


文 | 某某白米饭\
来源:Python 技术「ID: pythonall」

在京东上完成订单的评价都会返还一些京豆当钱用。小编也是一个懒人,不喜欢拍照和评价任何商品,半年都没有去评价任务的商品了。一个个评价太麻烦了,就写了一个 python 脚本自动完成。\

取 cookie
首先就是要在脚本上登录京东,这里用的是把在浏览器登录的京东账号取到 cookie 后复制到 header 上。

# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import time
import json
headers = {
'cookie': '自己 cookie',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
}
获取所有评价数量
在京东的评价页面一共有 4 种评价,待评价订单、待晒单待、追评和服务评价,每个评价后面会跟上数字,表示还有多少个评价没写。

使用 BeautifulSoup 抓取这些内容用于判断是否有需要填写的评价。最终把抓取的数据放到字典中。后面用这个数字做分页基础。
def all_appraisal():
appraisal = {}
url = "https://club.jd.com/myJdcomments/myJdcomment.action?sort=0"
req = requests.get(url, headers=headers)
soup = BeautifulSoup(req.text, "html.parser")
url = soup.find('ul', class_='tab-trigger');
for li in url.find_all('li'):
contents = li.a.text
b = li.b
if b != None:
appraisal[contents] = b.text
return appraisal
示例结果:
{'待评价订单': '17', '待晒单': '1', '待追评': '68', '服务评价': '27'}
待评价订单
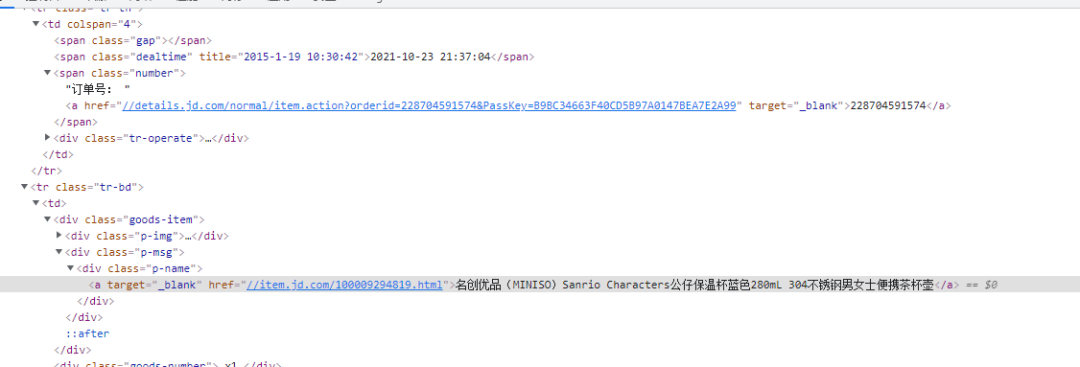
在控制面板的网络中,找到提交评价的 url 地址(club.jd.com/myJdcomment… post 参数有:订单号,商品号,提交内容和星星数。这里先不发图片评价,在后面的晒图评价中一起做。

通过获取 class_ = 'td-void order-tb' 的 table 获取到每行的订单信息,从而解析到订单号、商品号和商品名称,提交内容就在网上搜一套万能的商品评价模板,星星数都是 5 个。
def be_evaluated():
appraisal = all_appraisal()
for i in range((appraisal['待评价订单'] // 20) + 1):
url = 'https://club.jd.com/myJdcomments/myJdcomment.action?sort=0&page={}'.format(i + 1)
req = requests.get(url, headers=headers)
soup = BeautifulSoup(req.text, "html.parser")
table = soup.find('table', class_ = 'td-void order-tb');
tbodys = table.find_all('tbody')
for order in tbodys:
oid = order.find('span', class_="number").a.text
product = order.find('div', class_='p-name').a
pname = product.text
pid=product['href'].replace('//item.jd.com/', '').replace('.html', '')
content = pname + ',东西质量非常好,与卖家描述的完全一致,非常满意,真的很喜欢,完全超出期望值,发货速度非常快,包装非常仔细、严实,物流公司服务态度很好,运送速度很快,很满意的一次购物'
saveProductComment_url = "https://club.jd.com/myJdcomments/saveProductComment.action"
saveProductComment_data = {
'orderId': oid,
'productId': pid,
'score': '5',
'content': bytes(content, encoding="gbk"),
'saveStatus': '1',
'anonymousFlag': '1'
}
save = requests.post(saveProductComment_url, headers=headers, data=saveProductComment_data)
time.sleep(5)
待晒单
待晒单页面中的订单信息在 class="comt-plists" 的 div 中,每一个订单都是一个个 class="comt-plist" 的 div。用 bs4 很容易就获取到了。
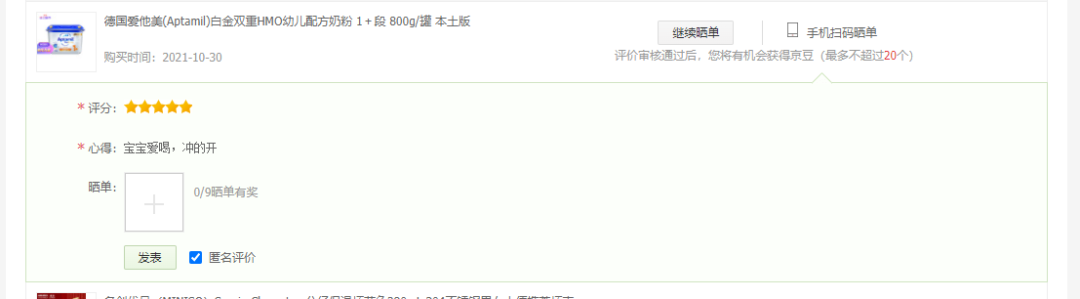
作为一个 python 脚本,怎么可能需要自己拍商品图呢?这里(club.jd.com/discussion/… json 串。解析后得到第一个 imageUrl。
def be_shown_img():
url = 'https://club.jd.com/myJdcomments/myJdcomment.action?sort=1'
req = requests.get(url, headers=headers)
soup = BeautifulSoup(req.text, "html.parser")
pro_info = soup.find_all('div', class_ = 'pro-info');
for plist in pro_info:
oid = plist['oid']
pid = plist['pid']
img_url = 'https://club.jd.com/discussion/getProductPageImageCommentList.action?productId={}'.format(pid)
img_req = requests.get(img_url, headers=headers)
text = img_req.text
print(img_url)
result = json.loads(text)
imgurl = result["imgComments"]["imgList"][0]["imageUrl"]
saveUrl = 'https://club.jd.com/myJdcomments/saveShowOrder.action'
img_data = {
'orderId': oid,
'productId': pid,
'imgs': imgurl,
'saveStatus': 3
}
print(img_data)
headers['Referer'] = 'https://club.jd.com/myJdcomments/myJdcomment.action?sort=1'
headers['Origin'] = 'https://club.jd.com'
headers['Content-Type'] = 'application/x-www-form-urlencoded'
requests.post(saveUrl, data=img_data, headers=headers)
time.sleep(5)
待追评
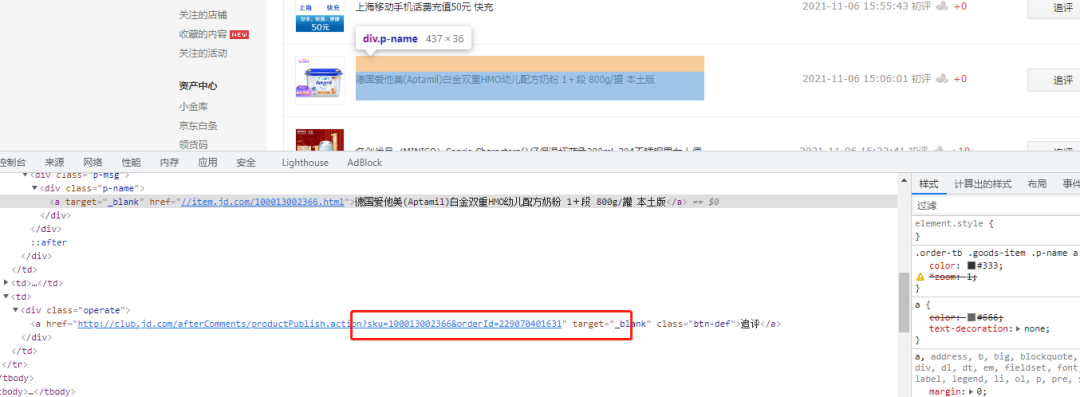
追评和评价差不多,不需要上传图片,post 参数只要取得订单号和商品号就可以了。

追评似乎没有特别的标签可以获取订单号和商品号,只能在追评按钮的 href 中截取。
def review():
appraisal = all_appraisal()
saveUrl = 'https://club.jd.com/afterComments/saveAfterCommentAndShowOrder.action'
for i in range((appraisal['待评价订单'] // 20) + 1):
url = 'https://club.jd.com/myJdcomments/myJdcomment.action?sort=3&page={}'.format(i+1)
req = requests.get(url, headers=headers)
soup = BeautifulSoup(req.text, "html.parser")
operates = soup.find_all('div', class_='operate')
for o in operates:
href = o.a['href']
infos = href.replace('http://club.jd.com/afterComments/productPublish.action?sku=','').split('&orderId=');
pid = infos[0]
oid = infos[1]
data = {
'orderId': oid,
'productId': pid,
'content': bytes('宝贝和想象中差不多所以好评啦,对比了很多家才选择了这款,还是不错的,很NICE!真的', encoding='gbk'),
'imgs': '',
'anonymousFlag': 1,
'score': 5
}
requests.post(saveUrl, headers=headers, data=data)
time.sleep(5)
服务评价
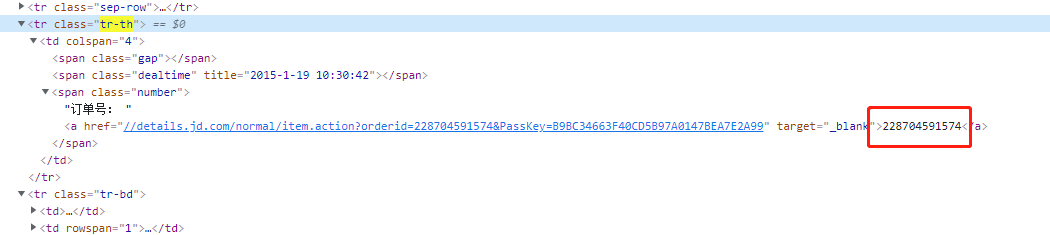
服务评价的提交很简单,参数只要一个订单号就可以了,只需解析下图的 html。
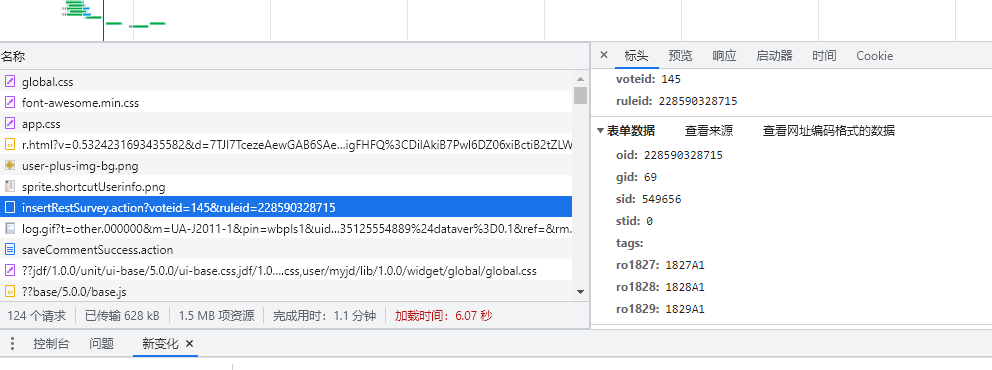
其他的参数都可以被写死,快递包装的 5 颗星得分的数值:1827A1,送货速度是:1828A1,配送员服务的数值是:1829A1。
def service_rating():
appraisal = all_appraisal()
saveUrl = 'https://club.jd.com/myJdcomments/insertRestSurvey.action?voteid=145&ruleid={}'
for i in range((appraisal['服务评价'] // 20) + 1):
url = "https://club.jd.com/myJdcomments/myJdcomment.action?sort=4&page={}".format(i + 1)
req = requests.get(url, headers=headers)
soup = BeautifulSoup(req.text, "html.parser")
trs = soup.find_all('tr', class_='tr-th');
for tr in trs:
oid = tr.find('span', class_='number').a.text
saveUrl = saveUrl.format(oid)
data = {
'oid': oid,
'gid': 69,
'sid': 549656,
'stid': 0,
'tags': '',
'ro1827': '1827A1',
'ro1828': '1828A1',
'ro1829': '1829A1',
}
requests.post(saveUrl, headers=headers, data=data)
print('订单号:' + oid + '服务评价完成')
time.sleep(5)
总结
京东的商品评价脚本比较容易,只用到了 requests 和 bs4 第三方模块,也没有什么加密解密的东西。非常适合刚学爬虫的小伙伴用来练手。
PS: 公号内回复「Python」即可进入Python 新手学习交流群,一起 100 天计划!
老规矩,兄弟们还记得么,右下角的 “在看” 点一下,如果感觉文章内容不错的话,记得分享朋友圈让更多的人知道!

【代码获取方式****】
识别文末二维码,回复:某某白米饭

