前言
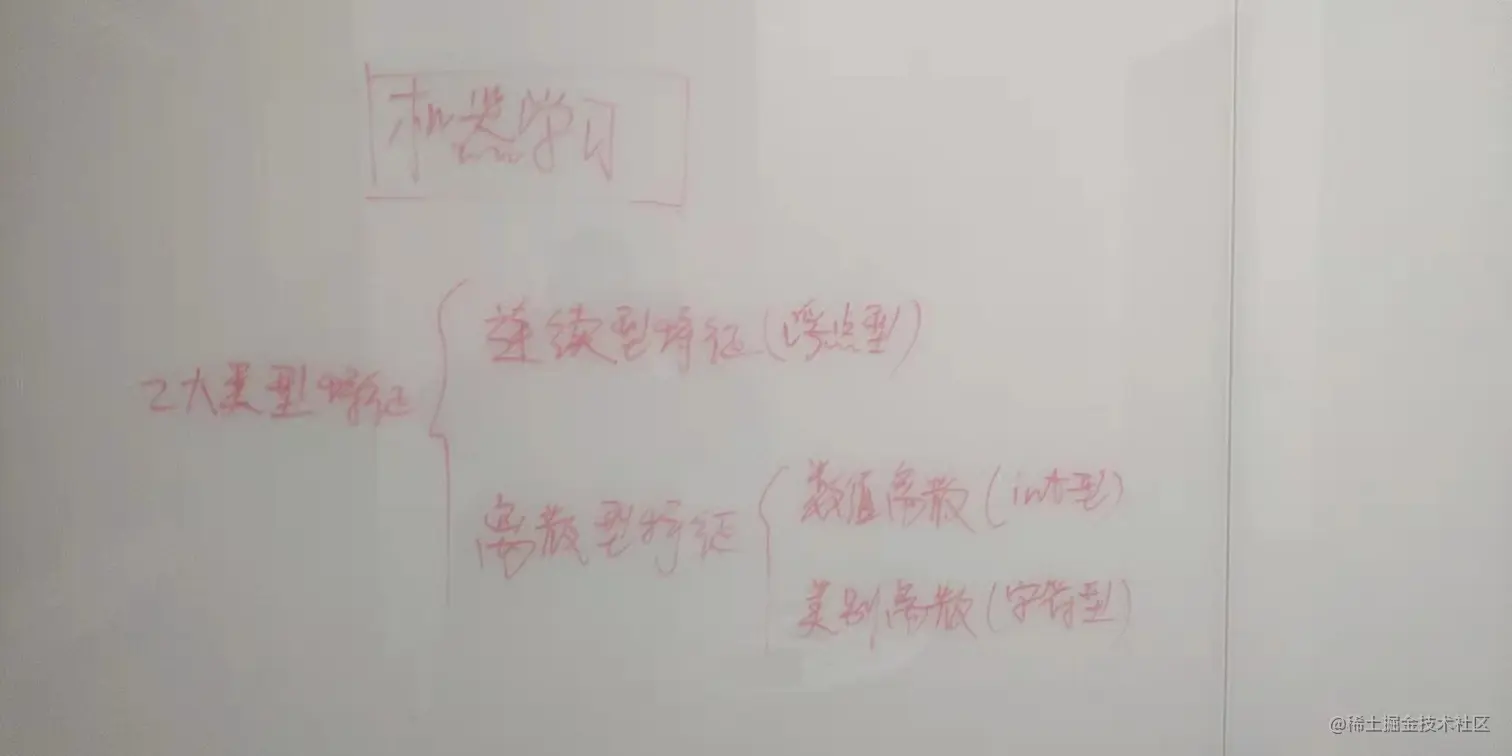
在机器学习中, 一般特征可以分为两类特征:连续型特征和离散型特征
而离散型特征既有是数值型的,也有是类别型特征(也可以称为字符型的,正好和前面的数值型相对应),
比如说性别,是男还是女;职业,可以是程序员,产品经理,教师等等。
离散型特征中,又有有序的和无序的。
比如城市这个特征,它的特征值包括北京,上海,天津,大连,成都....等,这是无序的。
但是比如收入水平这个特征,他的特征值有高收入,中等收入,低收入,这是有序的。
连续型特征(浮点型)
例子:[4654.1313, 11, 0, 4564654, …]
对于连续特征,在拿到数据后,需要进行两步常规操作:
归一化,将数据缩放到线性放缩到[-1,1]间;
标准化,将数据放缩到均值为0,方差为1。
注:
基于`参数`的模型或基于`距离`的模型,都是要进行特征的归一化。
基于`树`的模型是不需要进行特征的归一化,例如随机森林,bagging 和 boosting等。
离散型特征
离散型特征当中,既有数值型的(int型),也有类别型的(字符型)。
例子:[‘AskReddit’, ‘Jokes’, ‘politics’, ‘explainlikeimfive’, ‘gaming’]
['男','女']
['A','B','AB','O']
['高收入','中等收入','低收入']
对于离散类别型特征基本就是按照one-hot(独热)编码,
该离散类别型特征有多少取值,就用多少维来表示该特征,或者用其他类型的编码。


