原文链接
简介
创意在电子商务中对于产品的展示有着非常重要的作用,卖家通常会为综合展示创造多个创意,因此展示最吸引人的设计来最大化点击率(CTR) 是至关重要的。然而,创意产品推荐比传统产品推荐更容易遭遇冷启动问题,因为用户点击数据更稀缺且创意也可能频繁地更改。在本文中提出了一种优雅的方法,将视觉先验知识整合到bandit model中,它基于一个叫做Neuralllinear 的框架,在汤普森抽样框架中考虑近似贝叶斯神经网络,利用神经网络的学习能力和后验抽样方法。总的来说,文章中:
- 提出一个视觉感知的排名模型(称为VAM),它能够根据视觉外观来评估新创意
- 将学习到的视觉预测作为先验,提出了improved hybrid bandit model(HBM),通过使用更多的观测数据来做出更好的后验估计
- 构造一个新的大型创造性数据集Creativerank,在该数据集和公共Mushroom数据集上进行了大量的实验,证明了该方法的有效性。
预备知识和相关工作
预备知识
问题描述
给定一个产品,目标是确定哪个创意是最有吸引力的。同时,需要估计预测的不确定性,确保在长期内获得最大的累积回报。在在线广告系统中,当一个广告展示给用户一个创意候选时,这个场景被认为是一种印象。
假设有N个商品,定义为{I1,I2,...,In,...,IN},每个商品In由一组创意构成,写作{C1n,...,Cmn,...,CMn}。对于商品In,学习目标是找到创意令:
Cn=c∈{C1n,...,CMn}argmaxCTR(c)
此处的CTR()表示该创意的点击率。
生成CTR的一种方式是累加近期点击数和印象数,并计算其点击率:
CTR^(Cmn)=impression(Cmn)click(Cmn)
click(),impression()表示创意Cmn的点击数和印象数。
这种计算方法存在一个问题:可能缺乏足够的印象数,特别是对一些冷启动的创意。
另一种方法是从历史数据中的上下文数据(例如图像内容等)中学习一个预测函数N(),令:
CTR^(Cmn)=N(Cmn)
N()的输入为Cmn,从历史数据中学习,收集到的顺序数据可以表示为:
D={(C1,y1),...,(Ct,yt),...,(C∣D∣,y∣D∣)}
yt∈{0,1}为便签,表示该创意是否被点击。
数据集构建
文章贡献一个大规模的创造数据集,它由创意图像和序列印象数据组成,可用于评价视觉预测和 exploration-exploitation(E&E)策略。
在2020年7月1日至2020年8月1日期间,从阿里巴巴展示广告平台收集大量多样的创意素材,印象总数约为2.15亿,有500827种产品和1707733个广告创意。
