

1.5 区块链的神话与误解
1.6 比特币:人类首次区块链大规模社会实验
2.1 比特币的前世今生
2.2 钱包、私钥、签名与交易
你所拥有的比特币实际上是一系列交易输出的集合
以下这个图中有疑问,回过头来还要重新看
2.3 非对称加密如何避免记假账
TODO 了解 非对称算法 用于签名的过程 以 搞明白 为何 "私钥签名 公钥验签" 而不是反过来
非对称算法 用于加解密 是清楚的, "私钥加密,公钥解密", 但能反过来吗?
假如反过来 即 "公钥加密,私钥解密" 在数学上也是可以正常完成加解密的,但是 为啥不能反过来呢? 通常是因为 反过来 不安全,即 从 私钥 可以计算出 公钥。
所以由此可知, 非对称算法中 的 两把密钥A和B,
如果已知A可以算得B 而已知B不能或很难算得A,即 A是源头 而B是由A产生的,
即 出于安全考虑 源头A 用作 私钥 , 而 源头A的生成物B 用作公钥。
备注 "已知B很难算得A" 中的 "很难" 是指 以当前的晶体管计算机 所需计算时间 为 天文时间长度。
但不是很清楚, 非对称算法 用于签名 的过程, 所以需要到密码学教程中搞清楚 非对称算法 用于 签名 的 过程。
TODO 还有一些图没贴,需要回过头来再看
2.4 哈希运算与神奇的难以篡改
TODO 还有一些图没贴,需要回过头来再看
Merkle树
链 中 哪有 树?
这里的树应该是指 :
本交易 作为 树根,
本交易的输入们 对应的交易 作为 直接孩子,
即 以 交易k1的输入 对应的 交易k2 这样的推进关系 往下演进,分别得到树中 树根的 直接孩子k1们,
k1的直接孩子k2们,
k2的直接孩子k3们, ... ,
直到某笔交易是挖矿所得。
总结一下 , 区块链中的 Merkle树 是指,
某交易为树根 ,
该交易的输入 以及更远的输入 为 中间节点,
挖矿交易 是 叶子节点 (挖矿交易 是 该交易最远的输入 )
2.5 双花问题和UTXO的精妙
UTXO尚未使用的交易输出 机制
"矿工会从以前的区块链中追溯",这里的 "追溯" 显然是在 Merkle树 (交易的摘要树) 上进行的
没有比特币,只有UTXO
2.6 共识算法和工作量证明机制
2.8 总结
注意一个根本问题, 有私钥的一方 实际上是 同时有私钥和公钥,因为公钥是可以从私钥计算出来的。 所以即使公钥、私钥颠倒使用后,数学上的加解密是成立的 ,, 但是显然逻辑上已经不安全了。
"私钥签名,公钥验签" 是安全的,若公钥、私钥颠倒使用则不安全
持有私钥的一方 常常是自己, 自己再将公钥公布出去,其他人都知道自己的公钥。
自己持有私钥, 意思是 自己持有 私钥和公钥, 那么 自己 既能签名 也能验签。
其他人持有公钥,而公钥不能反推出私钥, 所以其他人持有公钥, 意思是 其他人只持有公钥 且 没有私钥, 所以其他人只能验签 而不能产生签名。
因此 "私钥签名,公钥验签" 是安全的。
反过来 "公钥签名,私钥验签" 是不安全的。
"私钥解密,公钥加密" 是安全的,若公钥、私钥颠倒使用则不安全
同上,不再赘述
简单点说就是,
持有私钥 等于 持有私钥和公钥 ,
而 持有公钥 等于 持有公钥 且 不持有私钥;所以 私钥的权利是大于公钥的, 要保护什么动作,就让什么动作使用私钥。
解密和加密,显然是应该要保护解密 , 所以用权力大的私钥 来 解密。
签名和验签,显然是应该要保护签名, 所以用权力大的私钥 来 签名。
要保护的,也可以说是重要的
解密和加密, 解密更重要, 所以权力大的私钥 用于 解密。
