


提出的问题
作者首先指出LiDAR帧其实不是严格意义上的3D结构,而是一个2.5D的结构。因为LiDAR通常只能获得目标靠近传感器那部分的结构特征,远离传感器部分的结构通常因为遮挡难以获得。作者将这个问题称为shape miss.作者在引言中回答了关于shape miss的两个重要问题:
- 点云中造成shape miss的主要原因是什么。
- 在三维目标检测中shape miss带来的影响。
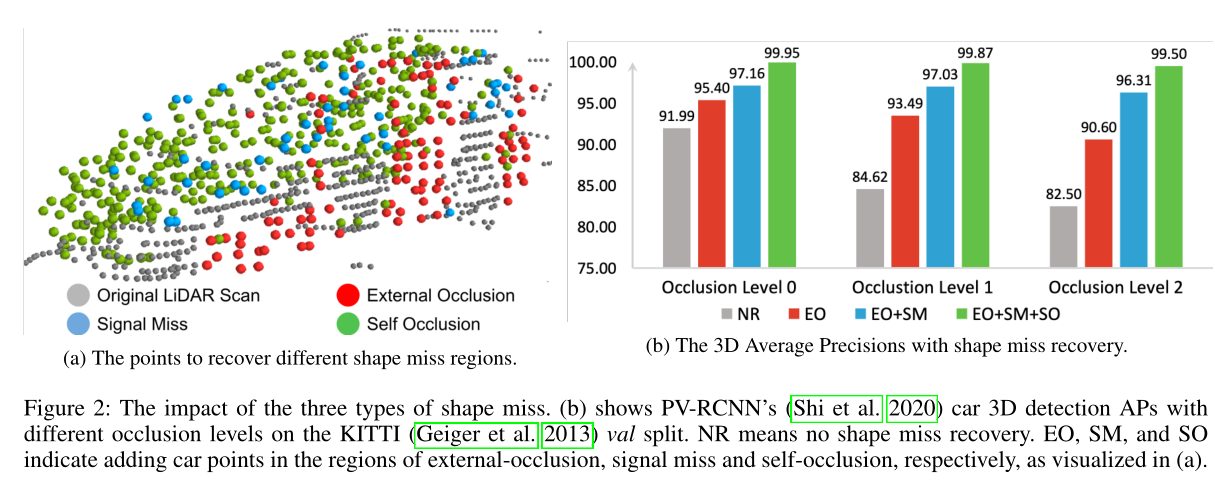
造成shape miss主要由三个原因:
- 外部遮挡。前方物体挡住了后面的物体,使得传感器难以感知到后面的物体。
- 信号丢失。由于目标的材质或者传感器的原因,一部分传感器信号丢失,使得传感器难以感知这个区域
- 自身遮挡。物体自身的靠近传感器的部分遮挡住了远离传感器的部分。
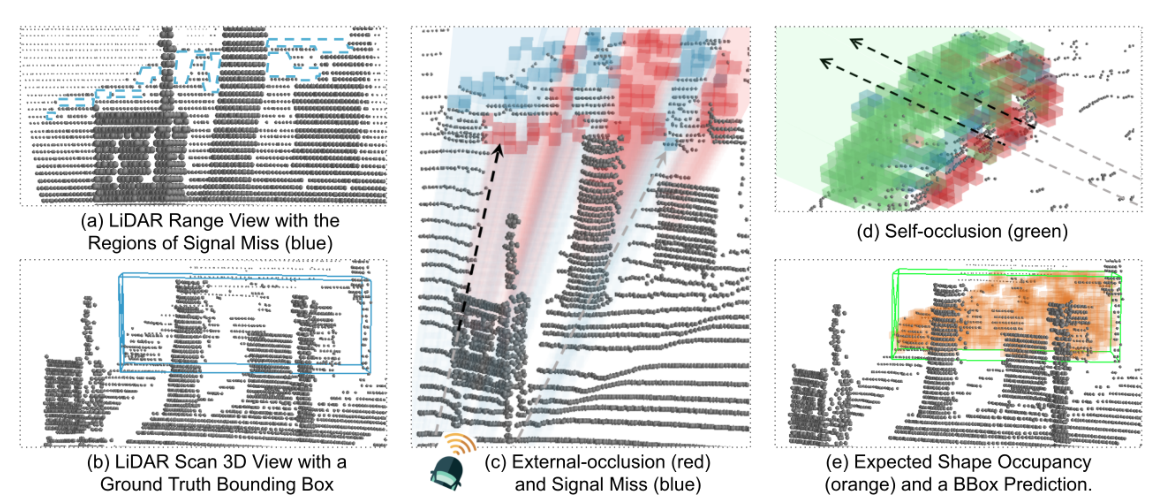
shape miss对三维目标检测带来的影响:
方法概述
表示预测的边界框的中心点,表示的是边界框的维度,表示的是能够观测到的目标的形状,表示被遮挡的目标的形状。表示的是检测器的参数,表示的是点云。
常见的三维目标检测器的目标是:
对于一些结构感知的网络,他们还加入了对于数据的监督。所以上述式子可以写为:
但是,目前还没有研究考虑完整的目标形状,其中,完整的目标形状可以分为两部分,一部分是可以观察到的目标形状,一部分是被遮挡的目标形状。可记为。BtcNet通过预测感兴趣区域的形状占用来显式的利用完整的目标形状。然后,Btc网络根据估计的物体占用概率进行目标检测。优化后的目标检测流程如下所示:
由此可以简单概括一下Btc网络的总体流程:
- 首先需要区分出那些是被遮挡的区域和信号丢失的区域,然后使用一个网络来生成形状占用的概率。
- 使用一个三维骨干网络来提取特征,生成的特征被送入RPN网络来生成3Dproposal,稀疏张量被拼接到特征图上。
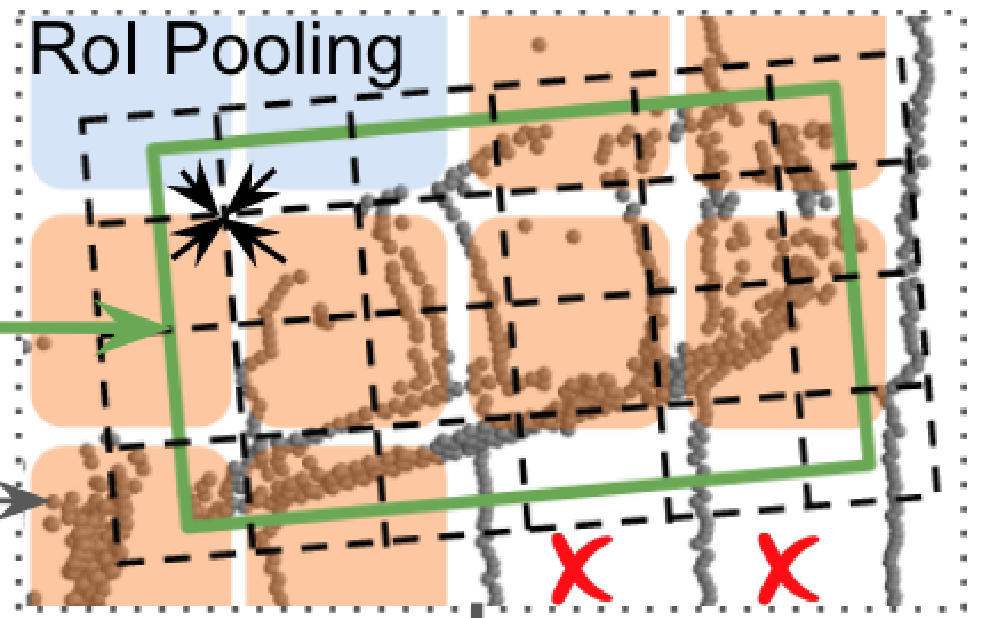
- 然后BtcNet使用proposal refinement。局部特征是由和多尺度的特征图构成的。对于每一个proposal,我们构建覆盖提案框的局部网格。BtcDet将局部几何特征pool到局部网格上,聚合网格特征,并生成最终的边界框预测。
学习遮挡的形状
对于基准框中目标形状的近似
遮挡和信号缺失的问题使得我们不能获得关于基准框中目标的完整的形状信息。因此作者利用如下两个假设来近似目标的完整形状信息,两个假设分别是:
- 大多数前景对象类似于数量有限的形状原型,例如行人有几种固定的体型。
- 前景对象,特别是车辆和骑自行车者,大致对称。
对此,作者提出了一个启发式的函数,。他的作用是评价一个目标B是否覆盖了目标A的大部分,以及是否提供点能够填充目标A中缺失的部分。为了能够近似A的完整形状,我们选择了三个得分最高的目标。因此,最终近似的完整目标就是由A的原始的点和三个的点组合而成。其中,目标A表示的是当前场景中被遮挡的目标,B则是来自训练集中相同类别的目标。
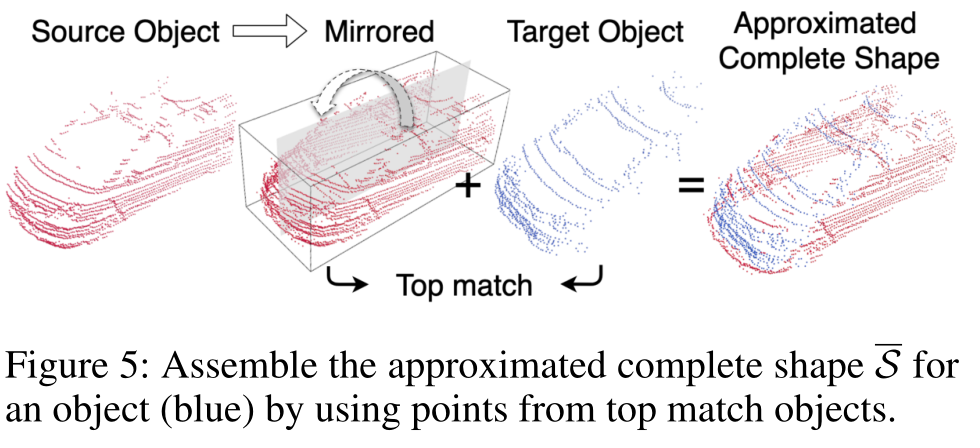
在有了上述近似的完整目标形状之后,通过对比原有的目标形状,我们就能够分辨出被遮挡的区域和信号缺失的区域。
在球面坐标系中辨别
在现实世界的传感器中,在深度图的四面体截锥中最多存在一个点,当激光的一个点被停止时,该点后面的的所有区域都被遮挡住了。因此,为了能够更好的辨别出被遮挡的区域,作者提出了使用球形网格来对点云进行体素化。这样的话,位于任何一个点后面的球面坐标下的体素都是被遮挡的体素。因此,被遮挡的区域包括非空的球形体素和位于这些体素后面的空的体素。

对于信号缺失的区域,作者使用在深度图中,寻找位于有雷达信号和没有雷达信号的边界构成的像素,然后将其投影到球形体素中构成的。

至此,我们已经能够在点云场景中分辨哪些是被遮挡的区域,哪些是信号缺失的区域。此外,我们还有近似的完整的目标形状,这样的话我们就可以来训练网络了。首先需要给每个球形体素划分一个标签。
创建训练目标
在被遮挡区域和信号丢失区域,我们需要预测一个目标覆盖的概率。作者将[2.1节](# 对于基准框中目标形状的近似)中生成的对于基准框的近似放到球形体素中,含有的球形体素的设置为1,其余的为0。
注: 上述过程只针对。
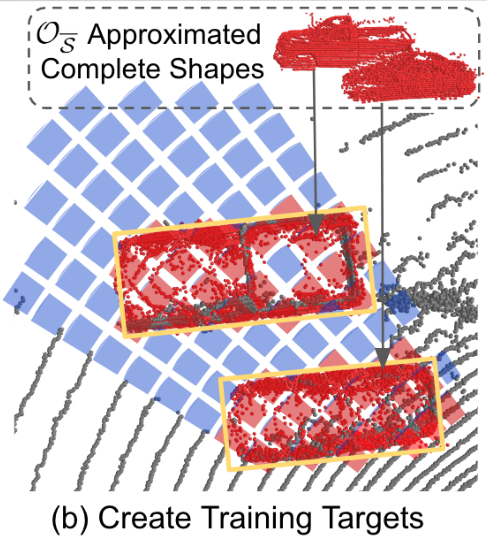
上图中,红色部分的球形体素的为1,蓝色为0.
作者解释了使用生成占用概率相比生成点有两个方面的优势:
- 有多个目标嵌入构成,通过借用的点来近似的目标的形状是不精确的,不同目标的点云密度也是不一致的。这些问题可以通过离散化来解决。
- 能够避免生成点云的合理性问题。
生成形状占用
将区域中,将平均的方法编码非空的球形体素。就是使用位于球形体素的点的来代表这个体素的特征,然后将这些特征送入位置占用生成网络中。这部分网络包含两个下采样的稀疏卷积和上采样的反卷积。其作用机制类似于笛卡尔坐标系中的稀疏卷积。占用概率使用交叉熵损失来监督。
位置占用概率的结合
由于是在球形坐标系中生成的。为了能够更好的方便目标检测,将转化到笛卡尔坐标系中,然后使用一个三维骨干网络来提取特征。由于一个笛卡尔体素能够对应多个球形坐标系,作者选择位于这个笛卡尔体素中的最大的来作为这个体素的概率。然后对这些体素的与原始的饿体素相结合,此外,还使用最大池化与多尺度的原始的体素特征进行结合。然后RPN网络生成proposal。
遮挡感知的proposal refine
作者在proposal refine过程中也引入了来进一步融合这个特征。此外,作者还是引入了一个局部特征图。作者分析了在proposal refine中引入的两个优点:
- 仅含有被遮挡区域和信号缺失区域的概率,因为可以在边界框回归的过程中避免位于被遮挡区域和信号缺失区域以外的其他区域。例如下图中的红色×区域。
- 估计的占用率表明存在未观察到的物体的形状,特别是具有高,例如下图中的橙色区域、
结果
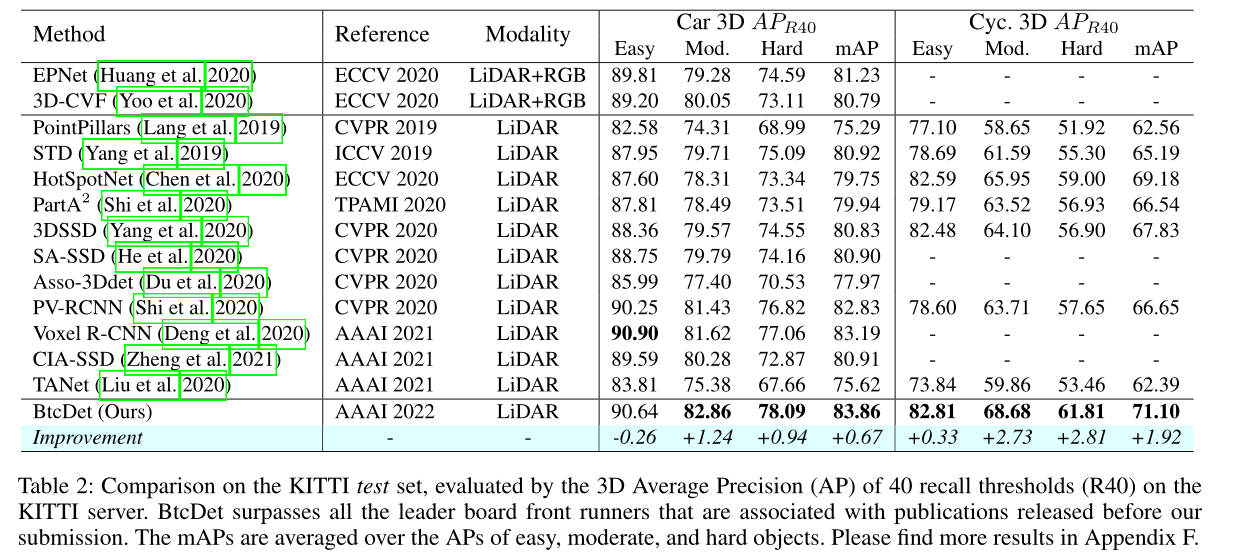
上表展示的是本文在kitti 测试集上取得的结果,从表中可以看出,在中等和难得这两个等级得目标上,作者都取得了很大得进步。这也说明了作者对于shape miss这个问题解决得有效性。因为正是这些mod和hard得目标可能面临更加严重的shape miss问题。
