concurrent.FutureTask@8bd1b6a[Not completed, task = java.util.concurrent.Executors$RunnableAdapter@18be83e4[Wrapped task = main.java.com.lee.thread.RejectedTest$$Lambda$15/0x0000000800098440@cb5822]]
任务没有空闲资源可以执行: java.util.concurrent.FutureTask@42e26948[Not completed, task = java.util.concurrent.Executors$RunnableAdapter@57baeedf[Wrapped task = main.java.com.lee.thread.RejectedTest$$Lambda$15/0x0000000800098440@343f4d3d]]
任务没有空闲资源可以执行: java.util.concurrent.FutureTask@53b32d7[Not completed, task = java.util.concurrent.Executors$RunnableAdapter@5442a311[Wrapped task = main.java.com.lee.thread.RejectedTest$$Lambda$15/0x0000000800098440@548e7350]]
任务没有空闲资源可以执行: java.util.concurrent.FutureTask@1a968a59[Not completed, task = java.util.concurrent.Executors$RunnableAdapter@4667ae56[Wrapped task = main.java.com.lee.thread.RejectedTest$$Lambda$15/0x0000000800098440@77cd7a0]]
任务没有空闲资源可以执行: java.util.concurrent.FutureTask@204f30ec[Not completed, task = java.util.concurrent.Executors$RunnableAdapter@e25b2fe[Wrapped task = main.java.com.lee.thread.RejectedTest$$Lambda$15/0x0000000800098440@754ba872]]
任务没有空闲资源可以执行: java.util.concurrent.FutureTask@146ba0ac[Not completed, task = java.util.concurrent.Executors$RunnableAdapter@4dfa3a9d[Wrapped task = main.java.com.lee.thread.RejectedTest$$Lambda$15/0x0000000800098440@6eebc39e]]
3
1
4
2
线程池的优雅关闭
线程池启动后, 建议手动关闭, 用于节省不必要的系统开销.
线程池的5中状态:
- running: 创建好线程池的状态, 该状态下可执行任务.
- shutdown: 不再接收新任务, 会把队列中的任务执行完毕.
- stop: 中断所有工作线程, 不接受新任务, 和不处理队列中的任务.
- tidying: 所有任务都结束, 即将执行terminated钩子方法
- terminated: 执行完钩子方法: terminated()的状态.
多个状态之前的转换规则:
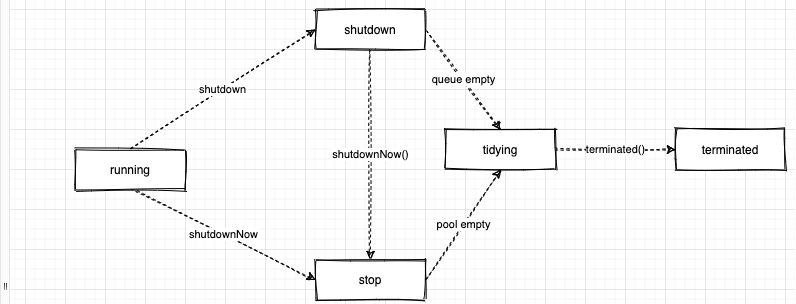
关闭线程池的方法:
- shutdown()
执行后立即返回, 线程池进入*SHUTDOWN 状态.*
- shutdownNow()
执行后立即返回, 线程池进入 STOP 状态.
- awaitTermination()
执行后会进入阻塞状态, 如果线程池还未关闭完成就返回false, 如果线程池关闭成功, 返回true.