签名和验签, 签名更重要, 所以权力大的私钥 用于 签名。
Merkle树原来 只是硬性的 将 一个区块中的交易列表 以 散列值树 的形式组织起来
Merkle树如下:
算力
按理说以下三种指标都可以表达算力, 且这三个指标依次更苛刻
- 算hash值的能力: 每秒可以算多少次hash运算
hash碰撞: 两次不同输入对应的hash值相同
- 在随机算hash值的过程中, 每秒可以出现多少个hash碰撞 : 每秒碰撞次数
符合要求的hash碰撞: 比如hash值前xx位为0
- 在随机算hash值的过程中, 每秒产生了若干次的hash碰撞,在这些hash碰撞中,有没有一个碰撞是符合要求的 :多少分钟产生一个符合要求的hash值
3.3 共识协议paxos
1. Proposer提案者 : 类比 mysql 的客户端
1.1 Proposer提案者 提出的 value值: 类比 msql客户端 发出的一条sql语句
2. Acceptor批准者: 类比 mysql的可读可写服务器
3. Learner学习者: 类比 mysql的只读服务器
角色如下图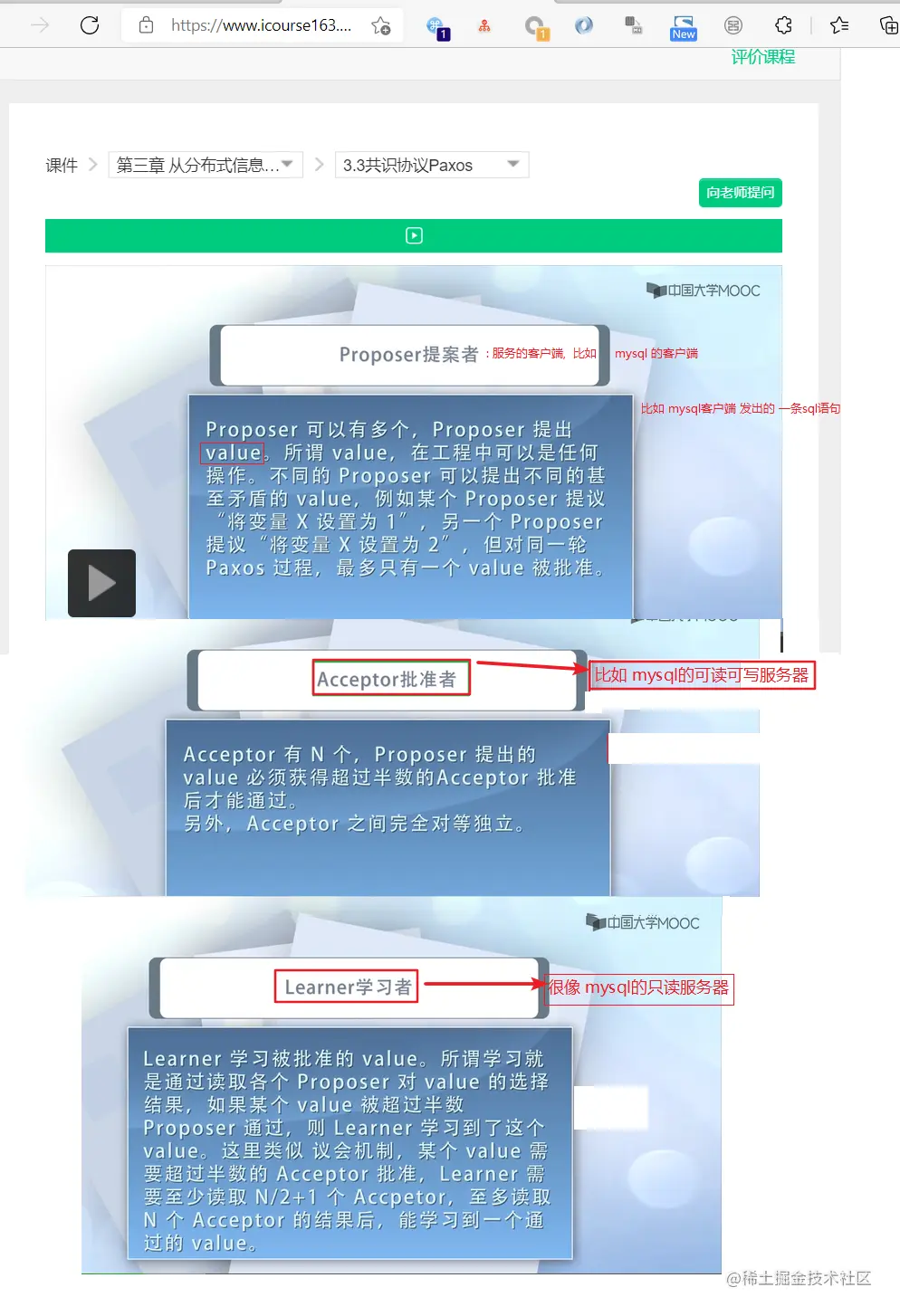
paxos 过程
约束条件
Proposer与Acceptor之间的交互主要有4类消息通信,如下图:
Phase 1准备阶段
a) proposer向网络内超过半数的acceptor发送prepare消息
b) acceptor正常情况下回复promise消息
Phase 2批准阶段
a) 在有足够多acceptor回复promise消息时,proposer发送accept消息
b) 正常情况下acceptor回复accepted消息
选举过程
选举分为两个阶段,如下图所示。
Phase1 准备阶段
P1a:Proposer 发送 Prepare请求
Proposer 生成全局唯一且递增的ProposalID,向 Paxos 集群的所有机器发送 Prepare请求,这里不携带value,只携带 ProposalID 。
P1b:Acceptor 应答 Prepare
Acceptor 收到 Prepare请求后, 判断:收到的ProposalID 是否比之前已响应的所有提案的ProposalID大, 如果是,则:
- 在本地持久化 ProposalID,可记为Max_ProposalID。
- 回复请求,并带上 已Accept的提案中 ProposalID 最大的 value(若此时还没有已Accept的提案,则返回value为空)。
- 做出承诺:不会Accept 任何 小于 Max_ProposalID的提案。
如果否:不回复或者回复Error
Phase2 选举阶段
P2a:Proposer 发送 Accept
经过一段时间后,Proposer 收集到一些 Prepare 回复,有下列几种情况:
- 回复数量 > 一半的Acceptor数量,且所有的回复的value都为空,则Porposer发出accept请求,并带上自己指定的value。
- 回复数量 > 一半的Acceptor数量,且有的回复value不为空,则Porposer发出accept请求,并带上回复中ProposalID最大的value(作为自己的提案内容)。
- 回复数量 <= 一半的Acceptor数量,则尝试更新生成更大的ProposalID,再转P1a执行。
P2b:Acceptor应答accept
Accpetor 收到 Accpet请求 后,判断:
- 收到的N >= Max_N (一般情况下是 等于),则回复提交成功,并持久化N和value。
- 收到的N < Max_N,则不回复或者回复提交失败。
P2c:Proposer 统计投票
经过一段时间后,Proposer 收集到一些 Accept 回复提交成功,有几种情况:
- 回复数量 > 一半的Acceptor数量,则表示提交value成功。此时,可以发一个广播给所有Proposer、Learner,通知它们已commit的value。
- 回复数量 <= 一半的Acceptor数量,则尝试更新生成更大的 ProposalID,再转P1a执行。
- 收到一条提交失败的回复,则尝试更新生成更大的 ProposalID,再转P1a执行。
Paxos算法的核心思想
- 引入了 多个Acceptor,避免单个Acceptor成为单点。 Proposer用更大ProposalID来抢占临时的访问权,避免其中一个Proposer崩溃宕机导致死锁。
- 保证一个ProposalID,只有一个Proposer能进行到第二阶段运行,Proposer按照ProposalID递增的顺序依次运行。
- 新ProposalID 的proposer 采用后者认同前者的思路运行。 在肯定旧ProposalID 还没有生成确定的value (Acceptor提交成功一个value)时,新ProposalID 会提交自己的value,不会冲突。 一旦旧ProposalID 生成了确定的value,新ProposalID 肯定可以获取到此值,并且认同此值。
paxos 过程(文字描述, 用通俗术语)
更换术语说明
- Proposer 换成 客户端Client
- Acceptor 换成 可读可写服务器RwServer
paxos总图 和前一节此位置的图一样的
约束条件
Client与RwServer之间的交互主要有4类消息通信,如下图:
Phase 1准备阶段
a) Client向网络内超过半数的RwServer发送prepare消息
b) RwServer正常情况下回复promise消息
Phase 2批准阶段
a) 在有足够多RwServer回复promise消息时,Client发送accept消息
b) 正常情况下RwServer回复accepted消息
选举过程
选举分为两个阶段,如下图所示。
Phase1 准备阶段
P1a:Client 发送 Prepare请求
Client 生成全局唯一且递增的ProposalID,向 Paxos 集群的所有机器发送 Prepare请求,这里不携带value,只携带 ProposalID 。
P1b:RwServer 应答 Prepare
RwServer 收到 Prepare请求后, 判断:收到的ProposalID 是否比之前已响应的所有提案的ProposalID大, 如果是,则:
- 在本地持久化 ProposalID,可记为Max_ProposalID。
- 回复请求,并带上 已Accept的提案中 ProposalID 最大的 value(若此时还没有已Accept的提案,则返回value为空)。
- 做出承诺:不会Accept 任何 小于 Max_ProposalID的提案。
如果否:不回复或者回复Error
Phase2 选举阶段
P2a:Client 发送 Accept
经过一段时间后,Client 收集到一些 Prepare 回复,有下列几种情况:
- 回复数量 > 一半的RwServer数量,且所有的回复的value都为空,则Porposer发出accept请求,并带上自己指定的value。
