

GO-
极客大学-go进阶训练营
缓存选型
缓存模式
缓存技巧
References
缓存选型 - memcache
memcache 提供简单的 kv cache 存储,value 大小不超过1mb。
我使用 memcache 作为大文本或者简单的 kv结构使用。
memcache 使用了slab 方式做内存管理,存在一定的浪费,如果大量接近的 item,建议调整 memcache 参数来优化每一个 slab 增长的 ratio、可以通过设置 slab_automove & slab_reassign 开启memcache 的动态/手动 move slab,防止某些 slab 热点导致内存足够的情况下引发 LRU。
大部分情况下,简单 KV 推荐使用 Memcache,吞吐和相应都足够好。
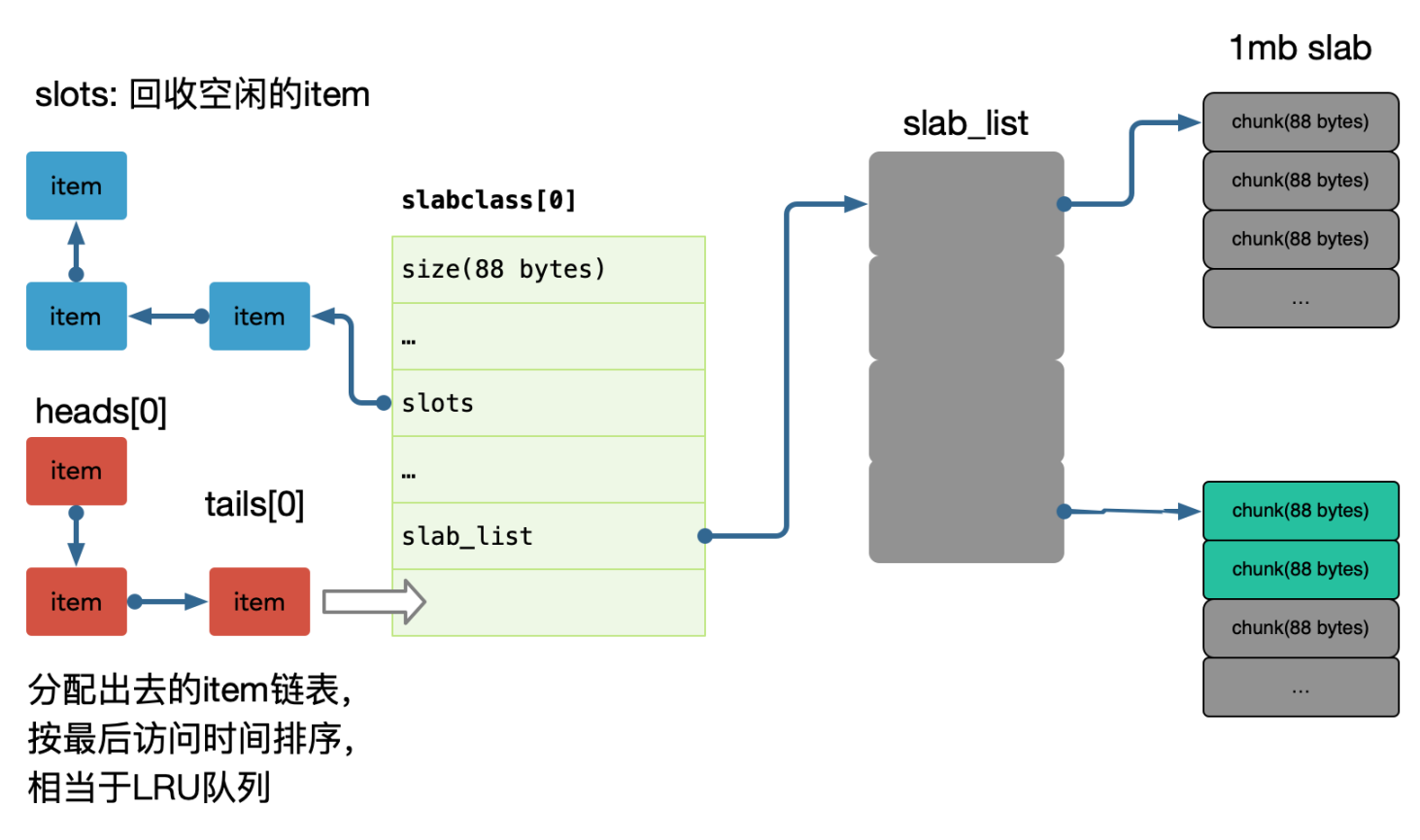
 每个 slab 包含若干大小为1M的内存页,这些内存又被分割成多个 chunk,每个 chunk存储一个 item;
在 memcache 启动初始化时,每个 slab 都预分配一个 1M 的内存页,由slabs_preallocate 完成(也可将相应代码注释掉关闭预分配功能)。
chunk 的增长因子由 -f 指定,默认1.25,起始大小为48字节。
内存池有很多种设计,可以参考下: nginx ngx_pool_t,tcmalloc 的设计等等。
每个 slab 包含若干大小为1M的内存页,这些内存又被分割成多个 chunk,每个 chunk存储一个 item;
在 memcache 启动初始化时,每个 slab 都预分配一个 1M 的内存页,由slabs_preallocate 完成(也可将相应代码注释掉关闭预分配功能)。