随机的日志策略 在线系统采用随机日志记录策略,随机绘制创意,以收集无偏数据集,Bandit 算法通过交互数据学习策略。
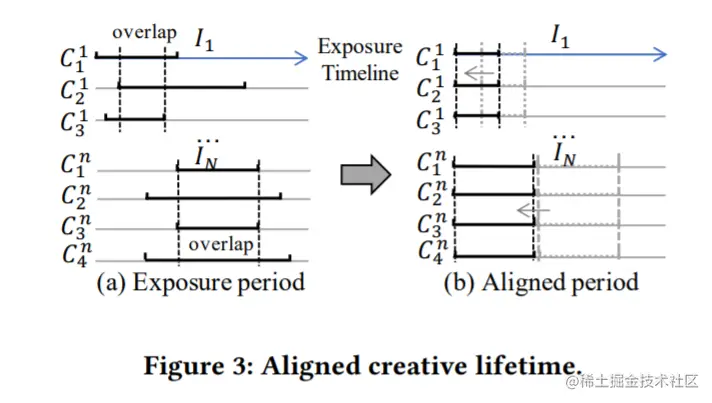
对齐创意生命周期 由于在线环境的复杂性,同样的创意在不同时期的CTRs是不同的,创意会被重新设计或删除,这将导致曝光时间不一致(如图3(a))。为了避免不同时间间隔带来的噪声,只收集候选创意之间的重叠周期(见图3 (b)),重叠时间在5 - 14天,涵盖了从冷启动到相对稳定阶段的创作生命周期。
Train/Validation/Test 数据分割 将500,827个产品随机分为300,242个培训样本、100,240个验证样本和100,345个测试样本,分别包含1,026,378/340,449/340,906个创意样本。
研究内容
设计总览
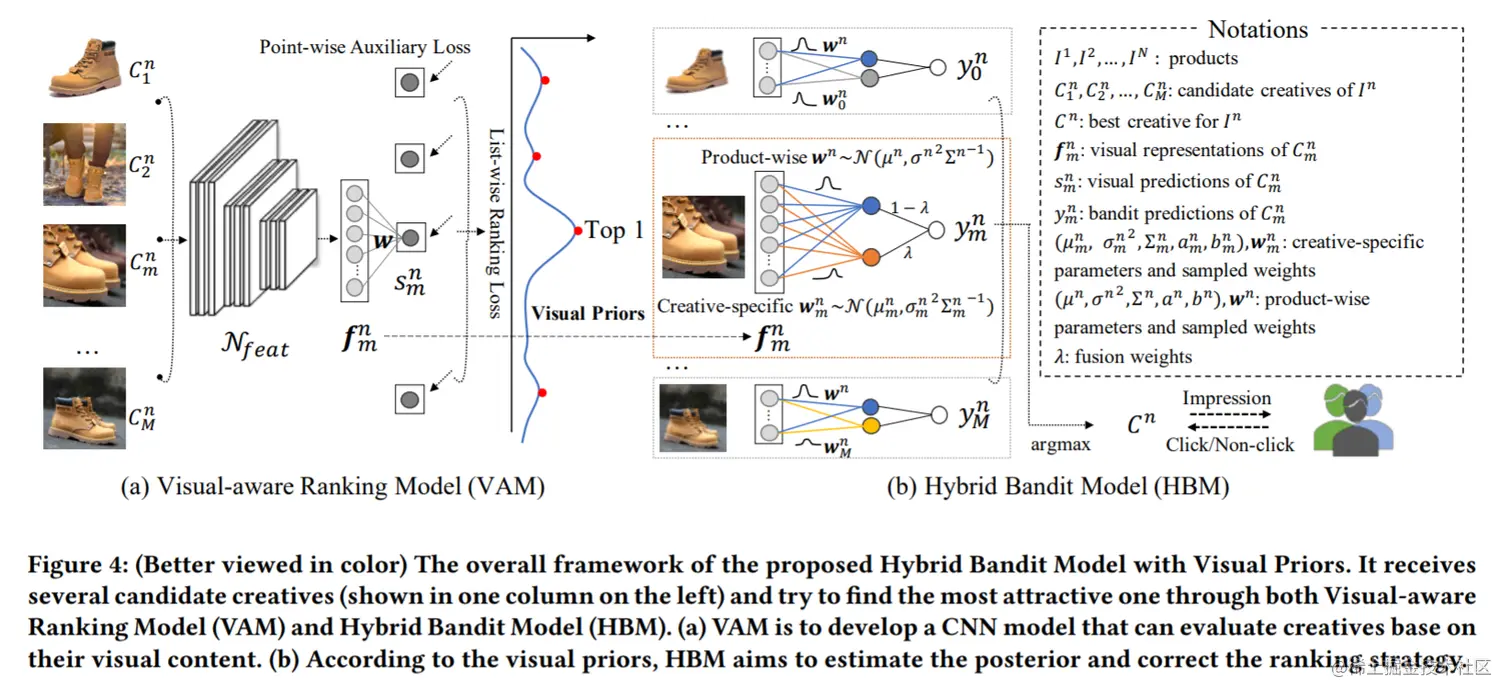
文中提出的具有视觉先验的混合Bandit Model的总体框架如图4所示,在图4(a)中,特征提取网络Nfeat同时输入一个商品的多种创意,并输出d维中间特征{f1n,...,fmn,...,fMn},然后使用一个全连接层来计算其得分{s1n,...,sn+m,...,sMn}。
然后引入基于列表的排名损失(list-wise ranking loss)和辅助回归损失(auxiliary regression loss)来指导学习过程,这样的多目标优化帮助模型不仅关注创意排名,而且考虑到CTR的数值范围,这有利于接下来的Bandit Model。此外,由于数据噪声是现实应用程序中常见的问题,文中提供了几种实用的解决方案来减轻偶然的和恶意的噪声。经过以上步骤,模型可以直接通过其视觉内容来评价创意质量,即使是一个没有任何历史信息的新上传的作品。
之后使用HBM将学习到的fmn合并为上下文信息,并通过与在线观察互动来更新学习策略,如图4(b)所示,混合模型结合了产品预测和创意预测,对于复杂的工业数据更加灵活。
VAM: Visual-aware Ranking Model
对于商品In,使用特征提取网络Nfeat来提取创意的高层视觉表示,使用一个线性层来生成第n个商品的第m个创意的吸引力得分:
fmn=Nfeat(Cmn) smn=fmnTw
此处w表示线性层的学习参数。
基于列表的排名损失
为了学习创造性的相对顺序,需要将预测分数列表和 ground-truth CTRs分别映射到一个排列概率分布(permutation probability distribution),然后将这些分布之间的度量作为损失函数,映射策略和评估指标应该保证分数越高的候选创意排名越高。
