

初始化
realworld前端
vue3-realworld-example-app (github.com)
nuxt-realworld: Nuxt & Composition API (github.com)
realworld后端
RealWorld-API-in-Express (github.com)
拉取vue3或者nuxt工程到本地
这个两个realworld项目演示了用 vue3构建的成熟的全堆栈应用程序,包括 CRUD 操作、身份验证、路由、分页等等。
这是一个博客一样的网站,提供了登录注册、发布编辑和展示文章、数据分页、标签列表等基本功能,接下来铜鼓GraphQL的方式实现后端接口
接下来以学习ApolloServer的项目基础上进行更改,以更快的进入开发,启动服务器
nodemon index.js
index.js内原有的业务代码删掉,添加一个foo查询用于测试
const { ApolloServer, gql } = require('apollo-server-express')
const express = require('express')
const http = require('http')
const typeDefs = gql`
type Query {
foo: String
}
`
const resolvers = {
Query: {
foo() {
return "hello"
}
}
}
const app = express()
async function startApolloServer(typeDefs, resolvers) {
const httpServer = http.createServer(app)
const server = new ApolloServer({
typeDefs,
resolvers
})
await server.start()
server.applyMiddleware({ app })
await new Promise(resolve => httpServer.listen({ port: 4000 }, resolve))
console.log(`🚀 Server ready at http://localhost:4000${server.graphqlPath}`)
}
startApolloServer(typeDefs,resolvers)
模块化项目结构
接下来对项目结构进行一个简单的改造,为了项目复杂化之后有一个清晰的结构,将对业务代码进行模块化处理
type-defs
新建type-defs/index.js,将index.js内的typeDefs代码放到这里,引入模块并抛出
const { gql } = require('apollo-server-express')
const typeDefs = gql`
type Query {
foo: String
}
`
module.exports = typeDefs
resolvers
新建resolvers/index.js,将index.js内的resolvers代码放在这里并抛出
const resolvers = {
Query: {
foo() {
return "hello"
}
}
}
module.exports = resolvers
schema.js
在根目录新建一个schema.js,导入@graphql-tools/schema的makeExecutableSchema方法,这个方法用于将typeDefs和resolvers合并为一个schema
接下来引入type-defs/index.js 和 resolvers/index.js,调用这个方法得到schema并抛出
const { makeExecutableSchema } = require('@graphql-tools/schema')
const typeDefs = require('./type-defs')
const resolvers = require('./resolvers')
const schema = makeExecutableSchema({
typeDefs,
resolvers
})
module.exports = schema
index.js
回到index.js中将这个schema引入,删除ApolloServer下的 typeDefs 和 resolvers,替换为这个schema,index.js就变成了这样:
const { ApolloServer } = require('apollo-server-express')
const express = require('express')
const http = require('http')
const schema = require('./schema.js')
const app = express()
async function startApolloServer(schema) {
const httpServer = http.createServer(app)
const server = new ApolloServer({
schema
})
await server.start()
server.applyMiddleware({ app })
await new Promise(resolve => httpServer.listen({ port: 4000 }, resolve))
console.log(`🚀 Server ready at http://localhost:4000${server.graphqlPath}`)
}
startApolloServer(schema)
服务器已启动表示项目运行正常
查询语句可以正常显示和返回结果
config
将mongoose的连接配置放到config/config.default.js并抛出
module.exports = {
dbConfig: 'mongodb://max:123456@192.168.35.108:27017/realworld?!authSource=admin&readPreference.....',
jwtSecret: '9f10a257-5fc8-4fb9-a4bd-f32d40f7918d'
}
models
拿到realworld后端项目的model放到这里导入
models/index.js 用于连接数据库和导入数据库模型
const mongoose = require('mongoose')
const { dbConfig } = require('../config/config.default')
mongoose.connect(dbConfig)
const db = mongoose.connection
db.on('error', console.error.bind(console, 'connection error:'))
db.once('open',async ()=> {
console.log("数据库连接成功!")
