title:CBML: A Cluster-based Meta-learning Model for Session-based Recommendation
link:dl.acm.org/doi/pdf/10.…
from:CIKM 2021
PS:喜欢的小伙伴记得三连哦,感谢支持
更多内容可以关注公众号:秋枫学习笔记
1. 导读
本文这主要是用于会话推荐的推荐方法,该方法主要针对冷启动方面,提出了对应的解决方式。主要包含两个方面,分别是基于自注意力转换模式学习和基于聚类的元学习。自注意力部分还是集中在挖掘序列之间的关系的部分,缓解冷启动问题还是在元学习部分。
考虑聚类,加入冷启动的商品被划分到了某一个聚类当中,那么我们就可以采用这个聚类中的信息来促进冷启动商品的预测,主要是这样的思想,具体见4.3。
2. 问题定义
去重后的商品集合为V={v1,...,v∣V∣},匿名会话集合为U={u1,...,u∣U∣},每个会话里包含了一组点击序列ui={x1,...,xm},按时间排序,其中xt∈V表示t时间点击的商品。会话推荐就是基于序列ui预测xm+1可能的商品,从所有商品中,选出预测概率top-n的。
3. 元学习设置
把会话看成一个任务。将会话集合划分为训练集Ttrain和测试集Ttest,对于每个序列ui={x1,...,xm}∈Ttrain∪Ttest,生成m-2个子序列如下,这些作为支持集Dutrain,原序列作为查询集Dutest
({x1},x2),({x1,x2},x3),...,({x1,...,xm−2},xm−1)
4. 方法
4.1 概览
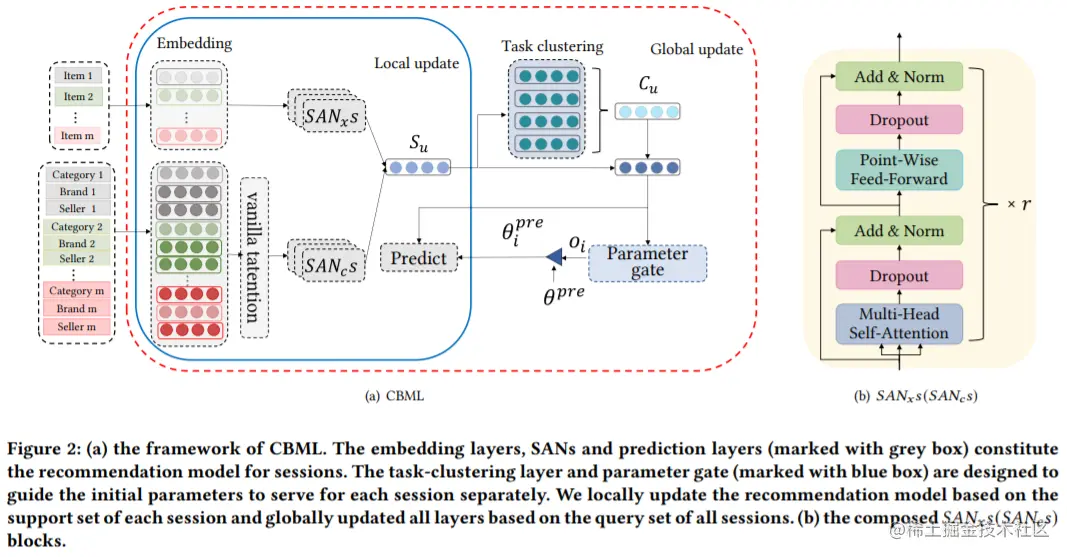 如图所示为模型的整理流程,首先,IF-SAN集成了一个基于商品的自注意力块和一个基于特征的自注意力块来捕获在商品方面和特征方面的会话的转换模式,以获得用户更细粒度的顺序意图;针对冷启动,利用元学习为模型提供更好的初始参数。
如图所示为模型的整理流程,首先,IF-SAN集成了一个基于商品的自注意力块和一个基于特征的自注意力块来捕获在商品方面和特征方面的会话的转换模式,以获得用户更细粒度的顺序意图;针对冷启动,利用元学习为模型提供更好的初始参数。
4.2 序列推荐模型
本文所提的IF-SAN包含:商品级和特征级的embedding层,包含参数θe;商品级自注意力块和特征级自注意力块,参数θs,预测层,参数θpre。
4.2.1 embedding层
用户序列u={x1,...,xn},n是预先设置好的,如果序列长度小于n,则用0填充。然后look-up层将向量转换为embeddingexi。
对于商品的属性,采用同样的方式对得到属性的embedding,ai={vec(ri),vec(bi),vec(li)},他们分别表示商品的类型,品牌和卖家的稠密表征。
由于不同属性对最终的决策用不同的影响,因此此处作者采用vanilla注意力机制,求其加权和,公式如下,
αi=softmax(Wfai+bf)
eai=αiai
4.2.2基于特征/商品的自注意力层
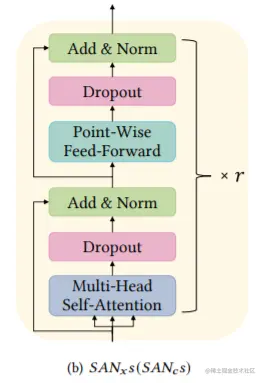 用自注意力机制挖掘特征-特征/商品-商品的转换模式,商品和特征的这两个模块计算方式是一样的,只是输入不一样,这里所说的特征就是商品的属性表征。如图所示为其计算流程,可以发现和transformer的编码层有点类似。具体这里不做过多介绍,看图就一目了然了。
为了捕获用户的长期兴趣和短期兴趣,将多层SAN后得到的输出Fual和最后一个非0的特征表征eam(商品部分也一样)按比例结合得到最终的表征Sual,其中w为可学习参数。
Sual=waFual+(1−wa)eam
用自注意力机制挖掘特征-特征/商品-商品的转换模式,商品和特征的这两个模块计算方式是一样的,只是输入不一样,这里所说的特征就是商品的属性表征。如图所示为其计算流程,可以发现和transformer的编码层有点类似。具体这里不做过多介绍,看图就一目了然了。
为了捕获用户的长期兴趣和短期兴趣,将多层SAN后得到的输出Fual和最后一个非0的特征表征eam(商品部分也一样)按比例结合得到最终的表征Sual,其中w为可学习参数。
Sual=waFual+(1−wa)eam
4.2.3 预测层
将商品和特征得到的最后表征Suxl,Sual拼接得到Su∈R2d,经过FC与需要判断的商品的embeddingevi做点积计算分数。
y^ui=FCθpre(Su)eviT
4.3 基于聚类的元学习优化
这部分主要是用元学习和参数ϕ(这里包括后续的g,w等)来缓解冷启动问题,主要包含两部分:任务聚类和聚类感知的参数门。
- 前者利用软聚类方法在训练会话中生成簇,由于相似的用户具有相似的偏好,表明了密切相关会话之间的泛化,每个会话都可以获得一个聚类增强表示,其中包含会话被归类到的集群的共享特征。
- 后者将全局共享参数的初始化引导到每个聚类,使得初始化可以为属于该集群的所有会话服务。
4.3.1 任务聚类
尽管已经存在针对推荐问题的元学习方法和聚类方法,但没有人将这两种方法的优点结合起来。会话中的冷用户没有足够的记录来获得足够的偏好。而聚类方法可以帮助在相似的会话之间迁移共享知识,而元学习方法可以通过多个会话学习通用知识,这些知识可以快速适应新会话。因此,适合将聚类方法与元学习方法结合来解决冷启动问题。
首先,为每个会话分配聚类,对上面拼接得到的Su经过FC得到查询向量qu,公式如下,其中w为可学习参数,Wq∈R2d×d。
qu=WqSu+bq
然后,通过下式计算软分配概率puk,其中g为每个聚类的中心,K是设置好的超参数,表示聚类数量。
puk=∑k=1Kexp(⟨qu,gk⟩)exp(⟨qu,gk⟩)
最后,会话u的聚类增强表征计算公式如下,其中⋅是惩罚。
Cu=k=1∑Kpuk⋅gk
4.3.2 聚类感知的参数门
由于不同的会话源自不同的分布(表示不同的偏好或爱好),因此使用单个全局共享参数来推荐所有会话是不合理的。因此作者在采用上述两种表征的同时,设计了一个聚类感知参数门来引导全局共享的初始参数为每个会话提供合适的初始参数以实现更好的性能。参数门计算公式如下,其中⊕表示拼接,FCσ表示用sigmoid函数做激活函数的全连接层。
ou=FCσ(Su⊕Cu)
参数变为:
θue←θe,θus←θs,θupre←θpre⋅ou
因此最后的预测为下式:
y^ui=FCθupre(Su⊕Cu)⋅eviT
4.3.3 局部更新
在元学习中,我们的目标是通过基于单个会话的支持集最小化推荐的预测损失来更新每个会话的局部参数。在聚类感知参数门中引导会话的全局共享初始参数后,我们可以在局部更新推荐器参数以最小化会话 𝑢 的预测损失。参数θ∗={θue,θus,θupre}更新方式如下,其中β为学习率,L为支持集上的损失函数。
θ^u∗←θu∗−β⋅∇θu∗Lu(ϕ,θu∗)
4.3.4 全局更新
通过一步梯度下降更新全局参数θ∗={θe,θs,θpre}和ϕ。公式如下,其中损失函数是在查询集上计算的损失,γ为学习率。
θ∗←θ∗−γ∑u∈Ttrain ∇θ∗Lu′(ϕ,θ^u∗)ϕ←ϕ−γ∑u∈Ttrain ∇ϕLu′(ϕ,θ^u∗)
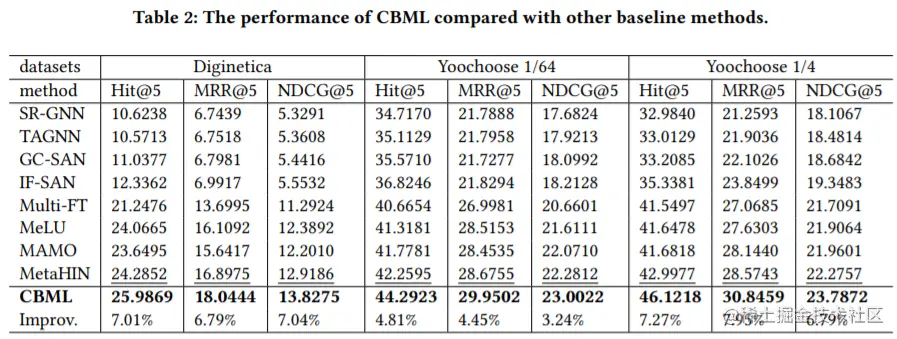
5. 结果