- 回复数量 > 一半的RwServer数量,且有的回复value不为空,则Porposer发出accept请求,并带上回复中ProposalID最大的value(作为自己的提案内容)。
- 回复数量 <= 一半的RwServer数量,则尝试更新生成更大的ProposalID,再转P1a执行。
P2b:RwServer应答accept
Accpetor 收到 Accpet请求 后,判断:
- 收到的N >= Max_N (一般情况下是 等于),则回复提交成功,并持久化N和value。
- 收到的N < Max_N,则不回复或者回复提交失败。
P2c:Client 统计投票
经过一段时间后,Client 收集到一些 Accept 回复提交成功,有几种情况:
- 回复数量 > 一半的RwServer数量,则表示提交value成功。此时,可以发一个广播给所有Client、Learner,通知它们已commit的value。
- 回复数量 <= 一半的RwServer数量,则尝试更新生成更大的 ProposalID,再转P1a执行。
- 收到一条提交失败的回复,则尝试更新生成更大的 ProposalID,再转P1a执行。
Paxos算法的核心思想
- 引入了 多个RwServer,避免单个RwServer成为单点。 Client用更大ProposalID来抢占临时的访问权,避免其中一个Client崩溃宕机导致死锁。
- 保证一个ProposalID,只有一个Client能进行到第二阶段运行,Client按照ProposalID递增的顺序依次运行。
- 新ProposalID 的Client 采用后者认同前者的思路运行。 在肯定旧ProposalID 还没有生成确定的value (RwServer提交成功一个value)时,新ProposalID 会提交自己的value,不会冲突。 一旦旧ProposalID 生成了确定的value,新ProposalID 肯定可以获取到此值,并且认同此值。
3.5 拜占庭容错算法
TODO 图没贴完 ,看完回头再补
实用拜占庭容错算法PBFT 与 raft
PBFT 比 raft 多一步、改一步
raft中 谁发起 谁收集响应 , 并对响应实施多数派判定
PBFT中
某节点发起后,
收到的节点 并不相信该发起者 ,收到的节点 将自己收到的内容 复制给 其他节点,
如此一来 收到的节点 集齐了 全部节点的观点 ,
因此 收到的节点 可以对 再收到的全部节点的观点 实施多数派判定
注: 发起的内容 被再次传播到 某个接收方 ,该接收方收到的内容 称为 "观点";
此 "观点" 不一定是 原始内容,但一定可以代表 传播者的意图,因此称为 "观点"
PBFT 与 raft 比较 总结一下
raft 发起方与其他节点进行一次交互后,发起方 实施多数派 判定。
pbft 发起方与其他节点进行一次交互后, 其他节点之间进行一次互传观点,其他节点自身各自 实施多数派判定。其他节点之间之所以再进行一次交互,是因为发起者也不可以相信。
pbft 比 raft 多一步
多的一步是 pbft中其他节点之间要再进行一次交互
pbft 比 raft 改一步
raft 实施多数派判定 发生在 发起者中,因为 raft中所有节点都是诚实可信 不作恶的。
pbft 实施多数派判定 不是发生在 发起者中,而是发生在 其他节点 中。
可见raft只实施了一次多数派, 而pbft实施了 集群节点数个 多数派判定。