})
module.exports = {
User: mongoose.model('User', require('./user.js')),
Article: mongoose.model('Article', require('./article.js'))
}
models/article.js
const mongoose = require('mongoose')
const baseModel = require('./base-model')
const Schema = mongoose.Schema
const articleSchema = new mongoose.Schema({
title: {
type: String,
required: true
},
description: {
type: String,
required: true
},
body: {
type: String,
required: true
},
tagList: {
type: [String],
default: null
},
favoritesCount: {
type: Number,
default: 0
},
author: {
type: Schema.Types.ObjectId,
ref: 'User',
required: true
},
...baseModel
})
module.exports = articleSchema
models/user.js
const mongoose = require('mongoose')
const baseModel = require('./base-model')
const md5 = require('../util/md5')
const userSchema = new mongoose.Schema({
username: {
type: String,
required: true
},
email: {
type: String,
required: true
},
password: {
type: String,
required: true,
set: value => md5(value), // 从Model层面上,set password进行md5处理
//select: false // 查询时不返回password字段,在graphql中关闭,因为允许返回什么字段在模式中会定义,设置关闭无法读取会影响密码校验
},
bio: {
type: String,
default: null
},
image: {
type: String,
default: null
},
...baseModel
})
module.exports = userSchema
以及user.js和article都引入的base-model
// 公共的模型字段
module.exports = {
createdAt: {
type: Date,
default: Date.now
},
updatedAt: {
type: Date,
default: Date.now
}
}
util
models/user.js引入了一个util/md5,创建这个文件,并安装crypto模块(加密功能)
const crypto = require('crypto')
module.exports = str => {
return crypto.createHash('md5')
.update(str)
.digest('hex')
}
util/jwt.js ( 跨域认证 ) 安装 jsonwebtoken 模块并引入,之后的账户验证会用到
const jwt = require('jsonwebtoken')
const { promisify } = require('util')
exports.sign = promisify(jwt.sign)
exports.verify = promisify(jwt.verify)
exports.decode = promisify(jwt.decode)
data-sourses
这里用来定义方法,操作数据库,这里的方法会提供给resolvers调用来获取数据库的数据并返回给客户端
创建 user.js、article.js、tag.js,具体操作开发的时候再写
const { MongoDataSource } = require('apollo-datasource-mongodb')
class Users extends MongoDataSource {
getUser(userId) {
return this.findOneById(userId)
}
getUsers() {
return this.model.find()
}
}
module.exports = Users
const { MongoDataSource } = require('apollo-datasource-mongodb')
class Articles extends MongoDataSource {
}
module.exports = Articles
创建data-sourses/index.js,引入数据库模型和用于操作数据库的data-sources
将data-sources实例化,传入数据库模型并抛出dataSources对象
const dbModel = require('../models')
const Users = require('./user')
const Articles = require('./article')
module.exports = () => {
return {
users: new Users(dbModel.User),
articles: new Articles(dbModel.Article)
}
}
将dataSources引入index.js,并导入ApolloServer
const dataSources = require('./data-sources')
//---------------------------------
const server = new ApolloServer({
schema,
dataSources
})
现在的目录结构
启动项目
测试连接成功
连接完成数据库管理工具显示,数据库和集合也被创建了
设计登录注册的Schema
从用户的登录注册开始来实现GraphQL的接口,参考realworld官方提供的RESTful API规范,转换为GranphQL
Endpoints | RealWorld (gothinkster.github.io)
这里是登录、注册API,点击returns a User 可以看到登录注册后返回给客户端的数据结构
找到type-defs.index.js,添加登录和创建用户的Mutation,可以看到返回数据是包裹在一个user内的,可以定义一个UserPayload包裹User
const { gql } = require('apollo-server-express')
const typeDefs = gql`
type Query {
foo: String
}
type User {
email: String!
username: String!
bio: String
image: String
token: String
}
type UserPayload {
user: User
}
input LoginInput {
email: String!
password: String!
}
input CreateUserInput {
username: String!
email: String!
password: String!
}
type Mutation {
login(user: LoginInput): UserPayload
createUser(user: CreateUserInput): UserPayload
}
`
module.exports = typeDefs
接下来就是按照这些schema的要求实现这两个Mutation
用户注册基本流程
声明创建用户处理器
找到resolvers/index.js
创建createUser的Mutation,接收并打印args,按照typeDefs返回UserPayload格式,简单写一下用于测试
const resolvers = {
Query: {
foo() {
return "hello"
}
},
Mutation: {
createUser (parent, args, context) {
console.log(args);
return {
user: {
email: "abc@def.com",
username: "Max",
bio: "xxx",
image: "yyy",
token: "zzz"
}
}
}
}
}
module.exports = resolvers
打开测试页面勾选createUser的Mutation,输入参数,执行语句后返回了预定的数据
服务端终端也打印了请求信息
对用户名和邮箱进行查重验证
解构出user,接下来对请求进行判断和处理
createUser (parent, { user }, context) {
// 判断邮箱是否存在
// 判断用户名是否存在
// 保存用户
// 生成token 发送给客户端
return {
user: {
email: "abc@def.com",
username: "Max",
bio: "xxx",
image: "yyy",
token: "zzz"
}
}
}
到data-sources/user.js声明操作数据库的方法
const { MongoDataSource } = require('apollo-datasource-mongodb')
class Users extends MongoDataSource {
findByEmail (email) {
return this.model.findOne({
email
})
}
findByUsername (username) {
return this.model.findOne({
username
})
}
}
module.exports = Users
回到resolvers/index.js调用这个个类中的实例
需要注意ApolloServer抛出错误不是使用状态码,它提供了UserInputError来抛出用户输入错误
const { UserInputError } = require("apollo-server-core")
const resolvers = {
Query: {
foo() {
return "hello"
}
},
Mutation: {
async createUser (parent, { user }, { dataSources }) {
// 判断邮箱是否存在
//获取data-sources/user.js抛出的Users类来调用其中的方法,返回值为数据库取回的数据
const users = dataSources.users
const hasEmail = await users.findByEmail(user.email)
if(hasEmail) {
// 抛出错误使用ApolloServer提供的用户输入错误方法来返回错误信息
throw new UserInputError('邮箱已存在')
}
// 判断用户名是否存在
const hasUser = await users.findByUsername(user.username)
if(hasUser) {
throw new UserInputError('用户名已存在')
}
// 保存用户
// 生成token 发送给客户端
return {
user: {
email: "abc@def.com",
username: "Max",
bio: "xxx",
image: "yyy",
token: "zzz"
}
}
}
}
}
module.exports = resolvers
查询页面测试,没有抛出错误,说明验证通过了
向数据库添加用户信息
用户名和邮箱查重验证通过了,接下来就是保存用户信息到数据库
data-sources/user.js添加想数据库保存用户的方法
saveUser (user) {
return new this.model(user).save()
}
判断用户名邮箱下执行这个方法,并打印测试
// 判断邮箱是否存在
// 判断用户名是否存在
// 保存用户
const userData = await users.saveUser(user)
console.log(userData);
测试页面添加注册用户信息,执行语句,返回预定结果,数据库添加数据成功,服务器终端打印出了数据库返回信息
当再次执行这个语句,就会报错,返回错误信息,说明查重也生效了
返回数据给客户端测试
将获取到的userData展开到user里面,由于数据库返回的并不是一个普通的js对象,需要调用它的toObject方法转换一下,这里不需要去除不能返回给客户端的数据,因为geaphql语句的返回值类型就已经定义了客户端只能取回哪些
// 生成token 发送给客户端
return {
user: {
...userData.toObject(),
token: "zzz"
}
}
向数据库添加一个新的用户,返回了新输入的邮箱和用户名
生成用户token
resolvers/index.js 上方引入 jwt.js 和 jwt秘钥
调用方法
const jwt = require('../util/jwt')
const { jwtSecret } = require('../config/config.default')
// 保存用户
const userData = await users.saveUser(user)
// 生成token 发送给客户端
const token = await jwt.sign({ userId: userData._id }, jwtSecret, { expiresIn: 60 * 60 * 24 })
return {
user: {
...userData.toObject(),
token
}
}
测试创建用户后返回token
用户登录
resolvers/index.js引入md5
const md5 = require('../util/md5')
async login (parent, { user }, { dataSources }) {
// 查询用户是否存在
const userData = await dataSources.user.findByEmail(user.email)
if(!userData) {
throw new UserInputError('邮箱不存在')
}
// 验证密码是否正确
if(md5(user.password) !== userData.password) {
throw new UserInputError('密码错误')
}
// 生成token
const token = await jwt.sign({ userId: userData._id }, jwtSecret, { expiresIn: 60 * 60 * 24 })
