1. Java集合类概述
- Java集合类主要是在java.util包中,主要包括两个顶层接口Map和Collection
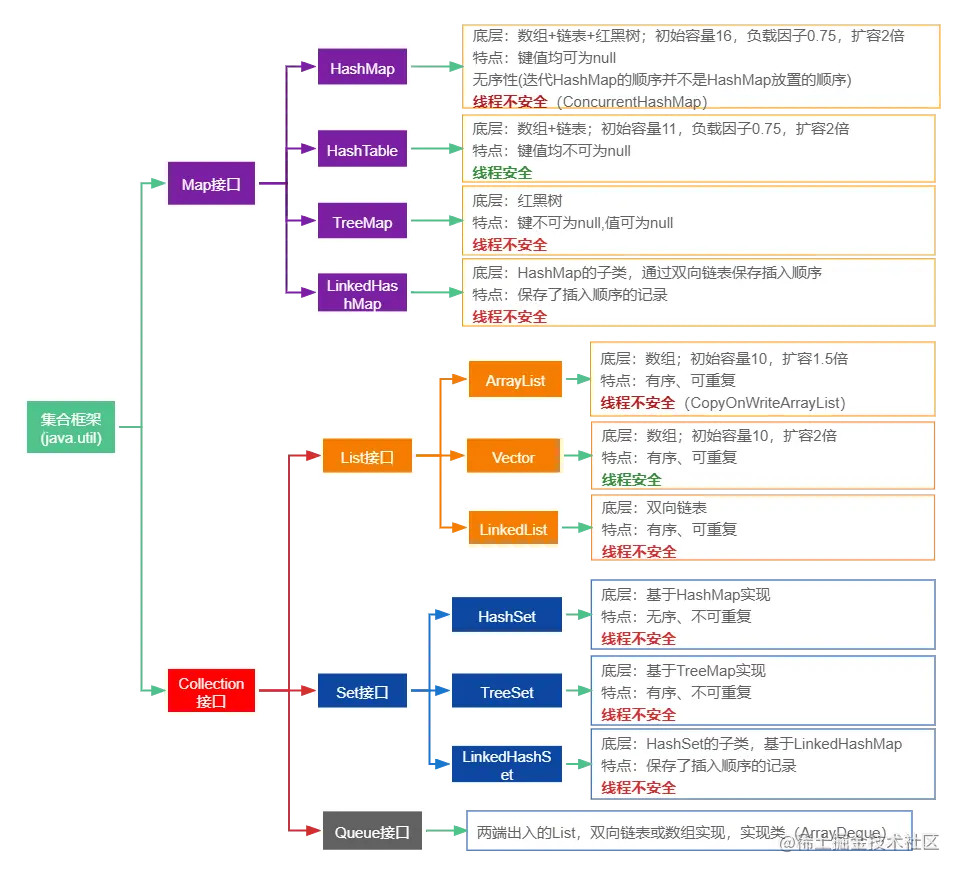
2. Map接口
- Map接口的主要实现类包含HashMap、HashTable、LinkedHashMap以及TreeMap,存储的是key、map键值对类型的数据
2.1 HashMap
- 参考:HashMap源码解析
- 底层数据结构为数组 + 链表 + 红黑树(链表长度大于8)
- 默认初始容量为16,默认加载因子为0.75,每次扩容都是之前的2倍
- 存储的元素key和value均可为null
- 无序性(迭代HashMap的顺序并不是HashMap放置的顺序)
- 线程不安全(多线程可使用基于CAS+synchronized实现的CopyOnWriteArrayList)
2.2 HashTable
- 底层数据结构为数组 + 链表
- 默认初始容量为11,默认加载因子为0.75,每次扩容都是之前的2倍+1
- 存储的元素key和value均不可为null
- 线程安全(put和get等方法都是synchronized方法来实现)
- 提醒:线程安全的HashMap基本都是使用java.util.concurrent包里面的ConcurrentHashMap来实现
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}
2.3 LinkedHashMap
- 原理参考:掘金
- 基本继承HashMap的所有特性
- 继承自HashMap,可以理解为HashMap + 双向链表,双向链表主要用额外的Entry来保存Node存储的顺序
- 主要是重写了newNode和newTreeNode在里面加入linkNodeLast方法实现存储顺序的保存
- HashMap元素的遍历顺序不一定与元素的插入顺序相同(根据数组的index排序),而 LinkedHashMap 则通过遍历双向链表来获取元素,所以遍历顺序在默认条件下等于插入顺序。
- LinkedHashMap可以通过构造参数accessOrder来指定双向链表是否在元素被访问后改变其在双向链表中的位置,accessOrder默认为false表示顺序链表的排序按插入顺序来排列,为true时会受到读取顺序的影响,读取某元素时将其移到链表的尾部
HashMap<String, String> map = new HashMap<>();
map.put("LTP1", "LTP1");
map.put("LTP2", "LTP2");
map.put("LTP3", "LTP3");
map.put("LTP4", "LTP4");
System.out.println(map);
map.forEach((key, value) -> System.out.println("index:" + (hash(key) & 15) + " ~ " + key + ":" + value));
System.out.println("------------------------");
LinkedHashMap<String, String> linkedHashMap = new LinkedHashMap<>(16, 0.75f, true);
linkedHashMap.put("LTP1", "LTP1");
linkedHashMap.put("LTP2", "LTP2");
linkedHashMap.put("LTP3", "LTP3");
linkedHashMap.put("LTP4", "LTP4");
System.out.println(linkedHashMap);
linkedHashMap.get("LTP2");
linkedHashMap.get("LTP4");
System.out.println(linkedHashMap);
运行结果
{LTP3=LTP3, LTP2=LTP2, LTP1=LTP1, LTP4=LTP4}
index:8 ~ LTP3:LTP3
index:9 ~ LTP2:LTP2
index:10 ~ LTP1:LTP1
index:15 ~ LTP4:LTP4
------------------
{LTP1=LTP1, LTP2=LTP2, LTP3=LTP3, LTP4=LTP4}
{LTP1=LTP1, LTP3=LTP3, LTP2=LTP2, LTP4=LTP4}
2.4 TreeMap
- 底层数据结构为红黑树
- 可自定义Comparator排序(构造参数),默认是根据key类型所在类中的compare方法决定
- key不可为null,value可为null
- 线程不安全
TreeMap<Integer, String> treeMap = new TreeMap<>();
treeMap.put(1, "LTP1");
treeMap.put(2, null);
treeMap.put(4, null);
treeMap.put(3, "LTP3");
System.out.println(treeMap);
TreeMap<Integer, String> treeMap2 = new TreeMap<>(new Comparator<Integer>() {
@Override
public int compare(Integer t1, Integer t2) {
return t2 - t1;
}
});
treeMap2.put(1, "LTP1");
treeMap2.put(2, null);
treeMap2.put(4, null);
treeMap2.put(3, "LTP3");
System.out.println(treeMap2);
执行结果:
{1=LTP1, 2=null, 3=LTP3, 4=null}
{4=null, 3=LTP3, 2=null, 1=LTP1}
3. Collection接口
- Collection接口的主要包含List、Set以及Queue三个子接口,存储的是非键值对类型的数据
3.1 List接口
- List接口是Collection接口的子接口,主要包含ArrayList、LinkedList以及Vector
- List接口定义了有序性、可重复性的规则
- 扩容多是利用了System.arraycopy这个native方法
3.1.1 ArrayList
- 底层数据结构是数组
- 默认初始容量为10,每次扩容都会变成之前的1.5倍
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
3.1.2 LinkedList
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
3.1.3 Vector
- 底层数据结构是一个数组
- 默认初始容量为10,扩容量可配置默认扩容2倍
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
- 有序,可重复,可存储null
- 线程安全(put和get等方法都是synchronized方法来实现)
stack类继承自Vector,当然实现栈有很多种方式,包括Stack、LinkedList、ArrayDeque(均提供了push和pop方法),效率高推荐ArrayDeque,讲究线程安全用Stack
3.2 Set接口
- Set接口是Collection接口的子接口,主要包含HashSet、TreeSet以及LinkedHashSet
- Set主要制定了不可重复性的规则
- Set下的实现类基本都是基于Map下的实现类实现的
3.2.1 HashSet
- 基于hashMap实现,只存储key,value均为new Object()
- 基于HashMap存储key的特性,故有以下特性
- 默认初始容量16,扩容倍数为2
- 无序,不可重复,可为null
- 线程不安全
- 注意:提供了一个基于LinkedHashMap的构造器,专门供LinkedHashSet(HashSet的子类)使用
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
3.2.2 TreeSet
- 基于TreeMap实现,只存储key,value均为new Object()
- 基于TreeMap存储key的特性,故有以下特性
- 可自定义Comparator排序(构造参数),默认是根据key类型所在类中的compare方法决定
- 不可存储null
- 线程不安全
3.2.3 LinkedHashSet
- 继承自HashSet,基于HashSet的一个特殊的构造(new LinkedHashMap)实现的
- 本质上是基于LinkedHashMap存储key的特性,故有以下特性
3.3 Queue接口
- 双向出入的队列,可用数组或双向链表实现
- 子接口为Deque,Deque的常见实现类为ArrayDeque
3.3.1 ArrayDeque
- 底层数据结构是一个数组(维护了数组的头和尾指针)
- 默认初始容量是16,容量必须为2^n,每次扩容都是之前的2倍
- 不能存储null,可重复,有序
- 可用于实现高效率的栈
- 注意:JDK11中有较大的变化
4. 常见对比
4.1 HashMap与TreeMap的区别
- HashMap的Key可为null,TreeMap的key不可为null
- HashMap存储元素是根据hash&(capacity-1)获得的index排序,而TreeMap则可以自定义排序(构造中传递自定义的comparator实现类),默认是根据Key所在类中的compare方法排序