大名鼎鼎的dubbo框架中的线程池关闭方式
if(!executor.isTerminated()) {
try {
for (int i = 0; i < 1000; i++) {
if (executor.awaitTermination(10, TimeUnit.MILLISECONDS)) {
break;
}
executor.shutdownNow();
}} catch (InterruptedException e) {
System.err.println(e.getMessage());
} catch (Throwable e) {
System.err.println(e.getMessage());
}
}
- 优雅关闭
public static void shutdownThreadPoolGracefully(ThreadPoolExecutor executor) throws InterruptedException {
if (!(executor instanceof ExecutorService) || executor.isTerminated()) {
return;
}
executor.shutdown();
if (!executor.awaitTermination(60, TimeUnit.SECONDS)) {
executor.shutdownNow();
}
try {
if (!executor.awaitTermination(60, TimeUnit.SECONDS)) {
System.out.println("未正常结束");
}
} catch (InterruptedException e) {
executor.shutdownNow();
}
if(!executor.isTerminated()) {
try {
for (int i = 0; i < 1000; i++) {//循环关闭1000次,每次等待10毫秒
System.out.println("第: " + i + "次关闭");
if (executor.awaitTermination(10, TimeUnit.MILLISECONDS)) {
break;
}
executor.shutdownNow();
}} catch (InterruptedException e) {
System.err.println(e.getMessage());
} catch (Throwable e) {
System.err.println(e.getMessage());
}
}
}
- 注册jvm钩子函数自动关闭线程池
static class SeqOrScheduledTargetThreadPoolLazyHolder{
static final ScheduledThreadPoolExecutor EXECUTOR = new ScheduledThreadPoolExecutor(1, Executors.defaultThreadFactory());
static {
Runtime.getRuntime().addShutdownHook(new Thread(()->{
System.out.println("系统要退出了");
try {
shutdownThreadPoolGracefully(EXECUTOR);
} catch (InterruptedException e) {
e.printStackTrace();
}
}));
}
}
Executors线程池工厂的潜在问题
FixedThreadPool和SingleThreadPool 阻塞队列长度为: Interger.MAX_VALUE
存在耗尽服务器内存资源的风险.
CacheThreadPool和ScheduledThreadPool 允许创建的最大线程数为: Integer.MAX_VALUE
存在耗尽服务器cpu资源的风险.
线程池线程数量的确定
按照任务类型对线程池分类
不同的任务类型在分配cpu资源时, 要看具体是使用场景, 例如cpu密集型和io密集型
为IO密集型任务确定线程数
io密集型, cpu使用率比较低, 导致线程的空余时间比较多, 通常需要开cpu核心数两倍的线程数量. 当线程处于io等待时, 可以开辟新线程用于处理其他任务. 从而提高cpu使用率. 大名鼎鼎的Netty就是典型的IO密集型任务处理框架, 在其框架内部定制的IO处理线程池数量刚好是CPU核心数的两倍.
cpu核心数获取.
private static final int *CPU_COUNT* = Runtime.*getRuntime*().availableProcessors();
核心线程数也可以允许超时销毁, 通过ThreadPoolTaskExecutor 实例方法: setAllowCoreThreadTimeOut(true) 实现.
为CPU密集型任务确定线程数
cpu密集型任务, 需要进行大量的计算消耗cpu资源, 为了如果线程数太多, 就会有太多的时间浪费在cpu线程的切换上, 合适的线程数应该是cpu核心数量.
为混合任务确定线程数
业界成熟估算公式
最佳线程数=((线程等待时间+线程cpu时间)/线程cpu时间)*cpu核心数
可见IO类型的任务处理时间越长, 需要的线程数就越大, 例如去db查询个数据1000ms, cpu处理100ms, 那么最终的线程数就是
(1000+100)/100 * cpu核心数 = 11*cpu核心数.
有些场景单线程的效率要高于多线程, 大名鼎鼎的redis就是, 6.0之前.
ThreadLocal原理与实战
在多线程环境中为了保证线程的安全性, 可以把变量放入ThreadLocal类型的对象中. 这样变量在每个线程中都是独立的.
ThreadLocal的基本使用
在TheadLocal类中提供单个基础api
set()保存值
get()获取值
remove()移除值
示例:
public class ThreadLocalDemo1 {
public static void main(String[] args) {
ThreadLocal<User> threadLocal = new ThreadLocal<>();
ExecutorService executorService = Executors.newFixedThreadPool(10);
IntStream.rangeClosed(1, 10).forEach(i->{
executorService.submit(()->{
IntStream.rangeClosed(1, 10).forEach(j->{
if (threadLocal.get() == null) {
threadLocal.set(new User());
} else {
threadLocal.get().setAge(threadLocal.get().getAge() + 1);
}
});
System.out.println(threadLocal.get().getAge());
});
});
executorService.shutdown();
}
static class User{
public User(){};
private int age;
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
}
## 输出
9
9
9
9
9
9
9
9
9
9
ThreadLocal的使用场景
- 线程隔离
- 跨函数传递数据
使用ThreadLocal进行线程隔离
天然支持, 让同一个变量在每个线程中都能享有一份独有的副本, 各个线程之前是隔离的, 不会出现线程安全问题.