// 发送成功响应
return {
user: {
...userData.toObject(),
token
}
}
}
语句测试
获取当前登录用户
在全局context中获取用户token
type-defs 定义schema
首先定义一下这个这个接口的schema,这是一个GET方法,是查询的请求,返回的也是个User类型,遭到type-defs/index.js,在Query内添加一个查询类
type Query {
#foo: String
crrentUser: User
}
resolvers 声明
回到resolvers/index.js
Query: {
currentUser (parent, args, context, info) {
// 获取当前登录用户信息
// 返回用户的信息
}
}
客户端发送token
客户端发起请求,获取当前登录用户的信息的方式,是将登录后获得的token放到请求头headers内,通过向请求头内添加 Authorization 这个字段,返回 Token给服务器
发起登录请求,获取token
将token放到请求头内
context接收token
但是需要注意 currentUser() 中是拿不到请求头的,这时就需要context,通过context将token传入resolvers,然后在currentUser()中提取出来以使用
index.js 添加context方法,并解构出请求体,打印headers来测试一下是否接收到了请求体
onst server = new ApolloServer({
schema,
dataSources,
// 所有的GraphQL查询都会经过这里
context({req}) {
console.log(req.headers)
}
})
保存后终端打印了请求头信息
既然可以获取,接下来就是将token返回给context
const server = new ApolloServer({
schema,
dataSources,
context({req}) {
const token = req.headers['authorization']
return {
token
}
}
})
resolvers接收token
resolvers打印查看是否完成传递
Query: {
currentUser (parent, args, context, info) {
console.log(context.token);
}
}
语句测试
终端成功打印
获取到token后,把token解析出来,拿到用户id,查数据库获取user数据
身份认证方式介绍
为什么需要验证token
查询数据库前,还需要对token进行校验登录状态,如果没有token说明客户端根本没有登录,那需要给客户端返回一个没有授权的错误,如果授权是无效的也要返回一个登录无效的错误,如果token过期了,也要返回一个过期,最简单的方法就是在请求内处理这个判断来返回登录请求的信息,但是这样的验证除了在当前请求会使用,其他接口也是这样一个校验登录状态的逻辑
所以,需要对当前登录状态校验进行封装,在resolvers内写一个函数,在需要校验的请求内调用函数
但是这样频繁和选择性的调用校验函数韩式显得过于麻烦的
官方文档提供的方法
Apollo文档内给了解决方案,怎样在GraphQL内进行权限验证,这个页面文档描述了怎样验证,首先验证信息token放入context,就是上一步的操作
Authentication and authorization - Apollo Server - Apollo GraphQL Docs
接下来就是提供的权限验证的几个方法
-
后台管理,内部使用的app,只有登录相关的数据可以访问,其他所有的操作都需要进行登录验证才能进行,这时就可以在context内进行统一的认证
context: ({ req }) => { // get the user token from the headers const token = req.headers.authorization || ''; // try to retrieve a user with the token const user = getUser(token); // optionally block the user // we could also check user roles/permissions here if (!user) throw new AuthenticationError('you must be logged in'); // add the user to the context return { user }; }但是对于部分权限开放的,未登录时部分接口可以访问的情况就不适用了
-
在每一个resolver中执行判断,比较麻烦
-
根据不同的要求进行认证,也不太好用
-
通过在Schema中自定义指令的方式,在访问某个属性的时候加上一个行为,类似于中间件,去做统一处理
-
定义指令@auth( 指定参数角色权限 ) on 生效位置( 对象 | 字段 )
-
enum枚举出有哪些角色权限
-
在需要验证的类型后添加这个指令并传入参数指定角色权限
const typeDefs = ` directive @auth(requires: Role = ADMIN) on OBJECT | FIELD_DEFINITION enum Role { ADMIN REVIEWER USER } type User @auth(requires: USER) { name: String banned: Boolean @auth(requires: ADMIN) canPost: Boolean @auth(requires: REVIEWER) } `不是说在这里定义并调用了自定义指令并调用了就会生效
还需要实现自定义指令的行为,这需要自己去写逻辑
-
默认指令Default directives
The GraphQL specification defines the following default directives:
| DIRECTIVE | DESCRIPTION |
|---|---|
@deprecated(reason: String) | 当访问某个字段时,Schema架构升级了,但是原来的字段不想删除掉,不然客户端会报错,加入指令表示将来弃用 |
@skip(if: Boolean!) | 如果给if的参数为true,就表示跳过这个字段,不返回给客户端,是提供给客户端查询语法时使用 |
@include(if: Boolean!) | 如果给if的参数是true,就表示这个字段被包含,允许返回给客户端,是提供给客户端查询语法时使用 |
@include和@skip
上面说了@include和@skip是提供给客户端查询语句传参判断是否允许返回的指令,后端在收到这个查询语句时,skip参数if为true会跳过这个字段,include参数if为false返回数据就不包含这个字段
@deprecated
在typeDefs中添加指令,并指定返回的信息
const typeDefs = gql`
type User {
email: String!
username: String! @deprecated(reason: "请使用newUserName")
newUserName: String
bio: String
image: String
token: String
}
`
当进行语句查询测试时,查询结果可以正确返回,但是会出现标黄警告
自定义指令
定义一个指令
自定义指令写在typeDefs中,顺序没关系,但为了结构明确,最好是写在最上方
这里directive定义一个@upper自定义指令,on 用于 字段,也就是单一属性
将@upper指令添加到name后面,以实现数据库返回的用户名通过指令转换为大写
const typeDefs = gql`
directive @upper on FIELD_DEFINITION
type User {
email: String!
username: String! @upper
bio: String
image: String
token: String
}
`
Creating schema directives - Apollo Server - Apollo GraphQL Docs
支持的位置
下表列出了typeDefs中可以使用指令的位置,指定自定义指令出现的位置可以自由组合,通过 | 分隔
| NAME / MAPPERKIND | DESCRIPTION |
|---|---|
SCALARSCALAR_TYPE | The definition of a custom scalar |
OBJECTOBJECT_TYPE | The definition of an object type |
FIELD_DEFINITIONOBJECT_FIELD | The definition of a field within any defined type except an input type (see INPUT_FIELD_DEFINITION) |
ARGUMENT_DEFINITIONARGUMENT | The definition of a field argument |
INTERFACEINTERFACE_TYPE | The definition of an interface |
UNIONUNION_TYPE | The definition of a union |
ENUMENUM_TYPE | The definition of an enum |
ENUM_VALUEENUM_VALUE | The definition of one value within an enum |
INPUT_OBJECTINPUT_OBJECT_TYPE | The definition of an input type |
INPUT_FIELD_DEFINITIONINPUT_OBJECT_FIELD | The definition of a field within an input type |
SCHEMAROOT_OBJECT | The top-level schema object declaration with query, mutation, and/or subscription fields (this declaration is usually omitted) |
定义指令逻辑
只是这样定义和使用,没有逻辑实现显然是不行的,接下来在Schema内定义这个类类实现操作,需要这两个依赖,确认已安装
npm i @graphql-tools/utils
在根目录的Schema.js中添加指令转换器函数
const { makeExecutableSchema } = require('@graphql-tools/schema')
const typeDefs = require('./type-defs')
const resolvers = require('./resolvers')
// 引入这些依赖项
const { mapSchema, getDirective, MapperKind } = require('@graphql-tools/utils')
const { defaultFieldResolver } = require('graphql')
// 添加自定义指令转换器
function upperDirectiveTransformer(schema, directiveName) {
return mapSchema(schema, {
// 对schema中的每个对象执行一次
[MapperKind.OBJECT_FIELD]: (fieldConfig) => {
// 检查这个字段中是否存在传入的这个指令需要执行
let upperDirective = getDirective(schema, fieldConfig, directiveName)
upperDirective = upperDirective && upperDirective[0]
if (upperDirective) {
// 如果存在获取这个字段不带有指令的原始resolver
const { resolve = defaultFieldResolver } = fieldConfig
// Replace the original resolver with a function that *first* calls the original resolver
fieldConfig.resolve = async function (parent, args, context, info) {
// 获取到数据库返回的数据
const result = await resolve(source, args, context, info)
// 判断返回数据是否为字符串类型,如果是则转换为大写,不是则直接返回
if (typeof result === 'string') {
return result.toUpperCase()
}
return result
}
return fieldConfig
}
}
})
}
let schema = makeExecutableSchema({
typeDefs,
resolvers
})
// 转换schema,应用指令逻辑
schema = upperDirectiveTransformer(schema, 'upper');
module.exports = schema
需要注意一个点,官方示例中的代码复制过来会报错
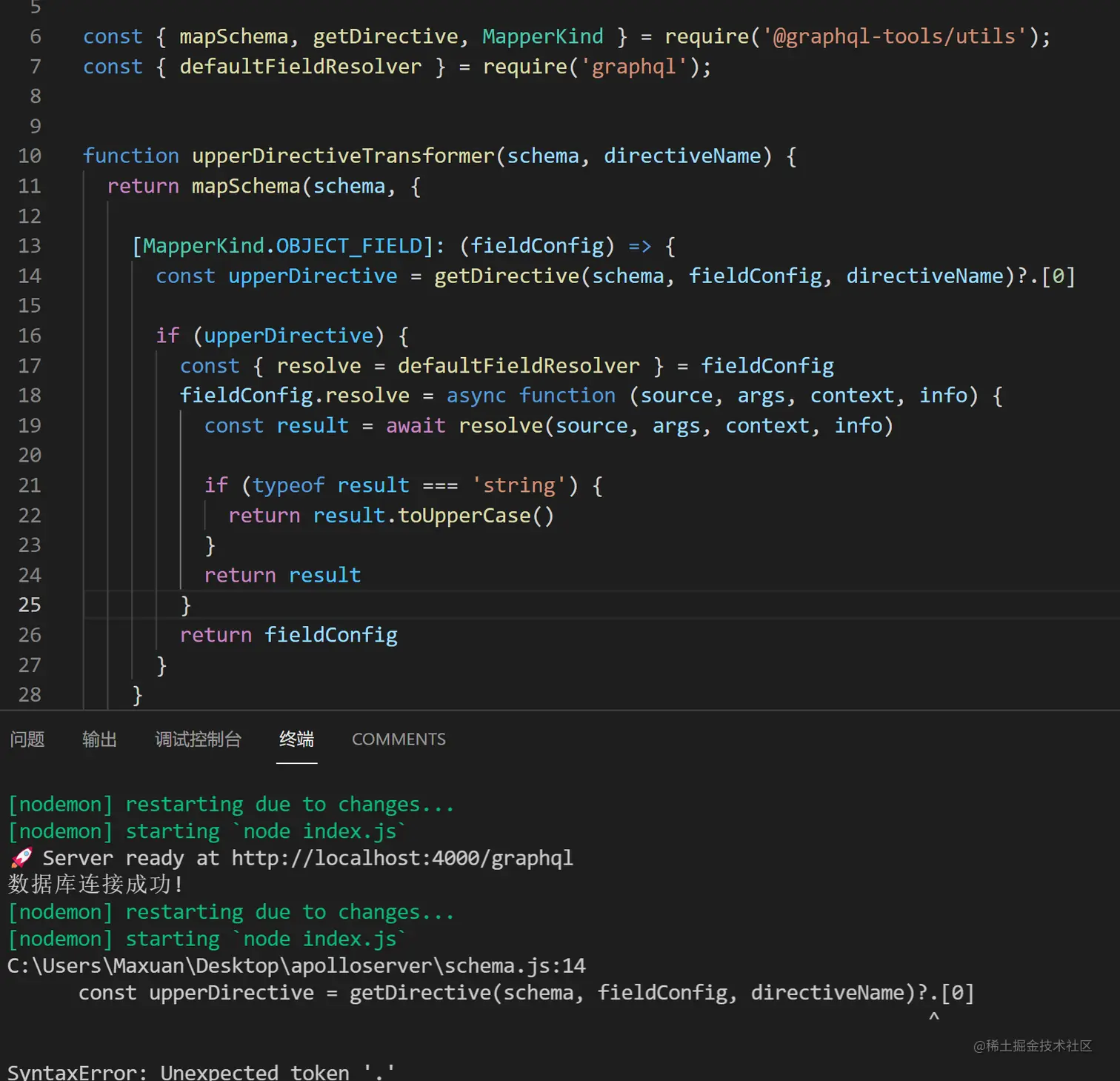
原因是不支持 ?. 这个语法,需要配置


根据这个语法的描述,是可以替换为 a && a.b这种形式的,于是源码就被我改成了下面这样,并且js语法和gql语法都通过了测试
let upperDirective = getDirective(schema, fieldConfig, directiveName) upperDirective = upperDirective && upperDirective[0]另外上方文档的代码还导致了我后面的一处报错
fieldConfig.resolve = async function (source, args, context, info){}他写的是source,改成parent
其他指令例子
Schema directives (graphql-tools.com)
封装auth指令 处理身份认证
声明指令并使用
就像上面的自定义指令示例一样,首先定义一个枚举类型 Role 来提供给 @auth指令,这个Role的参数默认值为 ADMIN,@auth指令可以出现在类似于User这样返回数据类型为OBJECT的类型或者banned这样的单条字段上,为所有User内的字段设置默认访问权限,也可以出现在单个字段上,通过@auth限制用户对特定字段的访问
const typeDefs = gql`
directive @auth on FIELD_DEFINITION
type User{
email: String!
name: String!
bio: String @auth
image: String
token: String
}
`
封装自定义指令转换器
将指令封装到shema-directives/user.js并抛出
const { mapSchema, getDirective, MapperKind } = require('@graphql-tools/utils')
const { defaultFieldResolver } = require('graphql')
const { AuthenticationError } = require("apollo-server-core")
const jwt = require('../util/jwt')
const { jwtSecret } = require('../config/config.default')
// 指令转换器函数整体上不需要变动
function autnDirectiveTransformer(schema, directiveName) {
return mapSchema(schema, {
[MapperKind.OBJECT_FIELD]: (fieldConfig) => {
// 这里更名为authDirective
let authDirective = getDirective(schema, fieldConfig, directiveName)
authDirective = authDirective && authDirective[0]
if (authDirective) {
const { resolve = defaultFieldResolver } = fieldConfig
// 此处返回数据库的数据,接下来进行判断处理
fieldConfig.resolve = async function (parent, args, { token }, info) {
if(!token) {
throw new AuthenticationError('未授权')
}
try {
const decodedData = await jwt.verify(token, jwtSecret)
// 先打印一下测试是否生效
console.log(decodedData);
} catch (error) {
throw new AuthenticationError('未授权')
}
}
return fieldConfig
}
}
})
}
module.exports = autnDirectiveTransformer
应用指令逻辑
引入到schema.js
const { makeExecutableSchema } = require('@graphql-tools/schema')
const typeDefs = require('./type-defs')
const resolvers = require('./resolvers')
// 引入指令转换器模块
const autnDirectiveTransformer = require('./schema-directives/auth')
let schema = makeExecutableSchema({
typeDefs,
resolvers
})
// 转换schema,应用指令逻辑
schema = autnDirectiveTransformer(schema, 'auth');
module.exports = schema
测试是否生效
语句测试,在没有传递token的情况下,返回了错误信息 ”未授权“
重新登录获取token后重新发起请求获取bio,服务器成功返回了bio数据 (前面的笔记传递token时前面加了Token报错未授权们这里去掉了)
说明请求已经走到了@auth指令这里来了
服务器终端打印出了userId和token的发放时间和过期时间
通过userID获取用户数据
找到data-sources/user.js,添加一个通过userId查找数据的方法
findById (userId) {
return this.findOneById(userId)
}
回到指令转换器,继续写逻辑处理部分,再次从context中解构出dataSources,调用dataSources.users下的findById方法,传入token解析出的userId
携带token发起请求,打印一下从数据库获取到的数据
fieldConfig.resolve = async function (parent, args, { token, dataSources }, info) {
if(!token) {
throw new AuthenticationError('未授权')
}
try {
const decodedData = await jwt.verify(token, jwtSecret)
const user = await dataSources.users.findById(decodedData.userId)
console.log(user);
} catch (error) {
throw new AuthenticationError('未授权!')
}
}
因为如果从形参解构出user,就不能把对user的更改返回到context,所以 需要从内部解构出需要的对象,通过context.user来更新user
这里将返回resolver( parent, args, context, info) 放在了外面,原因是,只要try catch内的代码执行没有错,下面的返回resolver就一定会执行到,避免了resolver内部出错导致的返回数据失败
fieldConfig.resolve = async function (parent, args, context, info) {
const { token, dataSources } = context
if(!token) {
throw new AuthenticationError('未授权')
}
try {
const decodedData = await jwt.verify(token, jwtSecret)
const user = await dataSources.users.findById(decodedData.userId)
// 把当前登录用户挂载到 context 对象中,给后续的resolver使用
context.user = user
} catch (error) {
throw new AuthenticationError('未授权!')
}
return await resolve( parent, args, context, info)
}
return fieldConfig
currentUser应用
回到身份认证方式介绍上方的 resolvers接收token,之前需要在这里进行token验证的操作,现在只需要在typeDefs内的 currentUser 后加上@auth,就可以通过身份认证来获取数据了
type Query {
currentUser: User @auth
}
resolvers/index.js,返回user
const resolvers = {
Query: {
currentUser (parent, args, context, info) {
return context.user
}
}
}
测试没有添加 @auth
添加@auth后
更新登录用户信息
typeDefs
既然是增删改操作,那首先是在 typeDefs 中的 Mutation 内声明 updataUser,传入user,类型为 updataUserInput,返回类型同样为UserPayLoad,并且需要权限验证(updataUserInput的类型与文档有差别,email是作为账号使用的为啥可以修改?换成了username并且添加password修改,注意这是个input类型)
input updataUserInput {
username: String
password: String
image: String
bio: String
}
type Mutation {
login(user: LoginInput): UserPayload
createUser(user: CreateUserInput): UserPayload
updataUser(user: updataUserInput): UserPayLoad @auth
}
resolvers
接下来是写处理器,添加一个usdataUser方法,并从请求体args中解构出user,从数据库返回的context中解构出user和调用数据库操作方法的dataSources,因为user同名,这里对请求体user重命名了形参
判断是否存在密码修改,并进行加密
调用下方data-sources将要声明的数据库操作方法并传入参数
因为添加了@auth,所以任何请求都会先进入指令流程,这个@auth会拿到token解密并通过userID获取到包含user._id的user完整数据并放入context,接下来就可以在后续的处理获取到user._id了
async updataUser (parent, { user: userInput }, { user, dataSources }) {
// 如果修改的数据存在密码,就将密码加密再存储到userInput
if(userInput.password) {
userInput.password = md5(userInput.password)
}
// 操作数据库并接收返回数据
const res = await dataSources.users.updataUser(user._id, userInput)
// 返回结果包裹在user对象内
return {
user: res
}
}
data-sources
打开data-sources/user.js添加操作数据库的方法
updataUser (userId, data) {
// 操作数据库并接收返回数据
return this.model.findByIdAndUpdate(
{ _id: userId}, // 查询条件
data, // 传入更改的数据
{
new: true // 默认false返回更改之前的数据,配置为true返回更新之后的数据
}
)
}
测试接口
下方传入需要修改的数据,上方为请求服务器返回的数据,并且携带了token发起请求,返回数据为更新后的数据
创建文章 设计schema
Endpoints | RealWorld (realworld-docs.netlify.app)
接下要做文章的管理,实现对文章的增删改查
typeDefs
首先声明createArticle,接收参数类型article需要用input类型,只有tagList字段不是必须的,返回Article
const typeDefs = gql`
input CreateArticalInput {
title: String!