排列概率和前k个排名的定义见链接论文。受此启发,文中将创意排在前1位的概率简化为:
pmn=∑i=1Mexp(sin)exp(smn)
基于top-1概率的指数函数既是尺度不变的,也是平移不变的,其对应的标签是:
yrank(Cmn)=∑i=1Mexp(CTR(Cin),T)exp(CTR(Cmn),T)
exp(⋅,T)为一个带温度T的指数函数,由于CTR(Cmn)是一个比较小的分数,因此使用T来调整其尺度令top-1的样本的概率接近于1。
使用交叉熵作为度量,则商品In的损失值为:
Lrankn=−m∑yrank(Cmn)log(pmn)
通过这样的目标函数,模型着重于比较同一产品中的创意,它专注于top-1概率,因为它与真实场景一致,每个印象中只会展示一个创意。
基于点的辅助回归损失
排名损失函数只限制输出的顺序,不限制输出的数值尺度,因此添加了逐点回归(point-wise regression)作为正则化器:
Lregn=m∑∣∣CTR(Cmn)−smn∣∣2
∣∣⋅∣∣表示L2-范数。
最终的损失值由上述两个损失相加而成:
Ln=Lrankn+γLregn
文中γ=0.5。
降低噪声
为避免噪声影响,VAM通过下面两种方式处理数据。
标签平滑(label smoothing):一种经验贝叶斯方法,用于平滑CTR估计值。假设点击数服从二项分布,CTR服从一个先验分布:
click(Cmn)∼binomial(Impression(Cmn),CTR(Cmn)) CTR(Cmn)∼Beta(α,β)
Beta(α,β)为CTRs的先验分布。
在观察到更多的点击后,通过二项分布和先验分布间的共轭性可以获得后验分布及平滑后的CTRCTR^:
CTR^(Cmn)impression(Cmn)+α+βclick(Cmn)+α
其中α,β值可以使用历史数据用最大似然估计法计算。
加权抽样(weighted sampling):一种训练过程的抽样策略。和平等对待每一个样本不一样,加权抽样更关注的是那些印象足够和CTRs更可靠的产品,方法为:
pn=g(impression(In))
其中g()表示取印象的对数,pn表示商品In的抽样权重。
HBM: Hybrid Bandit Model
HBM提供了一种优雅而有效的策略,利用视觉先验并通过混合Bandit 模型更新后验来解决E&E困境,在神经线性框架的基础上,对提取的视觉表示使用贝叶斯线性回归,假设在线反馈数据生成如下:
y=fTw~+ϵ
y表示点击/没有点击的数据,f表示通过VAM提取出的视觉表示,此处需要学习w~的不确定性分布用来帮助提升E&E决策。ϵ是独立的等正态分布的随机变量,即:
ϵ∼N(0,σ2)
根据贝叶斯定理,若w~,σ2的先验分布与数据的似然函数共轭,则其后验概率分布可以被解析推导出来。然后使用后验抽样(也叫Thompson Sampling)来解决E&E困境,通过保持模型的后向性,并根据最优概率选择创意。w~,σ2的先验联合分布建模为:
π(w~,σ2)=π(w~∣σ2)π(σ2) σ2∼IG(a,b) and w~∣σ2∼N(μ,σ2Σ−1)
IG()为一个Inverse Gamma,其超参数设置为a0=b0=η>1。N()为一个高斯分布带默认参数Σ0=λId。其中,μ0被设置为VAM中的学习权重w。
基于一个共轭先验,其在时间t的后验可以计算为:
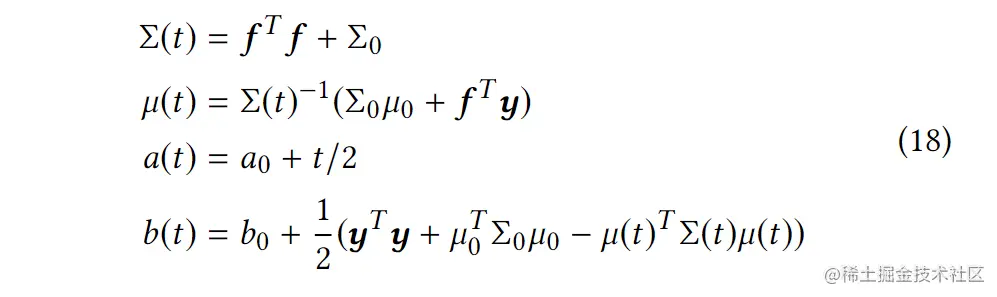
f∈Rt×d为一个包含之前印象上下文特征的矩阵,y∈Rt×1为反馈奖励。在第t个印象处更新上述参数后,得到了不确定性估计下的权重分布。从学习到的分布N(μ(t),σ(t)2Σ(t)−1)中得到w(t),并根据下面的公式选择商品In的最优创意:
Cn=c∈{C1n,...,CMn}argmax(Nfeat(c)))Tw(t)
上面的模型是所有产品的权重分布。这种简单的线性假设适用于小型数据集,但在处理工业数据时就不那么管用了。例如,鲜艳鲜艳的颜色在女性上衣上更有吸引力,而简洁的颜色更适合3C数码配件。除了这个产品方面的特性外,创意可能包含一个独特的设计属性,而这个属性不是通过共享权重来表达的,因此,VAM需要拥有同时包含共享和非共享的权重。
为实现这点,扩展之前的公式结合了产品感知和特定创意的线性项,对于创意Cmn,其线性回归方程可以改写为:
ymn=fmnTwn+fmnTwmn
wn,wmn为产品感知和特定创意的参数,它们被公式18优化。此外,VAM提出了一种融合策略,以自适应地结合这两个项,而不是简单的加法,如下所示:
ymn=(1−λ)fmnTwn+λfmnTwmn
λ=1+exp(θ1−impression(In+θ2)),这是一个sigmoid函数带有调节参数θ1和偏移θ2。
上述过程如算法1所示:

实验
度量方法
Cumulative regret 常用于评估bandit model,其定义为:
Regret=E[r∗−r]
此处r∗为最优策略的累积奖励,例如在特定环境下,总是选择具有最高预期回报的行为的策略。具体来说,VAM为其数据集选择最优的创意并计算 Regret为:
Regret=∑n=1Nimpression(Cn)∑n=1Nclick(Cn)−sCTR
其中sCTR的计算方法如算法2所示:



