

- 原文地址:Consuming over 1 billion Kafka messages per day at Ifood
- 原文作者:Felipe Volpone
- 译文出自:掘金翻译计划
这是关于我们在用户资料团队如何改进Ifood的架构的系列博客的第二部分。所以,我推荐你先阅读一下第一篇博客。这并不是强制的,但能够帮助你更好地理解前因后果。如果你不想读,我会简单回顾一下。
简单回顾
我们有一个微服务用于存储Ifood用户的元数据(在内部我们叫账户元数据),在峰值时段它的请求量(QPS)能达到两百万每分钟。网页端,手机APP以及一些想要获取顾客信息的内部团队会调用这个系统。所有的数据存储在一个DaynamoDB表中(13亿条数据,大小为7573GB)。
我们存储的是什么样的数据?每一个Ifood的用户的画像数据。下面是一些例子:
- 订单总数
- 最喜欢的三道菜
- 最喜欢的餐厅
- 用户属于哪个等级
下面是整体架构

主要问题
数据团队用于从数据湖中提取数据,使用Databricks和Airflow并最终发送到账户元数据的流水线包含 大量的步骤 并且每一步都有可能失败。我们对每一部分并没有持续做很好的监控,所有经常会出问题,使得整体流程并不可靠。这对于我们用户资料团队来说是一个很大的问题,数据质量始终是我们的核心关注点。
数据问题始终是一个痛点,所以我们开始调研并思考我们该怎么改变着一部分的基础设施。换句话说就是怎么改变每天数亿条记录的采集方式。
救世主:特征仓库
当我们在寻找替代方案,研究怎么替换掉整个数据采集流程时,Ifood内部的ML团队正在构建一个很棒的工具:一个特征仓库(后面简称FS)项目。简而言之,特征仓库让数据供应和分享更简单,用于支持机器学习应用,模型训练和实时预测。FS从数据源一侧(数据湖,数据仓库,Kafka的topics等)读取数据并聚合,进行某种处理或计算,然后将结果到处到另一侧(API,某些数据库,Kafka 的topics等)。
听说了这个项目后,我们清晰的认识到这就是我们需要的东西:中心化的,独特的,标准化的从数据湖中消费数据的方式。即使我们把FS用于跟机器学习没太大关系的地方,它仍然也十分适用。它能大大简化我们的工作,以某种方式将数据导出出来,我们只需要在我们的数据库中进行存储。我们将会把超级复杂又十分脆弱的流水线改成健壮且可靠的机制。在跟特征仓库团队交流过后,我们决定让他们将特征通过Kafka的topic导出给我们。
然而,FS并不支持批量导出特征,这意味着每个Ifood顾客(大约六千万)对每一个特征,都需要生成一条导出消息。那时候我们有大概20个特征但是我们已经在规划将特征增加到30到40个。算下来每天会有60000000*20总共12亿条消息,并且很又可能在几个月内增加到15亿条。
所以,我们应该具有每天消费大概15亿条Kafka消息的能力。
从特征仓库中消费数据
前面提到,FS会将数据导出到一个Kafka topic。我们定义的数据格式是下面这样。
{
account_id: string
feature_name: string
feature_value: string
namespace: string
timestamp: int
}
我们可以创建一个消费者监听指定Kafka topic并将特征存储到DynamoDB的表中。
在Dynamo表中我们使用 account_id 作为分区索引,使用 namespace 作为排序索引。顾名思义,命名空间(namespace)字段将数据依照账户元数据系统将要供应的不同上下文进行划分。
下面是我们的表的结构:
| account_id | namespace | columns and its values… |
| 283a385e-8822–4e6e-a694-eafe62ea3efb | orders | total_orders: 3 | total_orders_lunch: 2 |
| c26d796a-38f9–481f-87eb-283e9254530f | rewards | segmentation: A |
下面是整体的架构
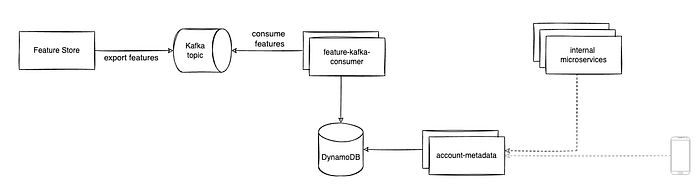
消费者从Kafka topic中读取数据并存储到DynamoDB中。
我们基于Java做了我们的消费者的第一版实现。它表现的很好,但是远远没有达到我们的要求: 每个pod/消费者平均每秒消费4000个特征。我们尝试做了一些调整,测试了不同的配置,但是离15亿的要求仍然很远。
之后我们基于goka——一个用于和Kafka交互的Go语言库开发了又一版Go语言实现。它的性能大大好于之前:每个pod/消费者每秒能消费8500个特征。然而,这仍然远未达到我们的要求。
最后,还是用Go,但基于另一个库sarama,我们实现了每分钟消费一百万条消息(每个pod/消费者每秒消费2万个特征)。每一个pod/消费者创建三个协程来处理从Kafka收到的消息。是的,我们做到了!通过这三次尝试,我们对如何更好的配置Kafka客户端有了一些体会,比如为每批数据设置合适的大小等。
在下图的Grafana图表中,你可以看到随着时间推移被处理的消息的数量(不同的颜色代表不同的命名空间)。
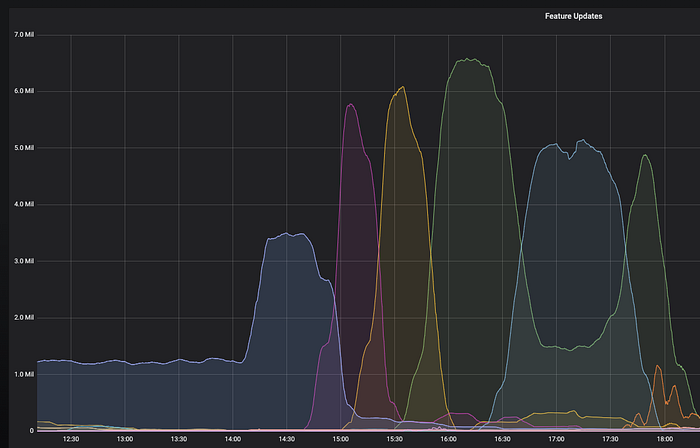
每分钟处理超过一百万个实践会导致对Dynamo的大量写操作。一开始数据库相当吃力,所以我们必须把它扩容到支持每秒5万条写操作。
测试
消费者开发完成后,我们必须确保不会丢失任何的消息,避免出现争用问题,确保数据正常保存。为了测试,我们往命名空间里添加了一个写死的前缀让消费者获取,例如,让orders命名空间的数据
转移到testing-orders命名空间中。我们写了一些脚本来扫描数据库并将两个命名空间的数据进行比较(orders和testing-orders),确保它们完全一致。
性能和功能优化
现在我们完成了第一个版本。它能够正常工作,快速消费事件并准确存储到DynamoDB中。然而,数据库的负载非常高,我们往Dynamo中写数据时是一条消息一写,即使在Kafka的topic中有几条紧挨着的account_id一样的消息,而我们正在使用account_id作为分区索引。
就像下面这样
| account_id | feature_name | feature_value | namespace | timestamp|| user1 | total_orders | 3 | orders | ts1 |
| user1 | total_orders_lunch | 1 | orders | ts3 |
| user1 | segmentation | foo | rewards | ts2 |
| user2 | segmentation | foo | rewards | ts2 |
就可以看到,第一条和第二条记录来自同一个用户,属于同一个命名空间。account_id作为分区索引,同一个account_id的事件会被同一个消费者消费。因此,我们可以在内存中创建某种缓存来聚合消息,将同一个account_id的命名空间相同的消息放到一块并一次性写入DynamoDB。我们就是这样做的。
我们还把Kafka的消费者改成批量从topic中取数据,提升了每次取数据的字节数,这大大提升了吞度量。我们一次性拉取1000条消息,用account_id作为key,对应的特征列表作为value建立映射,每次从map中取account_id对应的列表写入到Dynamo中,而不是每次只获取并处理一条消息。通过这种方式,我们将对Dynamo的写操作降低到了之前的1/4。
在一次只处理一条消息时,有一个重要的细节,将消息标记成“已处理”并提交是很简单的。但一次性处理一千条时,假如在处理这批消息的过程中有一部分消息失败了,将它们标记出来就没有那么简单了。我们必须在编码实现这部分时更加谨慎。
另一个重要的配置是怎么合理为消费者扩容,创建更多pods,因为如果我们没有做好扩容,消费者可能将本来应该花在消费消息的大量时间花在负载均衡上。我们在Kubernetes上配置了自动扩容策略,根据每一个pod的CPU使用来决定何时增加新的pod。因此,一旦有一个pod的CPU占用达到了30%,集群会增加一个pod。我们设定了一个较低的阈值来更快的对pods进行扩容,避免消费者们花费大量时间做负载均衡。
监控
为了监控工作流程,我们花了大量时间来实现对整体流程了良好观察。我们使用Prometheus和Grafana来为消费者建立自定义指标并获取每一个pod的指标,使用Datadog来从Kafka topic中采集指标并建立关于消费者端延迟的数据看板,以及采集集群整体的指标,使用New Relic来采集消费者中产生的错误以及一些额外数据。
一些经验总结
- 我们很难通过第一次尝试就得到最好的结果。记录下好的地方和不好的地方,充分调研寻找可以优化的地方。
- 处理这种量级的数据听起来很唬人,但并不是完全没有办法。它确实需要专注和对细节的关注,但你要相信你完全能做到。
- 在处理这么大量的数据时很难确保不丢失数据,不发生争用等问题。要投入时间来处理这些问题。
- 为了让Kafka消费者更快,我们确实需要使用一些奇淫巧技。我的建议就是仔细阅读官方文档,在配置参数上下功夫。主要的参数有“fetch.min.bytes”,“auto commiting”和“setting mad intervals”.