description: String!
body: String!
tagList: [String!]
}
type Article {
}
type Mutation {
# Artical
createArticle(article: CreateArticleInput): Article
}
`
文章所需信息
因为返回值是包含字一个article内的对象,所以需要用一个Payload包裹,Article下面的author是一个User对象并且多了一个following,将following添加到User类型,author: User 就可以了
创建文章需要author字段,需要在发送请求时验证身份,并连同身份信息一起保存到数据库,所以后面加上@auth
const typeDefs = gql`
type User {
email: String!
username: String!
bio: String @auth
image: String
token: String
following: Boolearn
}
type Article {
_id: String!
slug: String!
title: String!
description: String!
body: String!
tagList: [String!]
createdAt: String!
updatedAt: String!
favorited: Boolearn
favoritesCount: Int
author: User
}
type CreateArticlePayload {
article: Article
}
type Mutation {
# Artical
createArticle(artcle: CreateArticleInput): CreateArticlePayload @auth
}
`
resolvers
resolver内现在都是User的处理器,同Article混在一起不好分辨,接下来对这里进行模块化
将resolvers/index.js更名为user.js,再创建一个article.js,抛出
const resolvers = {
Query: {
},
Mutation: {
createArticle () {
console.log(111);
}
}
}
module.exports = resolvers
schema.js
打开根目录schema.js,分别引入user.js和article.js,以数组形式引入resolvers
const { makeExecutableSchema } = require('@graphql-tools/schema')
const typeDefs = require('./type-defs')
// 模块化引入resolvers
const userRresolvers = require('./resolvers/user')
const articleRresolvers = require('./resolvers/article')
const autnDirectiveTransformer = require('./schema-directives/auth')
let schema = makeExecutableSchema({
typeDefs,
resolvers: [userRresolvers, articleRresolvers] // 以数组的形式引入
})
schema = autnDirectiveTransformer(schema, 'auth');
module.exports = schema
或者也可以在resolvers/index.js内拼合成数组导入schema.js
测试语句,成功返回
再测试一下新添加的 createArticle()
服务器终端成功打印了111
createArticle() 功能实现
data-sources/article.js 操作数据库的方法
const { MongoDataSource } = require('apollo-datasource-mongodb')
class Articles extends MongoDataSource {
createArticle (data) {
const article = new this.model(data)
return article.save()
}
}
module.exports = Articles
使用article.js也需要确认一下,在data-sources/index.js配置了这个模块
const dbModel = require('../models')
const Users = require('./user')
const Articles = require('./article')
module.exports = () => {
return {
users: new Users(dbModel.User),
articles: new Articles(dbModel.Article)
}
}
dataSources没问题接下来就可以在resolvers内处理了
async createArticle (parent, {article}, {dataSources}) {
const res = await dataSources.articles.createArticle(article)
return {
article:res
}
}
测试语句,报错提示Article的author是必须的
下面的错误信息指向了mongoose的model.Document,确实,向数据库发送请求需要一个key为author的ID,用来确定是哪个用户创建了文章
回到resolvers/article.js ,因为@auth指令的操作,将验证身份后数据库返回的user放入了context,这里解构出user,并赋值给article.author
async createArticle (parent, {article}, {user, dataSources}) {
article.author = user._id
const res = await dataSources.articles.createArticle(article)
return {
article:res
}
}
再次发送请求,正常返回了文章信息
数据库也成功保存了请求
处理文章中的author
从上面数据库存储的author可以看到,其中保存的是user的_id,并不是请求需要返回的user对象,如果现在请求author的话,会因为读取不到所需要的字段报错
方法一
将@auth指令返回的user赋值给article.author,这个方法仅适用于返回user数据
async createArticle (parent, {article}, {user, dataSources}) {
article.author = user._id
const res = await dataSources.articles.createArticle(article)
res.author = user
return {
article:res
}
}
方法二
使用Mongoose 的 populate() 方法使用_id进行字段映射
data-sources/article.js
createArticle (data) {
const article = new this.model(data)
article.populate('author')
return article.save()
}
这里将数据库article内的author的值id,同author集合内这个id对应数据对象,映射到author: _id 这里,author则作为一个对象被返回的客户端从而完成了请求
Mongoose 的 populate() 可以连表查询,即在另外的集合中引用其文档,Populate() 可以自动替换 document 中的指定字段,替换内容从其他 collection 中获取
创建 Model 的时候,可给该 Model 中关联存储其它集合 _id 的字段设置 ref 选项。ref 选项告诉 Mongoose 在使用 populate() 填充的时候使用哪个 Model