chunk 的增长因子由 -f 指定,默认1.25,起始大小为48字节。
内存池有很多种设计,可以参考下: nginx ngx_pool_t,tcmalloc 的设计等等。
缓存选型 - redis
redis 有丰富的数据类型,支持增量方式的修改部分数据,比如排行榜,集合,数组等。
比较常用的方式是使用 redis 作为数据索引,比如评论的列表 ID,播放历史的列表 ID 集合,我们的关系链列表 ID。
redis 因为没有使用内存池,所以是存在一定的内存碎片的,一般会使用 jemalloc 来优化内存分配,需要编译时候使用 jemalloc 库代替 glib 的 malloc 使用。

缓存选型 - redis vs memcache
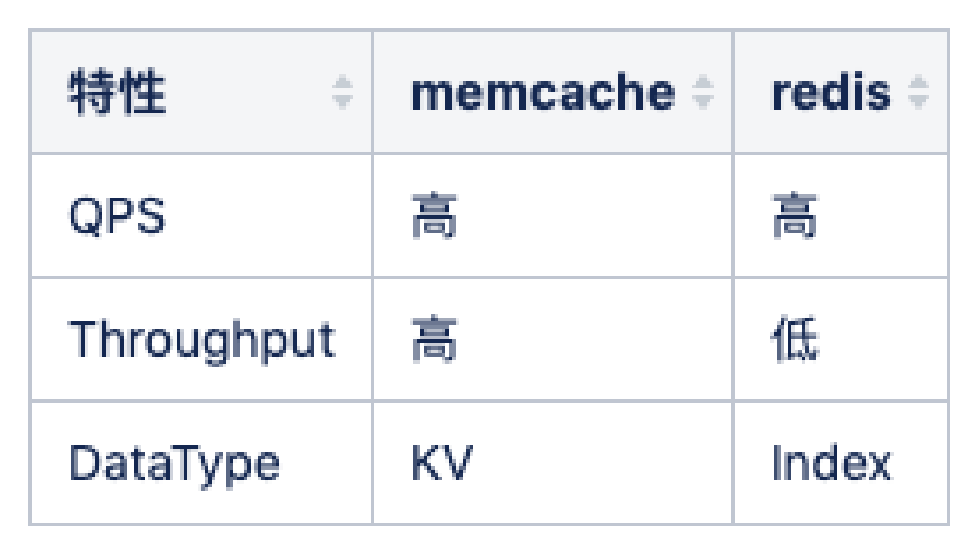
Redis 和 Memcache 最大的区别其实是 redis 单线程(新版本双线程),memcache 多线程,所以 QPS 可能两者差异不大,但是吞吐会有很大的差别,比如大数据 value 返回的时候,redis qps 会抖动下降的的很厉害,因为单线程工作,其他查询进不来(新版本有不少的改善)。
所以建议纯 kv 都走 memcache,比如我们的关系链服务中用了 hashs 存储双向关系,但是我们也会使用 memcache 档一层来避免hgetall 导致的吞吐下降问题。
我们系统中多次使用 memcache + redis 双缓存设计。
缓存选型 - Proxy
早期使用 twemproxy 作为缓存代理,但是在使用上有如下一些痛点:
单进程单线程模型和 redis 类似,在处理一些大 key 的时候可能出现 io 瓶颈;
二次开发成本难度高,难以于公司运维平台进行深度集成;
不支持自动伸缩,不支持 autorebalance 增删节点需要重启才能生效;
运维不友好,没有控制面板;
业界开源的的其他代理工具:
codis: 只支持 redis 协议,且需要使用 patch版本的 redis;
mcrouter: 只支持 memcache 协议,C 开发,与运维集成开发难度高;


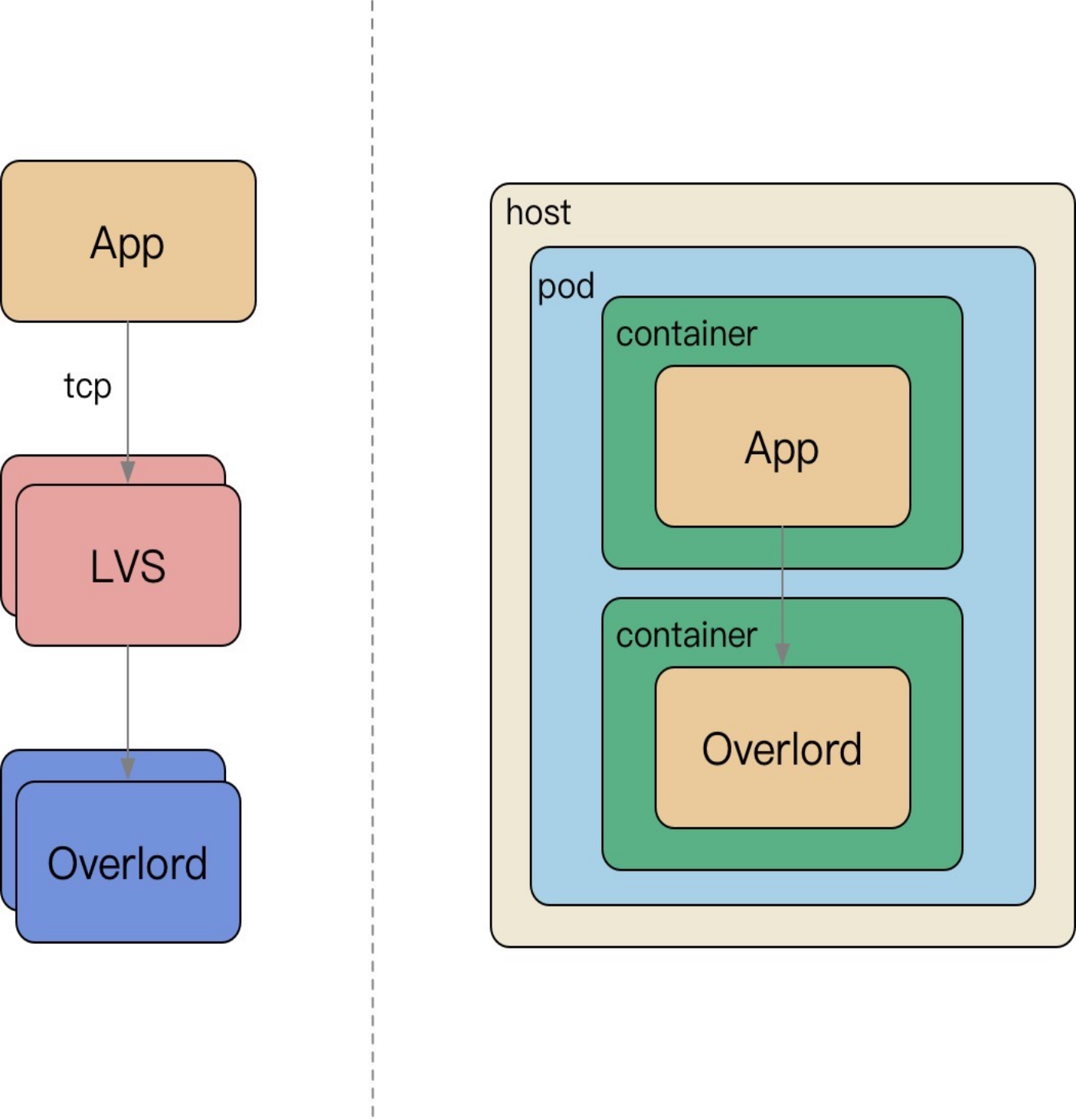
从集中式访问缓存到 Sidecar 访问缓存:
微服务强调去中心化;
LVS 运维困难,容易流量热点,随下游扩容而扩容,连接不均衡等问题;
Sidecar 伴生容器随 App 容器启动而启动,配置简化;
缓存选型 - 一致性Hash
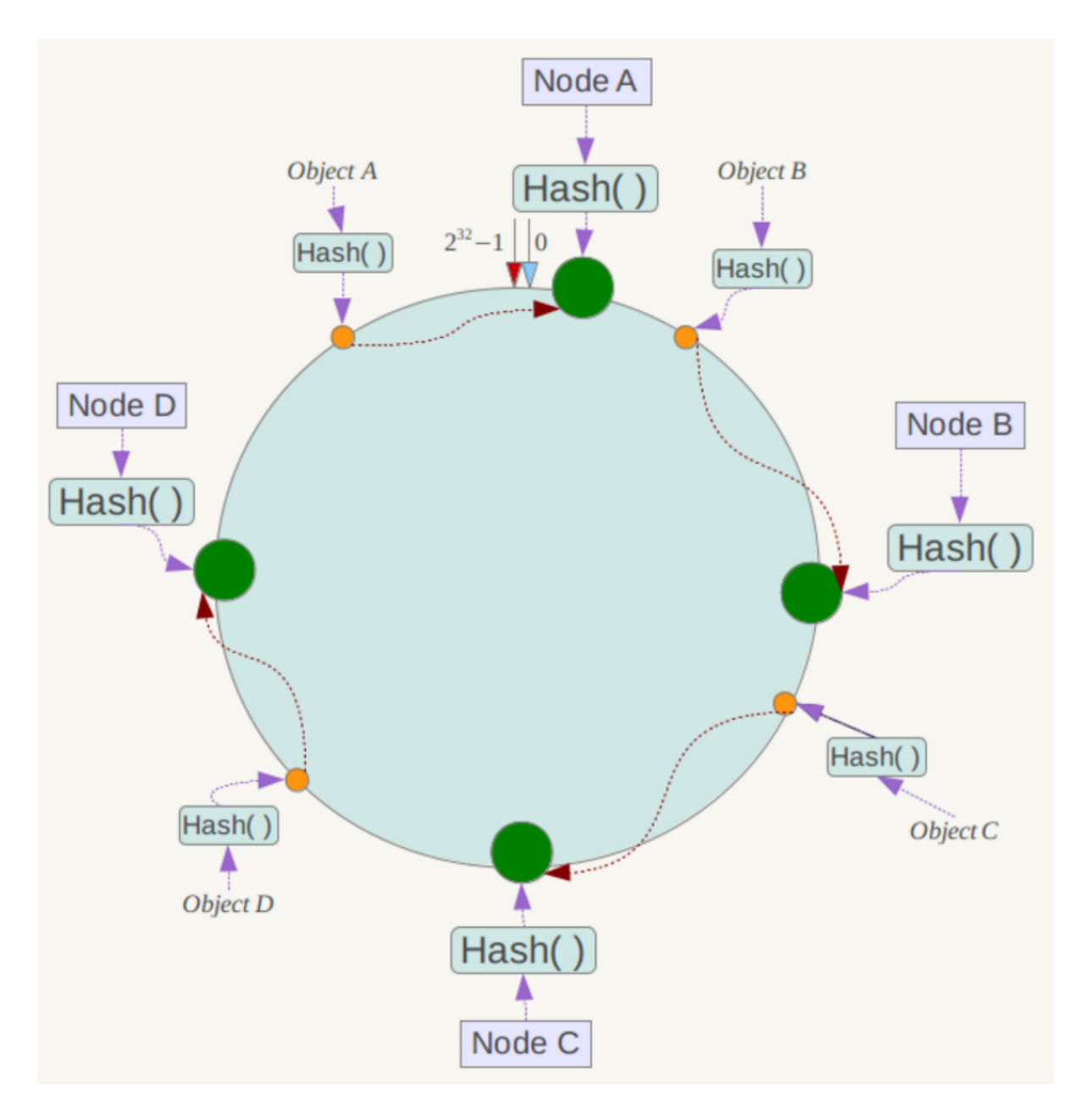
一致性 hash 是将数据按照特征值映射到一个首尾相接的 hash 环上,同时也将节点(按照 IP 地址或者机器名 hash)映射到这个环上。
对于数据,从数据在环上的位置开始,顺时针找到的第一个节点即为数据的存储节点。
余数分布式算法由于保存键的服务器会发生巨大变化而影响缓存的命中率,但Consistent Hashing 中,只有在园(continuum)上增加服务器的地点逆时针方向的第一台服务器上的键会受到影响。
 平衡性(Balance):尽可能分布到所有的缓冲中去
单调性(Monotonicity):单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲区加入到系统中,那么哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲区中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
分散性(Spread):相同内容被存储到不同缓冲中去,降低了系统存储的效率,需要尽量降低分散性。
负载(Load):哈希算法应能够尽量降低缓冲的负荷。
平滑性(Smoothness):缓存服务器的数目平滑改变和缓存对象的平滑改变是一
平衡性(Balance):尽可能分布到所有的缓冲中去
单调性(Monotonicity):单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲区加入到系统中,那么哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲区中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
分散性(Spread):相同内容被存储到不同缓冲中去,降低了系统存储的效率,需要尽量降低分散性。
负载(Load):哈希算法应能够尽量降低缓冲的负荷。
平滑性(Smoothness):缓存服务器的数目平滑改变和缓存对象的平滑改变是一
CML46679910
一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题。 此时必然造成大量数据集中到 Node A 上,而只有极少量会定位到 Node B 上。为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。