使用ThreadLocal进行跨函数数据传递
使用示例:
public class Demo2 {
static ThreadLocal<Integer> local = new ThreadLocal<>();
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(2);
IntStream.rangeClosed(1, 10).forEach(i->{
executor.submit(() -> {
local.set(i);
print();
});
});
executor.shutdown();
}
private static void print() {
System.out.println("通过threadLocal传递变量: " + local.get());
local.remove();
}
}
## 输出
通过threadLocal传递变量: 1
通过threadLocal传递变量: 2
通过threadLocal传递变量: 3
通过threadLocal传递变量: 4
通过threadLocal传递变量: 5
通过threadLocal传递变量: 6
通过threadLocal传递变量: 7
通过threadLocal传递变量: 8
通过threadLocal传递变量: 9
通过threadLocal传递变量: 10
ThreadLocal内部结构分析
一个泛型类, 提供了基础的操作方法:
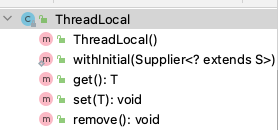
三个基础操作方法: get(), set(), remove().
ThreadLocal源码分析
三个基础方法源码:
set
public void set(T value) {
// 获取当前线程
Thread t = Thread.currentThread();
// 获取当前线程中的ThreadLocalMap 实例属性
ThreadLocalMap map = getMap(t);
// 如果map不为空, 直接设置值, key为当前threadLocal对象, value为目标值
if (map != null) {
map.set(this, value);
} else {
// 如果map为空, 通过threadLocalMap构造函数初始化实例, 并设置键值对,
// 键值对同上面的.
createMap(t, value);
}
}
get
public T get() {
// 获取当前线程对象
Thread t = Thread.currentThread();
// 获取当前线程对象的threadLocalMap实例属性
ThreadLocalMap map = getMap(t);
// 判断map是否为空
if (map != null) {
// 不为空, 从map中获取key为当前threadLocal对象的value
ThreadLocalMap.Entry e = map.getEntry(this);
// 如果value不为空
if (e != null) {
// 转换结果为ThreadLocal对象的具体类型
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
// 如果map为空, 或者value为空, 初始化map, 并设置值为null, 并返回null, 下次再获取时
// 可以直接从map中获取到null值, 此操作只在第一次操作时运行.
return setInitialValue();
}
remove
public void remove() {
// 获取当前线程对象的ThreadLocalMap 实例属性.
ThreadLocalMap m = getMap(Thread.currentThread());
// 如果map不为空, 从map中移除key为当前threadLocal对象的key, value值.
if (m != null) {
m.remove(this);
}
}
在构造ThreadLocal对象时, 可以设置初始回调函数, 用于初始化ThreadLocal对象中的初始值
ThreadLocal<User> threadLocal = ThreadLocal.*withInitial*(User::new);
ThreadLocalMap源码分析
在ThreadLocal中的get, set, remove方法都用到了线程对象中的ThreadLocalMap对象, 这个对象是ThreadLocal类中的一个静态内部类, 实现类简单的Map结构. 和HashMap很类似, 但是功能没有HashMap强大.
主要成员变量
static class ThreadLocalMap {
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
/**
* The initial capacity -- MUST be a power of two.
*/
private static final int INITIAL_CAPACITY = 16;
/**
* The table, resized as necessary.
* table.length MUST always be a power of two.
*/
private Entry[] table;
/**
* The number of entries in the table.
*/
private int size = 0;
/**
* The next size value at which to resize.
*/
private int threshold; // Default to 0
ThreadLocalMap对象中的set方法
private void set(ThreadLocal<?> key, Object value) {
// We don't use a fast path as with get() because it is at
// least as common to use set() to create new entries as
// it is to replace existing ones, in which case, a fast
// path would fail more often than not.
// 引用当前table
Entry[] tab = table;
// 获取当前tab长度
int len = tab.length;
// 根据key和tab的最大下标值与运算, 得到新值的下标值
int i = key.threadLocalHashCode & (len-1);
// 从得到的下标值开始遍历tab, 直到找到空余槽点, 如果没有会进行扩容.
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
// 获取当前
ThreadLocal<?> k = e.get();
// 找到现有槽点, 如果key为当前ThreadLocal对象实例, 覆盖value即设置成功, 返回
if (k == key) {
e.value = value;
return;
}
// 如果找到的槽点被GC回收了, 重设key值和value, 并返回成功.
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
// 如果没有找到现有槽点, 新增新的槽点.
tab[i] = new Entry(key, value);
// 元素数量+1
int sz = ++size;
// 清除key为null的Entry, 如果没有空, 且容量达到或者超过扩容阈值, 执行tab的扩容操作.
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
- Entry的key为何使用弱引用
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
在ThreadLocalMap中的Entry中的key被WeakReference 对key值进行包装, 其原因是:
在一个线程中创建ThreadLoal对象后, 并使用了ThreadLocal对象, 这时在线程栈中对 ThreadLocal对象的引用为强引用, Entry中的key对ThreadLocal对象的引用为弱引用, 这时如果线程执行结束, 那么线程栈对ThreadLocal对象的强引用就没有了, 只剩下Entry中的key对ThreadLocal对象的弱引用, 在jvm执行下一次gc时, 仅有弱引用的对象就会被回收掉, 如果这里的弱引用使用强引用, 就会造成内存泄露的发生.
在key被回收后, 在ThreadLocal中执行get, set , remove方法时, 都会清理key为null的entry. 从而完成相应的内存释放.
ThreadLocal发生内存泄露的前提条件
- 线程长时间运行而没有被销毁, 线程池中的核心线程就不会被销毁.
- ThreadLoca引用被设置为null, 并且其他线程也一直没有执行ThreadLoal对象的get, set, remove, clean方法得不到执行.
static final 修饰ThreadLocal对象
ThreadLocal实例作为ThreadLocalMap对象中的key, 所以在一个线程内所有的操作都是共享的, 所以建议设置为static, 方便被所有对象共享, 且静态变量在类加载时会分配内存空间, 且只会分配一次, 所以还可以节省内存空间, 为了保证实例的唯一性, 使用final可以防止其被动态更改.
private static final ThreadLocal LOCAL_FOO=new ThreadLocal();
静态的副作用是, ThreadLocalMap中引用的key在Thread生命周期内不会为null, 从而导致entry不会被回收, 所以Value也不会被回收从而导致内存泄露, 只能通过手动的remove方法来显示的释放操作.
如果是线程池, 可以在线程池的钩子方法中调用remove操作, 完成资源释放.
public class ThreadLocalDemo2 {
private static final ThreadLocal<String> threadLocal = new ThreadLocal<>();
public static void main(String[] args) {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
10,
10,
10,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(2)){
@Override
protected void afterExecute(Runnable r, Throwable t) {
threadLocal.remove();
}
};
}
}
使用总结
- private static final 修饰
- 主动调用remove
ThreadLocal综合使用案例
public class PractiseDemo {
public void serviceMethod() {
sleepSecond(1);
SpeedLog.logPoint("service");
daoMethod();
rpcMethod();
}
public void daoMethod() {
sleepSecond(2);
SpeedLog.logPoint("dao");
}
public void rpcMethod() {
sleepSecond(3);
SpeedLog.logPoint("rpc");
}
private static void sleepSecond(int time) {
try {
Thread.sleep(time * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
PractiseDemo practiseDemo = new PractiseDemo();
ExecutorService executorService = Executors.newSingleThreadExecutor();
executorService.submit(() -> {
SpeedLog.beginSpeedLog();
practiseDemo.serviceMethod();
SpeedLog.print();
SpeedLog.endSpeedLog();
});
executorService.shutdown();
}
}
public class SpeedLog {
private static final ThreadLocal<Map<String, Long>> TIME_RECORD_LOCAL = ThreadLocal.withInitial(SpeedLog::initialStartTime);
private static Map<String, Long> initialStartTime() {
HashMap<String, Long> map = new HashMap<>();
map.put("start", System.currentTimeMillis());
map.put("last", System.currentTimeMillis());
return map;
}
public static final void beginSpeedLog() {
TIME_RECORD_LOCAL.get();
}
public static final void endSpeedLog() {
TIME_RECORD_LOCAL.remove();
}
public static final void logPoint(String point) {
Long start = TIME_RECORD_LOCAL.get().get("last");
long cost = System.currentTimeMillis() - start;
TIME_RECORD_LOCAL.get().put(point + "cost: ", cost);
TIME_RECORD_LOCAL.get().put("last", System.currentTimeMillis());
}
public static void print() {
System.out.println(TIME_RECORD_LOCAL.get().toString());
}
}
輸出
{last=1639645309369,
daocost: =2005,
start=1639645303344,
servicecost: =1001,
rpccost: =3002}