author: { type: Schema.Types.ObjectId, ref: 'User', required: true }ObjectId 、Number 、String 以及 Buffer 都可以作为 refs 使用。 但是最好还是使用 ObjectId
populate(),还有其他可选属性可以传入
Query.populate(path, [select], [model], [match], [options])
path —— 指定要查询的表
select(可选) —— 指定要查询的字段
model(可选) —— 类型:Model,可选,指定关联字段的 model,如果没有指定就会使用Schema的ref。
4.match(可选) —— 类型:Object,可选,指定附加的查询条件。
5.options(可选) —— 类型:Object,可选,指定附加的其他查询选项,如排序以及条数限制等等。
方法三
通过resolver链式结构,分开来写单独解析,这个方法处理,自由度更高一些
const resolvers = {
Query: {
},
Mutation: {
async createArticle (parent, {article}, {user, dataSources}) {
article.author = user._id
const res = await dataSources.articles.createArticle(article)
return {
article:res
}
}
},
Article: {
async author (parent, args, { dataSources }) {
console.log(parent)
const user = await dataSources.users.findById(parent.author)
return user
}
}
}
module.exports = resolvers
Article内的author字段由这个resolver来解析,通过打印parent,可以看到这个就是数据库返回的article,再通过parent.author的id获取到user集合的用户信息并返回给author,再由createArticle将全部数据返回给客户端
以上三个方法测试,均返回了正确的数据
获取所有文章
typeDefs
获取所有文章的数据结构包括一个article成员的数组articles,和一个articlesCount的数字,这里暂时返回全部内容,之后再处理返回文章列表和分页
添加查询类型
type ArticlesPayload {
articles: [Article!]
articlesCount: Int!
}
type Query {
articles: ArticlesPayload
}
data-sources
声明操作数据库的方法
const { MongoDataSource } = require('apollo-datasource-mongodb')
class Articles extends MongoDataSource {
createArticle (data) {
const article = new this.model(data)
return article.save()
}
getArticles () {
return this.model.find()
}
getCount () {
return this.model.countDocuments()
}
}
module.exports = Articles
resolvers
在resolvers内调用data-sources内操作数据库的方法,因为获取全部文章和文章数量的操作不存在联系,所以可以并行执行,可以通过Promise.all()让请求并发执行,返回的是一个数组,再解构出来return一个包含articles和 articlesCount的对象
const resolvers = {
Query: {
async articles (parent, {}, { dataSources }) {
const [articles, articlesCount] = await Promise.all([
dataSources.articles.getArticles(),
dataSources.articles.getCount()
])
return {
articles,
articlesCount
}
}
}
//...
}
测试获取全部文章和文章总数
分页获取文章列表
分页功能从参数入手就可以了,传 页码 和 每页大小 两个参数进行分页
typeDefs
给文章查询添加两个参数,offset 类型为Int,默认值为0,表示偏移0条数据,limit从当前位置往后取多少条,Int类型,默认每页6条数据
type Query {
currentUser: User @auth
articles(offset: Int = 0, limit: Int = 6): ArticlesPayload
}
resolvers
把参数解构出来
async articles (parent, { offset, limit }, { dataSources }) {
console.log({ offset, limit })
const [articles, articlesCount] = await Promise.all([
dataSources.articles.getArticles(offset, limit),
dataSources.articles.getCount()
])
return {
articles,
articlesCount
}
}
先传参,测试语句打印一下
服务器终端成功打印参数
data-sources
接收参数并调用方法对数据库进行查询
getArticles (offset, limit) {
return this.model.find().skip(offset).limit(limit)
}
使用resolver链来提高查询性能
GraphQL一大好处就是一个请求可以选择只返回部分数据,但是这个操作在服务端执行,数据库是要全查一遍的,只是返回给客户端的数据被过滤了
上面获取文章列表和总数的请求,如果想只查其中一个,不想要在服务端执行查询另一个的操作,就不能像之前那样写了
需要通过resolver链来分开处理
对于article来说,只返回一个空对象,让它可以继续返回内容,这里不能没有,否则就不会继续执行resolver链了
typeDefs内articles查询需要返回一个ArticlePayload,内部有两个字段,将这两个字段的逻辑分开来写,并且打印一下请求状态
注意,这里需要将请求参数放入return,才能通过子类的parent解构得到offset和limit参数
const resolvers = {
Query: {
async articles (parent, {offset, limit}) {
return {offset, limit}
}
},
ArticlesPayload: {
async articles({offset, limit}, args, { dataSources }) {
console.log('articles查询')
const articles = await dataSources.articles.getArticles(offset, limit)
return articles
},
async articlesCount (parent, args, { dataSources }) {
console.log('articlesCount查询')
const count = await dataSources.articles.getCount()
return count
}
}
}
module.exports = resolvers
两个都查询,正确的返回了数据
服务器终端打印了两个请求
接下来只查询文章总数,并且不传入参数
服务器终端打印了articlesCount查询,表示服务器并没有执行articles的查询操作
这样就利用resolver链的优化,避免了做过多没有用的IO操作,只查询其中一个的时候提高程序的性能
